LLMファインチューニングのためのNLPと深層学習入門 #4 seq2seq (sequence-to-sequence)

今回は、CVMLエキスパートガイドの『seq2seq (sequence-to-sequence) [機械翻訳]』を勉強していきます。
1. seq2seq の概要
seq2seq(sequence-to-sequence)とは、機械翻訳で初めに用いられた、テキストなどの系列データ同士の系列変換モデルを、RNN2つの直列接続で構成されるRNN Encoder-Decoderで学習する仕組みです。
seq2seqは、のちにアテンション機構を加えたseq2seq with attentionが提案され、様々な系列変換問題に使用されるようになりました。
Transformerへつながるという意味で、アテンション機構を備えていないseq2seqは深層学習時代のもっとも重要なターニングポイントの1つであると言えます。
2. seq2seqによる機械翻訳

seq2seq (sequence-to-sequence) [機械翻訳]より引用
seq2seqの機械翻訳問題では、系列長Nの入力文Xと、入力文と同じ意味を持つ系列長Mの、変換後の出力文Yのペアを用意して、これらの系列間で自動翻訳が行えるようにseq2seqを学習します。
図1では、入力文の言語は英語で、出力文の言語は日本語です。
2.1 seq2seqの構成
まず、入力文と出力文の正しいペア1つを、次のように定義します。
入力文の単語ベクトル系列:
$$
X={x^{(1)}, x^{(2)}, ..., x^{(N)}}
$$
出力文の単語ベクトル行列:
$$
Y={y^{(1)}, y^{(2)}, ..., y^{(M)}}
$$
この翻訳文ペアは、同じ意味同士の、異なる言語の文です。
機械翻訳向けのseq2seqでは、これを大量に用意し、入力文をもとに出力文を学習することで、系列変換モデルとして使えるようになります。
ここで、入力系列のj番目の単語表現$$x^{(j)}$$と、出力系列のi番目の$$y^{(j)}$$を、RNNが計算しやすい低次元の潜在変数(図1の隠れベクトル)へと変換するために、それぞれの言語用に埋め込み層の投影行列(もとい全結合層)$$E^X$$, $$E^Y$$を学習しておきます。
元のK=15000語彙中のどの単語かを示すone-hot表現K次元ベクトルを、100~512次元程度の低次元ベクトル表現へと埋め込み層で射影した埋め込みベクトルを用います。
これにより、各フレームでRNNに$$E^X$$で単語埋め込みを行った低次元ベクトル$$x^{(j)}$$を各フレームで入力できるようになります。
ここで、one-hot表現と埋め込み層について軽く触れておきます。
one-hot表現
K次元ベクトルのうち1つの次元だけが1で、そのほかは全て0であるベクトル表現のこと。(図2)
あらかじめ辞書中の各単語をone-hotベクトルへと符号化しておき、各文の各単語を辞書中の対応するone-hotベクトルで表現します。
NLPでは、高次元のone-hotベクトル入力は埋め込み層や位置符号化などを用いて、低次元表現ベクトルに変換します。その後、マルチモーダルCNN終盤の識別層やRNN、seq2seq with attention、Transformerなどの系列系モデルへと入力する処理パイプラインを使用することが標準的です。

one-hot ベクトル [ディープラーニングの文脈で]より引用
埋め込み層
入力の単語・トークンのone-hotベクトル表現(高次元の表現)を、自然言語処理ネットワークが扱いやすい低次元の単語・トークン表現ベクトルへと埋め込む全結合層のこと。
NLPでは、トークンIDをベクトルK個を保管して、IDですぐにそれらを取り出せるようにしたルックアップテーブルとして実装するのが標準的
TransformerやBERTなどのモダンな言語モデルでは、埋め込み層をトークン入力部分に配置し、トークンIDをもとに低次元トークン表現を獲得するために使用します。
Transformerの場合、埋め込んだトークン表現ベクトルはデフォルトで512次元ベクトル
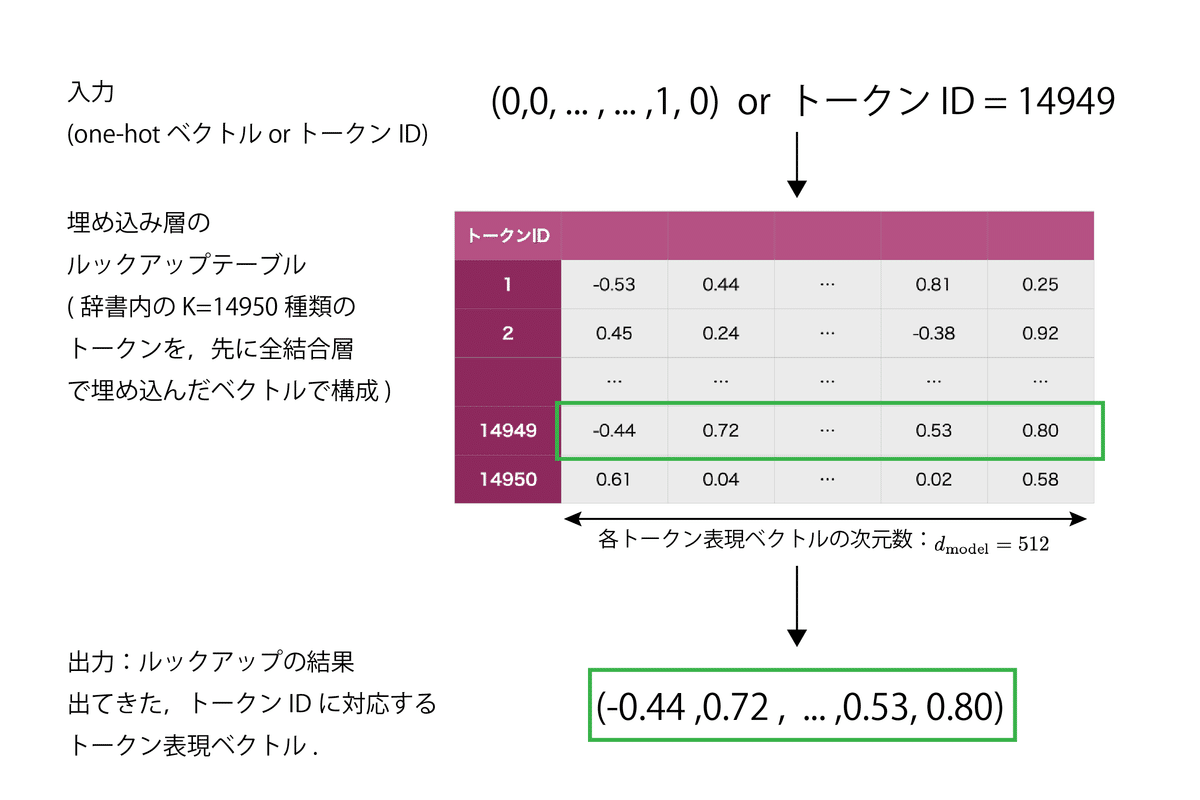
埋め込み層 (Embedding Layer) [自然言語処理の文脈で]より引用
2.1.1 seq2seqのEncoderとDecoderの役割
さて、seq2seqによる機械翻訳では、以下のRNN Encoder-Decoderを使用して言語間の変換を行います。

seq2seq (sequence-to-sequence) [機械翻訳]より引用
エンコーダRNN(図1青色)
入力系列をエンコードして単語系列を符号化する
デコーダRNN(図1赤色)
出力系列をデコードし単語を予測して1単語ずつ順に生成する
2.1.2 seq2seqの処理
エンコーダRNNのj番目の隠れ状態ベクトルを$$s^{(j)}$$とし、デコーダRNNのi番目の隠れ状態ベクトルを$$h{(i)}$$とします。
エンコーダRNNの隠れ状態系列:
$$
{s^{(1)}, s^{(2)}, ..., s^{(N)}}
$$デコーダRNNの隠れ状態系列:
$$
{h^{(1)}, h^{(2)}, ..., h^{(M)}}
$$
なお、引き続き
入力文の単語ベクトル系列:
$$
X={x^{(1)}, x^{(2)}, ..., x^{(N)}}
$$
出力文の単語ベクトル行列:
$$
Y={y^{(1)}, y^{(2)}, ..., y^{(M)}}
$$
です。
これらを用いてseq2seqの処理を説明すると次のようになります。
エンコーダRNNが、他言語に変換したい「ソース言語」の文章全体を隠れ層ベクトル$$s^{(j)}$$へエンコードします。
デコーダRNNは、エンコーダから受け渡された最後の隠れ層ベクトル$$s^{(n)}$$を最初の入力とし、以降は「ターゲット言語」の初の単語を1つずつRNNで生成していきます。
エンコーダの各フレームでは、生成された直前の予測単語を、$$E^Y$$で埋め込んだベクトルも次の単語を予測する入力として用いながら1単語ずつターゲット分を生成していきます。
2.1.3 低次元の入力単語表現へ射影する「埋め込み層」の学習
ここで、機械翻訳では、ソース言語とターゲット言語の統計から限定された語彙をデータセット文から構築するので、入力$$x^{(j)}$$と出力$$y^{(i)}$$は学習可能です。
そこで、word2vecで重みを初期化した埋め込み層を用意しておいて、ソース言語の単語埋め込み層$$E^{(X)}$$と、ターゲット言語の単語埋め込み層$$E^{(Y)}$$もseq2seqと一緒に学習することが普通になっていきました。
また、語彙K=15000は、各単語における頻出度の上位15000単語から、データセットの単語頻度解析を通じて決めます。
上位頻度単語群以外は、未知語として[UNK](tokenizerのspecial tokensにあるやつです)という特別トークンとして取り扱い、語彙から除外してノイズのように1クラスにまとめて扱えるようにします。
以上が、埋め込み単語ベクトルの準備です。
また、これはVision-LanguageやText-to-Speechなど、異なるモーダル間の変換においてseq2seqを用いる場合も同じで、言語ごとに単語埋め込み層をデータセットの文章群から学習しておきます。
2.1.4 補足 - Transformer登場以降
Transformerの登場以降は、事前にWordPieceやSentencePieceなどの自動トークナイザを用いて、サブワードレベルまで分割した「トークンの辞書」を、NLPでの系列変換のフレーム入力として用いることが主流となっています。
2.2 処理手順
seq2seqの処理手順は、次の「3段階の処理」で構成されます。
(1) 前半RNNの処理
前半、つまり入力文では、エンコーダのRNNを用いて、翻訳元であるソース言語のテキストの各単語を、隠れ層ベクトルにエンコードします。
(2) RNN間で潜在状態ベクトルを受け渡し
Encoder RNNの最後の隠れ層ベクトル$$s^{(N)}$$が、Decoder RNNの最初の$$h^{(1)}$$に渡されます。
この橋渡しにより、Encoder RNNで系列全体の情報が符号化された潜在変数ベクトルがDecoder RNNに渡され、Decoder RNNはそれをもとに翻訳後の言語での文章生成が開始できます。
Decoder RNNに渡されるのはEncoder RNNの最後の隠れ層ベクトルだけです。
なぜ最後の隠れ層ベクトルだけで系列全体の情報が符号化された潜在変数ベクトルとして機能するのでしょうか?
これはRNNの性質によるもので、RNNは各フレームの入力を受け取りながら隠れ層の状態を更新していきます。
この隠れ層の状態は過去のすべての入力情報を「記憶」していると考えることができます。
したがって、最後のフレームの隠れ層の状態は、入力系列全体の情報を符号化した潜在変数ベクトルとして機能します。
(3) 後半RNNの処理
後半では、翻訳先の言語Bのテキストを生成します。
Decoder RNNは、Encoder RNNから得たソース言語の最後の隠れ層ベクトルを最初の入力として、単語を1つ生成します。
そして、次の単語を予測するとき、先ほど生成した単語を入力として用いながら文章全体を生成していきます。
特殊トークンの<EOS> = End of Sentenceが予測された時点で文章の生成は終了するので、翻訳が終わったということになります。
3. seq2seq with attentionへの発展
seq2seqでは長い入力系列を扱う際、初期の単語の情報を保持することが難しく、また出力単語数が多いと潜在変数の値が似通ってしまう問題がありました。
これを解決するために、seq2seqに「アテンション機構」を追加したseq2seq with attentionが提案されました。
前回までの記事で何度も取り上げたのと、次の記事で詳しく扱うので、内容は割愛します。
4. おわりに
今回は、seq2seqについて勉強しました。
特殊トークンの話とか、ちらほら知ってるものや単語が出てきたのでちょっと嬉しかったです。
この記事も、読み始めたころよりだいぶすんなりと理解ができるようになってきました。
次回はseq2seq with attentionについて勉強する予定です。
それでは。
参考
seq2seq (sequence-to-sequence) [機械翻訳], CVMLエキスパートガイド, 林 昌希, 2021
この記事が気に入ったらサポートをしてみませんか?