
いちばんやさしいローカル LLM

概要
ローカル LLM 初めましての方でも動かせるチュートリアル
最近の公開されている大規模言語モデルの性能向上がすごい
Ollama を使えば簡単に LLM をローカル環境で動かせる
Enchanted や Open WebUI を使えばローカル LLM を ChatGPT を使う感覚で使うことができる
quantkit を使えば簡単に LLM を量子化でき、ローカルでも実行可能なサイズに小さくできる
1. はじめに
大規模言語モデル(LLM)の数は数年前と比べてたくさん増えました。有名な LLM を使ったチャットサービスとして、OpenAI の ChatGPT や Anthropic の Claude、Google の Gemini などがありますが、これらのサービスの中で利用されている大規模言語モデルは公開されていません。
現状、様々な評価指標により LLM の性能が測定されていますが、ここ一ヶ月の間に公開された LLM の性能が既存の最高性能の非公開のモデルに一部匹敵するとまで言われています。たとえば、Cohere 社の Command R+ や Microsoft の WizardLM 2(4/20 現在非公開)、Meta 社の Llama 3 70B などがあります。
これらの LLM は、現状ローカル環境で実行するにはなかなかしんどいスペック(≒お金)を求められますが、近い将来 LLM の推論が高速化、最適化された未来ではあたりまえに日常に溶け込んでいるのかもしれません。
本 note は、Ollama という初心者の方でも比較的失敗しにくい LLM 推論アプリケーションを用いて、ローカル環境で LLM を実行するまでを取り扱います。途中、少し難しい用語などあるかもしれませんが、完璧に理解する必要はありませんので最後まで読んで(できれば実行して)いただけると嬉しいです。
2. 公開されている LLM を自分で動かしてみよう
Ollama をダウンロードしよう
Ollama というローカル環境で LLM を動かすことに特化したライブラリを使いましょう。こちらのリンクからご自身の OS に合う Ollama をダウンロードしてください。
私のパソコンが M2 Mac ですので、以下は Mac の手順となりますが、Window や Linux でも基本的に同じように進められるはずです。また、GPU のないパソコンであれば動きはするもののかなり文章生成に時間がかかるため GPU
ありで実行することを推奨します。もしつまずいたら下の欄からコメントいただければと思います。答えられる範囲で答えさせていただきます。


ダウンロードした zip ファイルを解凍し、Ollama を開いてください。もし、アプリケーションとして今後も使いたい方は、ご自身のアプリケーションフォルダに Ollama.app を移動してください。

Ollama を開くとひょっこり Ollama のアイコンが現れます。アプリのような UI がある訳ではないのでご注意ください。
Terminal を使って Ollama を実行してみよう

Spotlight から Terminal.app を開いてください。もし見つからなければ Mac の画面の上の方のメニューバーにある「🔍」アイコンを押してください。Terminal と検索し、エンターを押すと Terminal.app が開きます。

まずは Ollama が入っているかどうかを確認しましょう。
ollama --versionバージョンが表示されていればよし。そうでなければ Ollama が起動していないので、アプリケーションを開き直してください。

ollama run llama3上記のコマンドをコピペして実行してください。上記は実行コマンドですが、初回のみダウンロードが始まります。Wi-Fi 回線の速度にもよりますが、目安は 5 分程度を見ておいてください。大規模言語モデルと名のつくように比較的小さいモデル(7B 程度)であっても数 GB ほどの空き容量が必要です。

Send a message のところに ChatGPT のようにプロンプト(文章)を入力してエンターを押してみてください。

日本語で聞いても英語で答えることがあります。会話を止めたい場合は「Ctrl + d」を押すか、「/bye」で止めることができます。「/?」と打つと使えるコマンドの一覧を表示することができます。

いかがでしょう。動きましたか?ここまでできたら上出来です。
小さめのモデルを動かしてみよう
パソコンのスペックが足りない時はもっと小さなモデルを使ってみましょう。
Ollama に標準で対応しているモデルは上記のリンクから見ることができます。たとえば、Google の LLM である Gemma の 2B は先ほどの Llama 3(8B)より軽いモデルなので動くかもしれません。
ollama run gemma:2b「:2b」を除くとデフォルトで 7B のモデルがダウンロードされるため、2B を試したい時は抜かないように注意。
上記の Ollama Library に Command R+ や Mixtral 8x22b など有名どころの性能の高い LLM もあるので、スペックの高いパソコンをお持ちの方は動かしてみてください。
発展的な内容ですが、 Ollama に対応していないモデルを使いたい場合は以前書いた下記の note を参考に、Ollama で使える形に変換してください。
Hugging Face で公開されている LLM の多くは Ollama で動作するはずです(VLM も)。独自 tokenizer を使うモデルや transformer alternatives は動かないと思います。issue はあがっているよう。
3. ChatGPT のような UI で LLM を使ってみよう
Enchanted を使って Ollama を動かしてみよう
2 章では Ollama を使って Terminal で LLM を動かしました。デモクロイガメンチョットコワイ。そこで 3 章では Enchanted というアプリを使って ChatGPT のように対話できるようにしましょう。
Enchanted は現状 Mac / iPhone / iPad 対応のアプリです。もし Windows や Linux をお使いの方は Open WebUI がおすすめです。Enchanted を紹介し、動作確認した後に Open WebUI についても触れます。
ollama serveOllama を起動しておくために上記のコマンドを Terminal にて打ってください。「Error: listen tcp 127.0.0.1:11434: bind: address already in use」とエラーが出ても大丈夫です。
Enchanted を開きましょう。
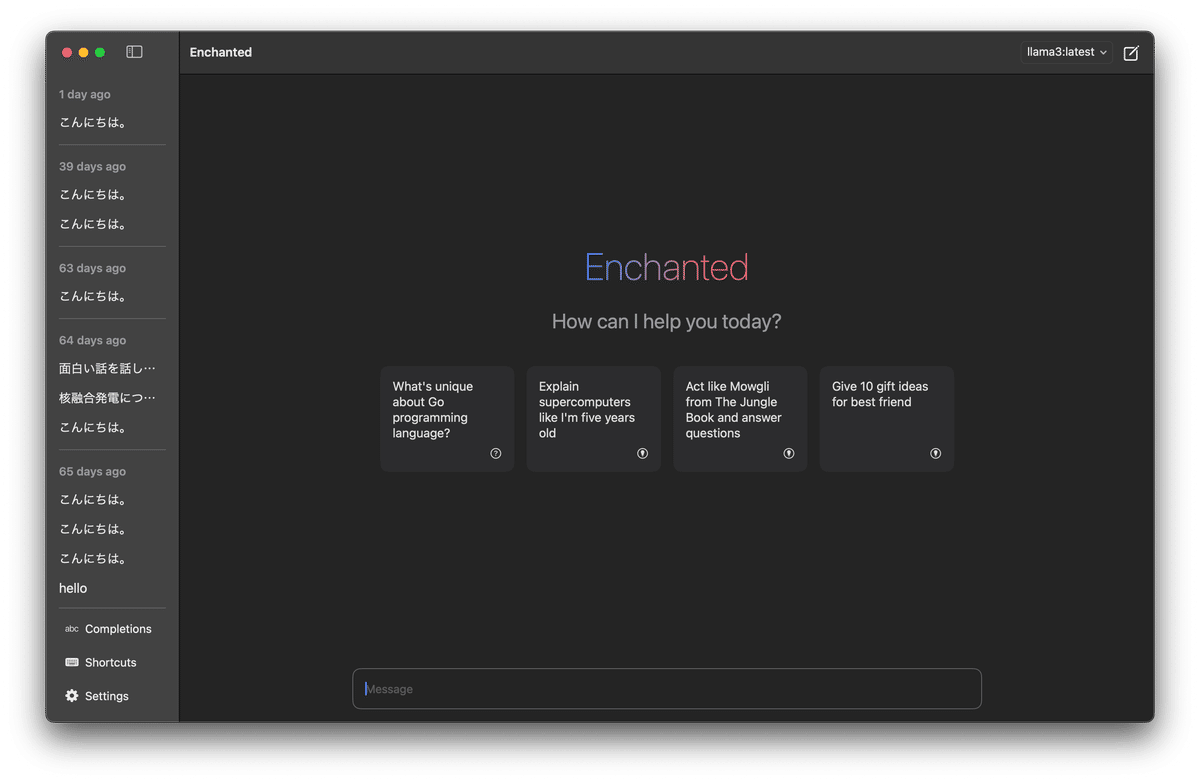
上記の画像では右上にモデルの名前が記載されています。モデルの変更は右上から行ないます。もし 2 章にて Llama 3 8B と Gemma 2B をダウンロードしていれば、そのふたつが表示されるはず。
左下の Settings から Ollama server URI を設定してください。設定したら Save を押してください。
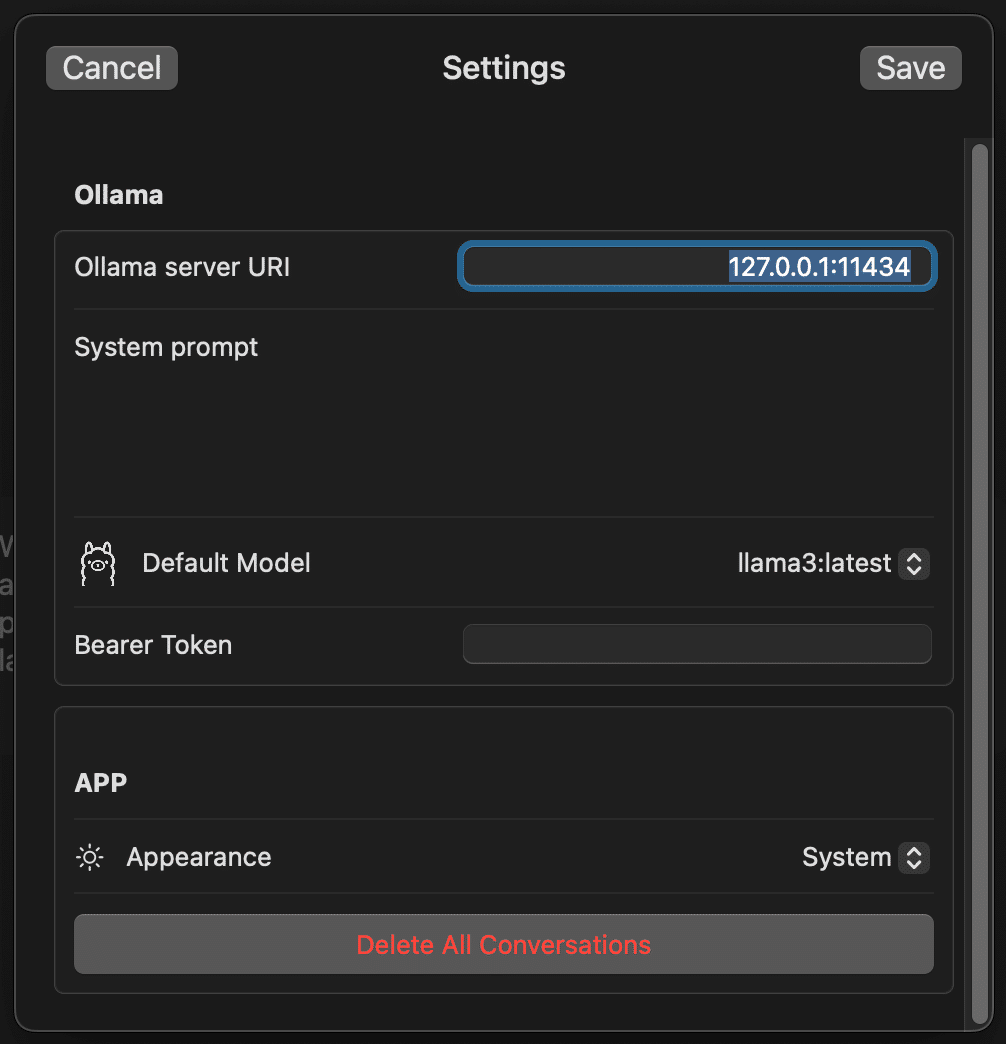
127.0.0.1:11434127.0.0.1 は localhost です。11434 は Ollama のデフォルトポート番号です。よくわからない方は気にされなくて構いません。

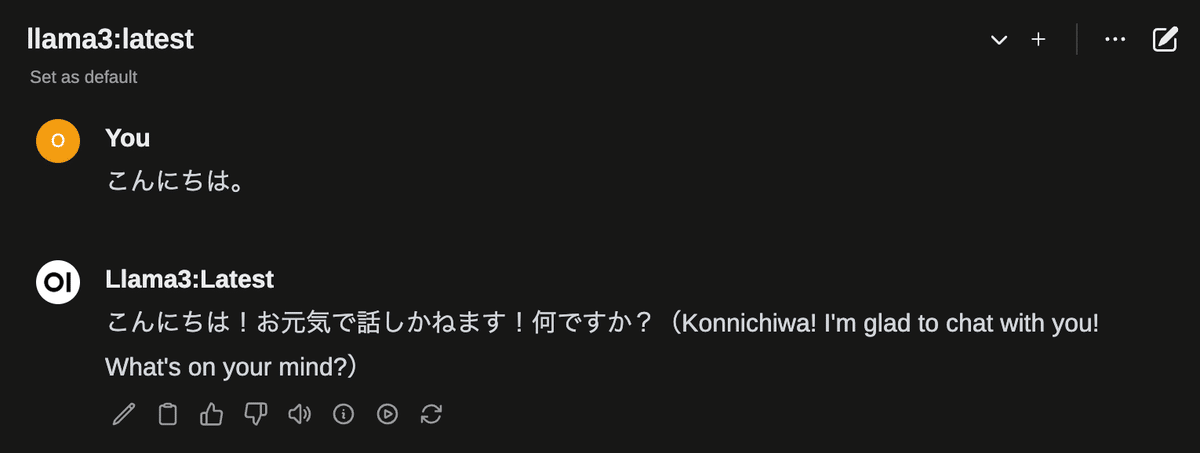
右上のモデル選択にて Llama 3:latest を選択して、下の Message 欄に文章を入力してください。少し待つと文章が生成されます。
参考までに、M2 Mac メモリ 32GB だと、2B や 7B のモデル、8x7B の MoE モデルは動きます。70B はなんとか動きますがかなり生成が遅いくらいです。正確には少し異なりますが、参考値としてモデルのファイルサイズを見て 32GB 程度までならメモリ 32GB で動く感触です。Windows の場合は少し異なるかと思うので、もしお持ちの方がいらしたら教えていただけると助かります。
Open WebUI を使って Ollama を動かしてみよう
Open WebUI は元々 Ollama WebUI という名前で、まさに Ollama を WebUI として利用するためのものです。RAG 機能がついていたり、履歴機能がついていたり、ユーザ管理ができたり、音声入力ができたりと至れり尽くせりです。
Docker を用いてセットアップをするのですが、一行コマンドを入力するだけですので難しいことはありません。まずは Docker を入れてみましょう。もちろん入れている方はスキップしてください。

Docker.app を起動してください。Terminal を開いた時にように Spotlight で検索してください。もし出てこない時は少し待って、それでも出てこない場合はもう一度入れ直してください。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainTerminal を開いて上記のコマンドをコピペするだけです。特に表示などはありませんが、エラーが出ていなければ問題なく起動できています。
http://localhost:3000/
Docker のセットアップが完了したら上記の URL を開いてください。
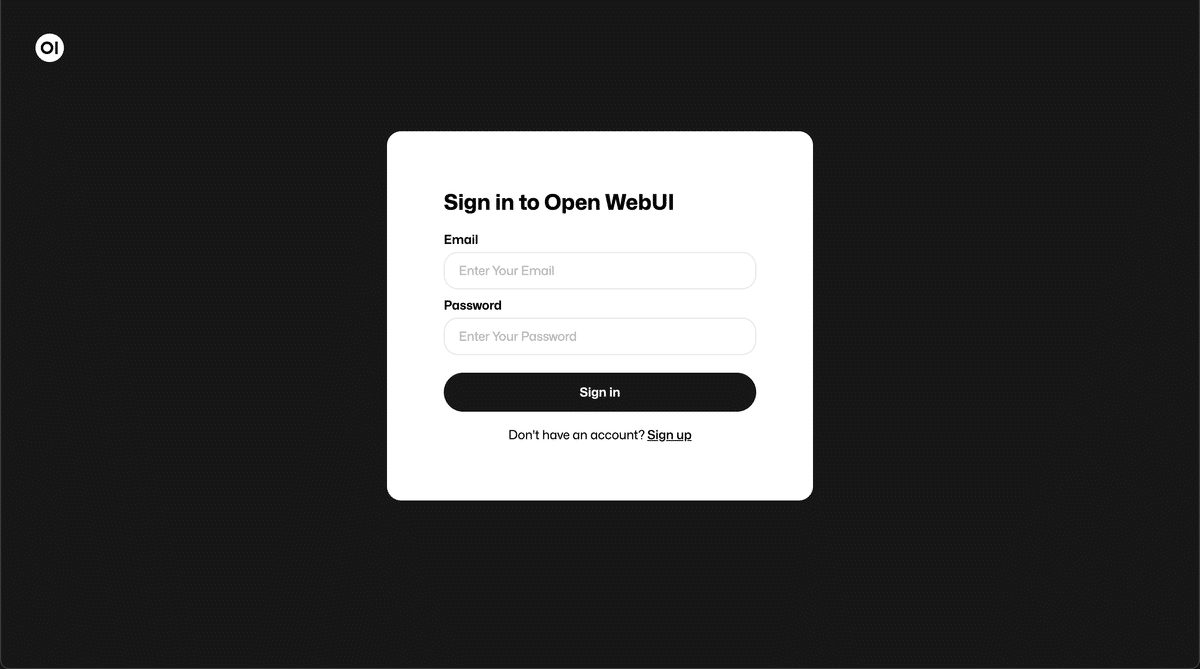
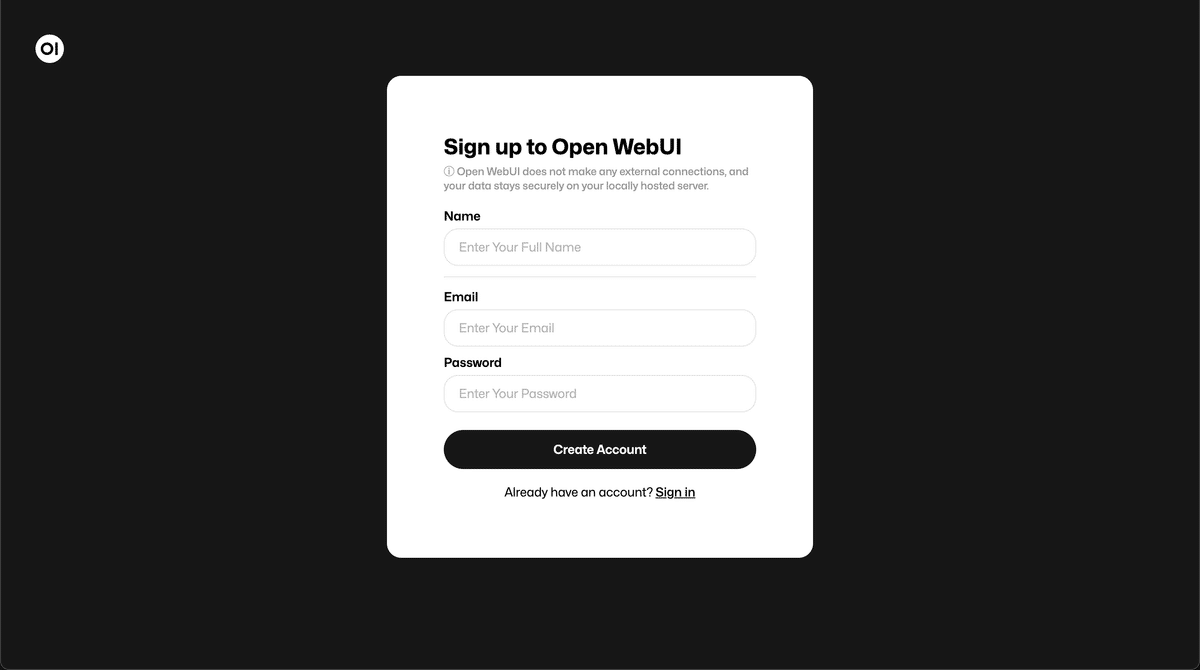
上記の登録フォームが現れたら成功です。どこかのサービスに登録するような UI ですが、ローカルで動いているユーザ管理のための機能です。Sign up を押して、いったんは適当なメールアドレスとパスワードを設定してみてください。
# なんでも良いですが困ったらこの Name / Email / Password をお使いください。
ollama
ollama@example.com
ollama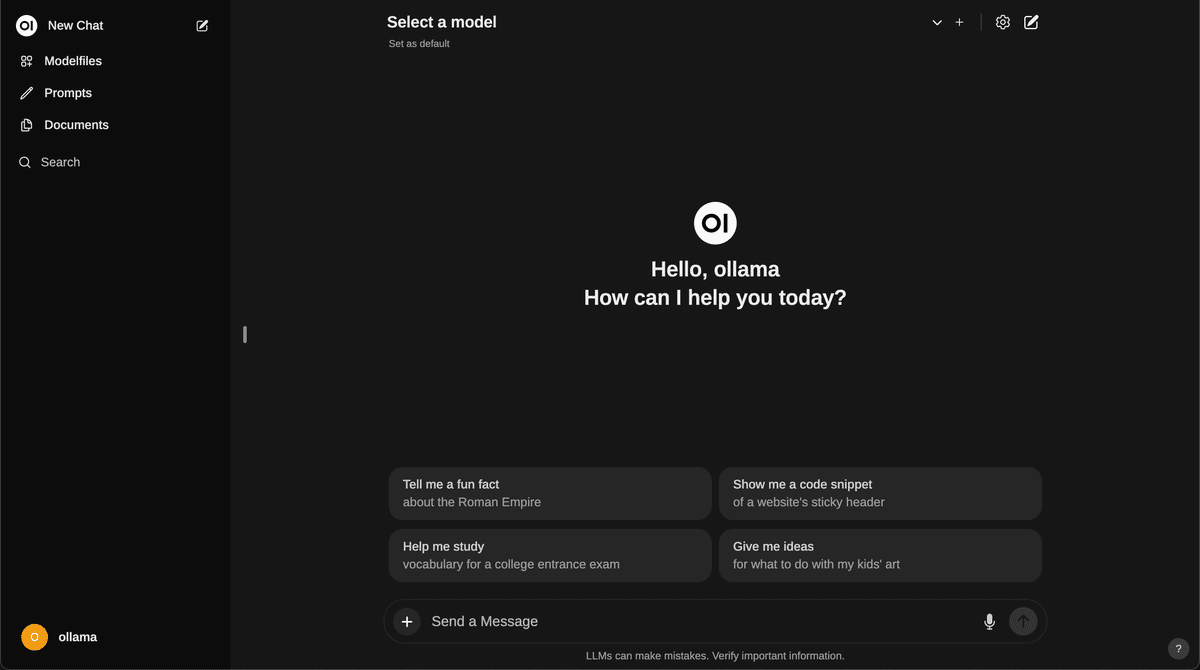
上記の画像のような ChatGPT に似た画面が表示されたら成功です。上に Select a model とあるので、llama3:latest を選びましょう。Send a Message に文章を入力して返事が返ってきたら OK です。
Docker を片付ける時は下記の画像を参考に Containers / Images / Volumes を Delete してください。もちろんわかっていらっしゃる方は CLI からでも構いません。
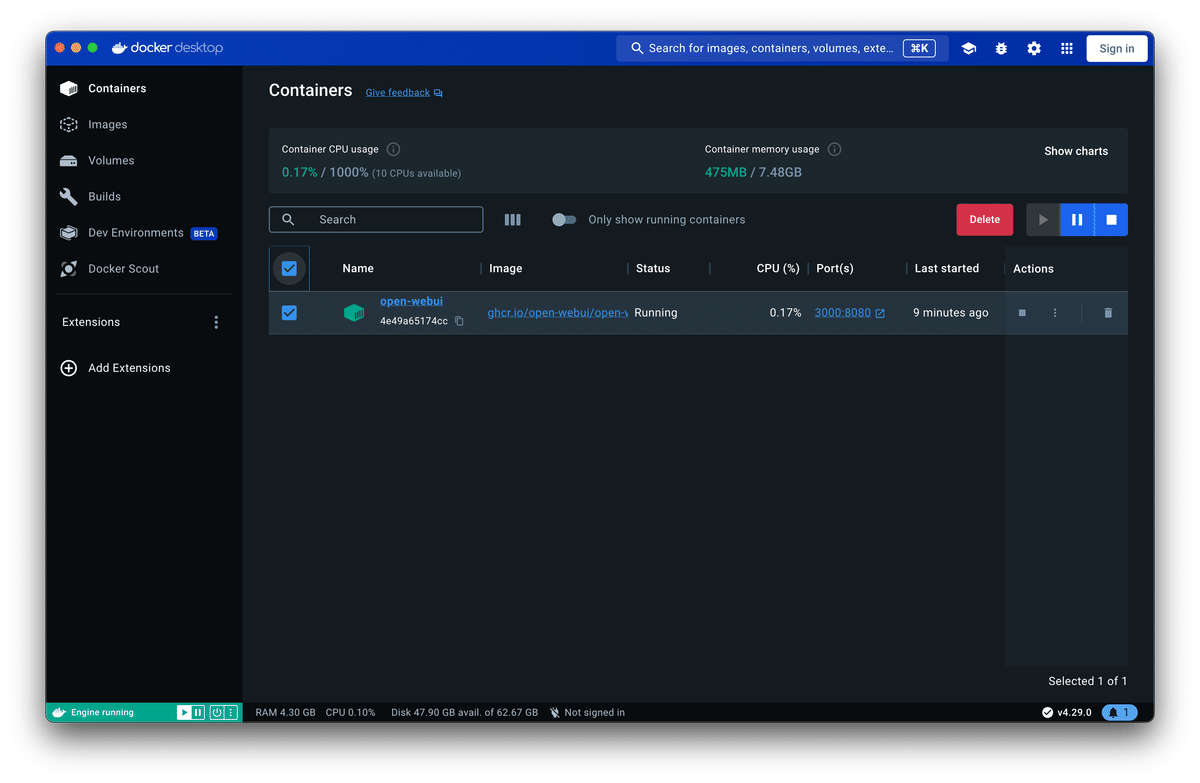
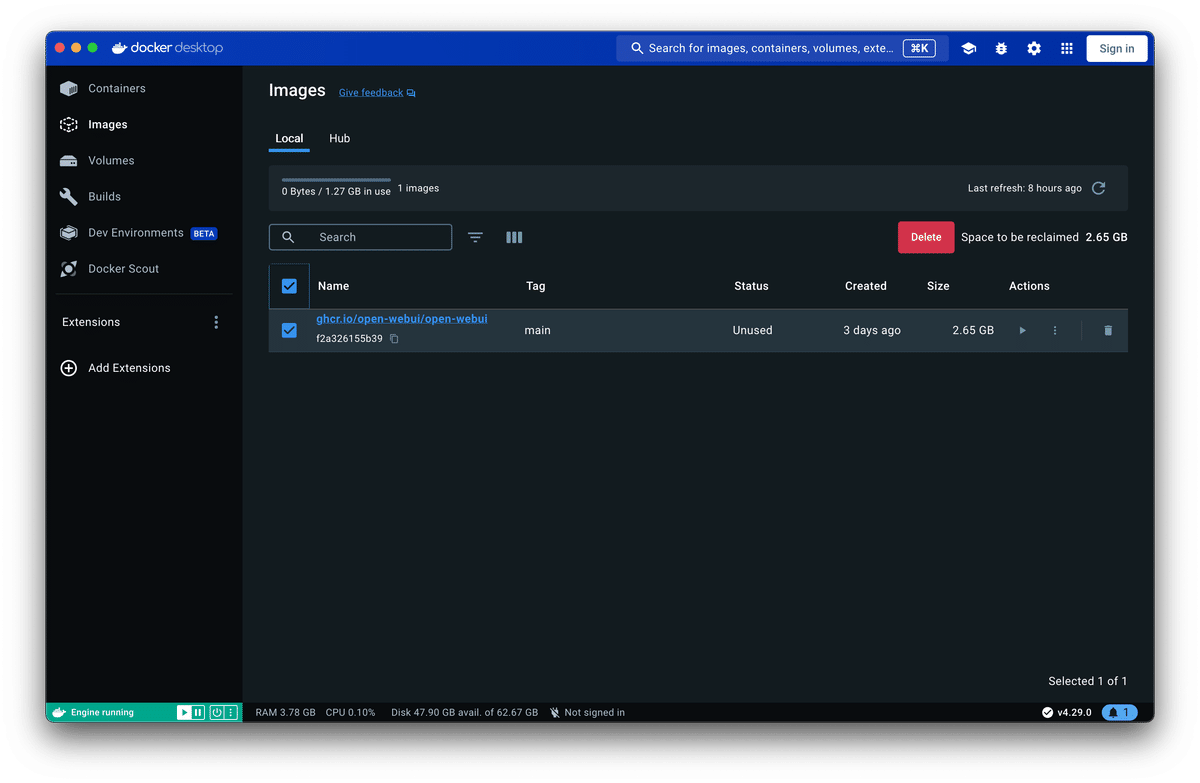
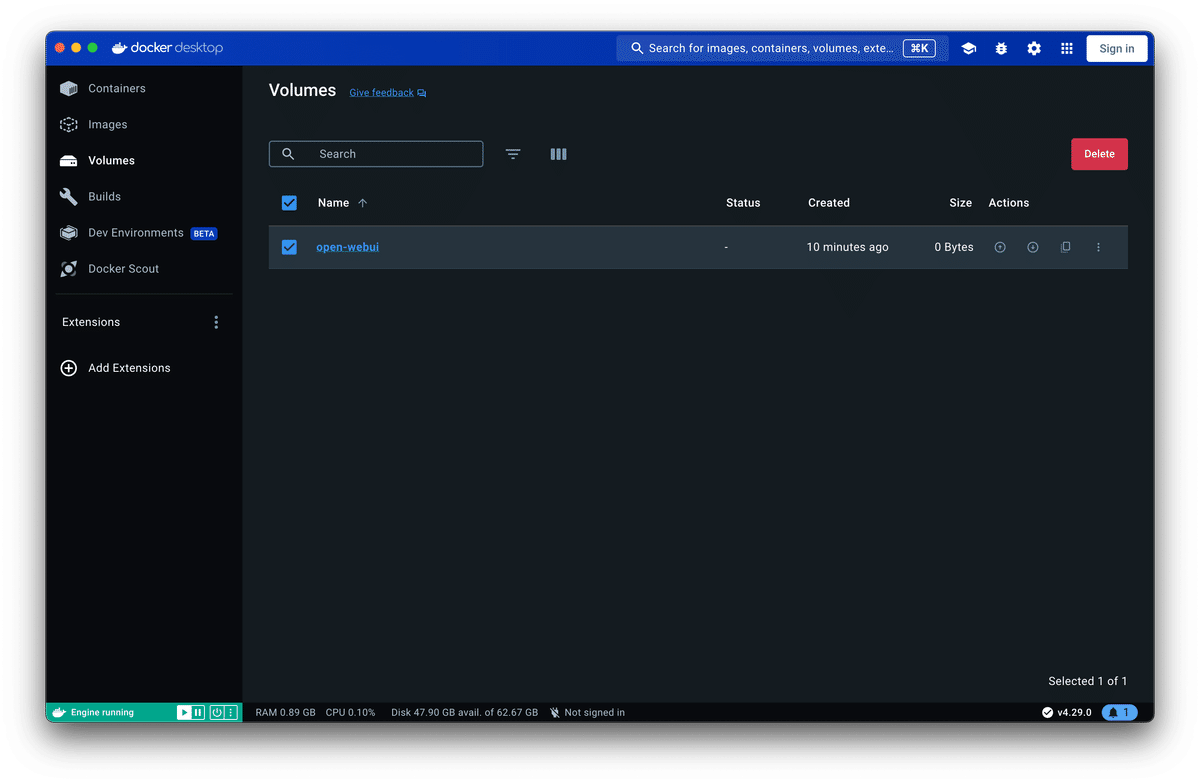
4. 大きなモデルを小さくして使ってみよう
量子化について知ろう
ここまではローカル LLM をこれから触ってみようという方が対象でした。ここまで物足りなかった方はすみません。少しレベルをあげていきます。
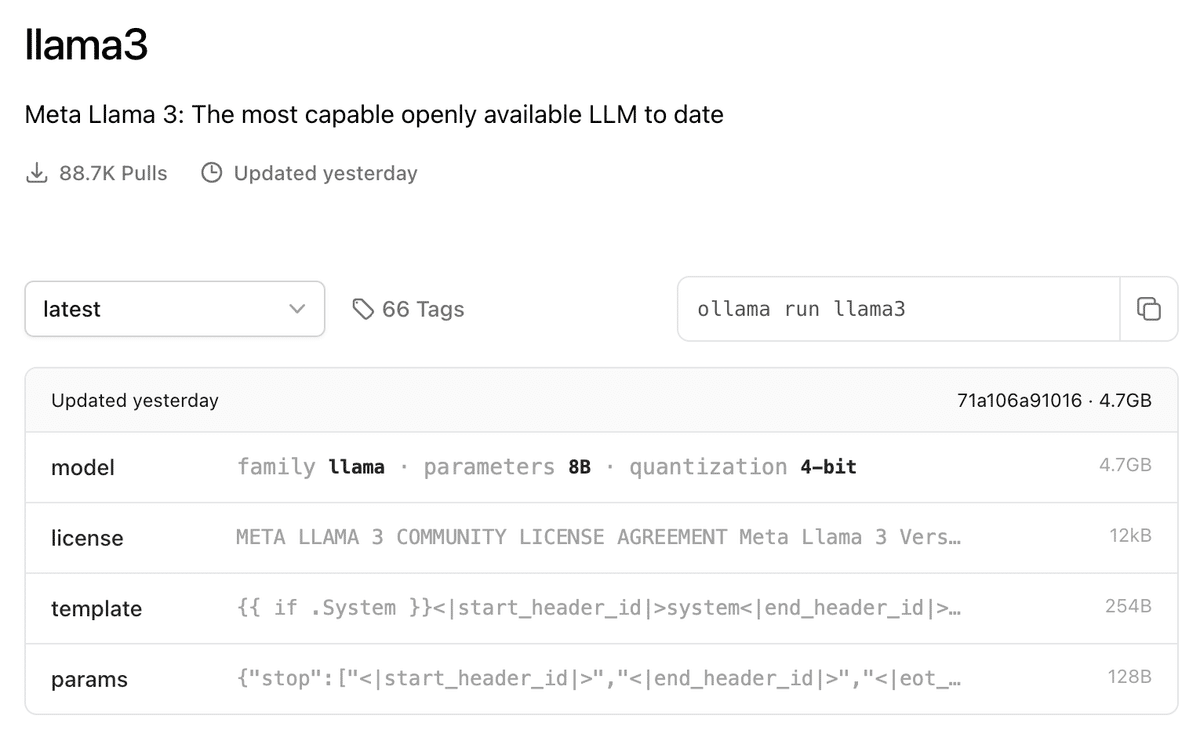
ollama run llama3ここまで上記のように Llama 3 を Ollama で実行しました。Llama 3 の Ollama のページを見てみると parameters 8B の横に quantization 4-bit と表記があります。量子化と言われる処理をしています。
今まで読んだ記事の中で量子化についてよく書かれていた記事です。「モデルのパラメータを少ないビット数で表現すること」を量子化と言います。量子化のおいしいところは、推論の高速化と推論に必要なメモリ量を削減することです。つまり、同じスペックのパソコンでもより性能の高い LLM を動かせるようになり、かつ速度アップするという優れものです。
Ollama ではモデルライブラリのページに 4-bit と記載があったり、標準で量子化されたモデルを利用することができます。便利ですね。一方で、出たばかりのモデルや自前のモデル、たとえば日本語モデルに対応していないことも多いです。そういった時に自分で量子化し、Ollama で使えるようにすることがこの章の目的です。
量子化というと、AWQ や GPTQ、EXL2 はたまた HQQ などいろいろな手法が提案されており手法によってライブラリが異なるため、自前で量子化フォーマットに変換することは面倒でした。量子化モデルを有志で公開してくださっている方々で有名な方に TheBloke 氏や momonga 氏がいらっしゃいます。
手法によって性能が微妙に変わるためモデルにとっての最適な手法が見えにくいこと、モデルを一度量子化すると元のモデルに戻せないこと、LLM の開発企業は量子化せずとも学習に用いた GPU で動作確認までできるので、公式から量子化モデルが出ることは多くはありません(と認識しているのですがもしご指摘などあればご教示いただけると幸いです)。
LLM エンジョイ勢かつ量子化難民となった私たちの味方のライブラリがそう。知る人ぞ知る quantkit です。
quantkit を使ってみよう
量子化を一度でもしたことのある方なら難しくありません。したことのない方にとってもあまり難しく考えることなく量子化できるものがこちらのライブラリです。ここから先は開発経験のある方推奨です。
mkdir quantkit-playground && cd $_
# rye を入れていない方は brew install rye をどうぞ!
rye init
rye pin 3.11
# macOS の方
rye add llm-quantkit
# cuda の使える方
rye add llm-quantkit[cuda]
rye syncPython 3.12 だといくつかのパッケージがサポートされていないため、3.11 で固定し、llm-quantkit をインストールしてください。私はあんまりグローバル環境を汚したくはないので Rye を使っていますが、必要に応じて venv などをご利用ください。
rye run quantkit --help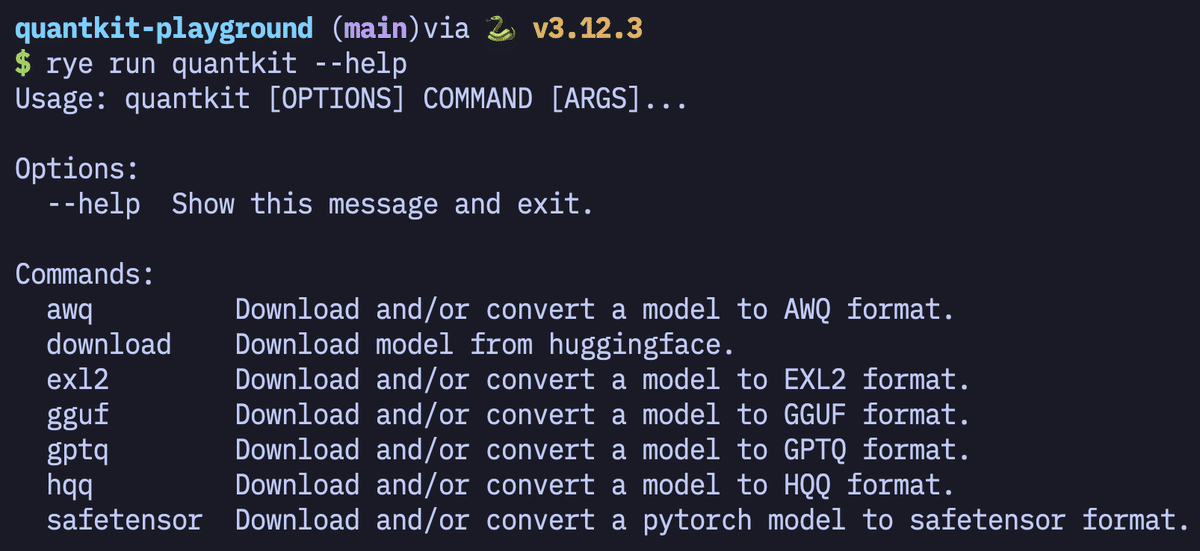
手始めに東工大の Mistral ベースの LLM の Swallow-MS を対象に量子化してみましょう。本来はチャットチューニングされたモデルを使いたいのですが、まだ公開されていないのでベースモデルの方を使います。
rye run quantkit download tokyotech-llm/Swallow-MS-7b-v0.1上記のコマンドを実行してモデルをダウンロードしてください。回線速度によりますが、30 分程度を見ておいてください。ではダウンロードした LLM を量子化してみましょう。
gguf フォーマットで Q4_K_M に変換して動かしてみよう
詳細は省きますが、モデルを gguf に変換し、その後好みの bit 数に量子化する
rye run quantkit gguf Swallow-MS-7b-v0.1/ --output Swallow-MS-7b-v0.1_Q4_K_M.gguf Q4_K_Mお使いのパソコンにもよりますが、2 分弱で変換できるはず。次に Ollama の Modelfile を作りましょう。
echo "FROM Swallow-MS-7b-v0.1_Q4_K_M.gguf" > Modelfile
ollama create Swallow-MS-7b-v0.1_Q4_K_M -f Modelfile10 秒くらいで変換が終了します。Enchanted のアプリケーションを落として、再起動をするとモデルの一覧に「Swallow-MS-7b-v0.1_Q4_K_M」が追加されています。

もしチャットチューニング済みのモデルを使う場合は、Modelfile に下記のようなプロンプトテンプレートを与えてあげてください。
FROM ./modelname.gguf
TEMPLATE "[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>> {{ .Prompt }} [/INST]"最後に
ローカル LLM の面白さを伝え、難しいイメージを払拭しようと試みたのですが、いかがでしたでしょうか。思ったより簡単に動かすことができたのかなと思っていただければ嬉しいです。
もしよろしければ X(Twitter) でフォローいただけるとうれしいです。普段は LLM や広く AI 関連の情報の発信をしています。
追記
Swallow-MS-7b-instruct-v0.1 が公開されていたのでこちらでも試してみましょう。流れとしては同じですのでコマンドのみを記載します。
rye run quantkit download tokyotech-llm/Swallow-MS-7b-instruct-v0.1rye run quantkit gguf Swallow-MS-7b-instruct-v0.1/ --output Swallow-MS-7b-instruct-v0.1_Q4_K_M.gguf Q4_K_Mecho "FROM Swallow-MS-7b-instruct-v0.1_Q4_K_M.gguf" > Modelfile
printf 'TEMPLATE "<s>[INST] <<SYS>>\\nあなたは誠実で優秀な日本人のアシスタントです。\\n<</SYS>> [/INST]</s>[INST] {{ .Prompt }}[/INST]"' >> Modelfile
ollama create Swallow-MS-7b-instruct-v0.1_Q4_K_M -f Modelfile
この記事が気に入ったらサポートをしてみませんか?