Pandasのみで表をウェブサイトからスクレイピングして出力する方法と落とし穴

Pythonユーザーにとってはほぼ必須級のライブラリと言っても過言ではないPandasだが、実はread_htmlを使用することで部分的にwebスクレイピングを行うことも可能だ。この記事ではwikipediaのMicrosoft Windowsのページから表を取得するところまでやってみる。

import pandas as pd
url = 'https://ja.wikipedia.org/wiki/Microsoft_Windows'
df = pd.read_html(url, match='日本語版')
display(df)urlには抽出したいウェブページのURLを代入。read_htmlの1つ目の変数にurl、2つ目に抽出したい表を絞り込めるように検索条件を設定。
実行してみよう。

はい、取得できた。
というわけにはいかない。
displayで表を表示させられていない。
これはどういうことかというとdfに格納されているのはリストでありpandasのDataFrameではないということ。つまりこれをスライスしたり結合したりということはできない。
実行しようとすると「AttributeError: 'list' object has no attribute 'loc'」というエラーが出る。
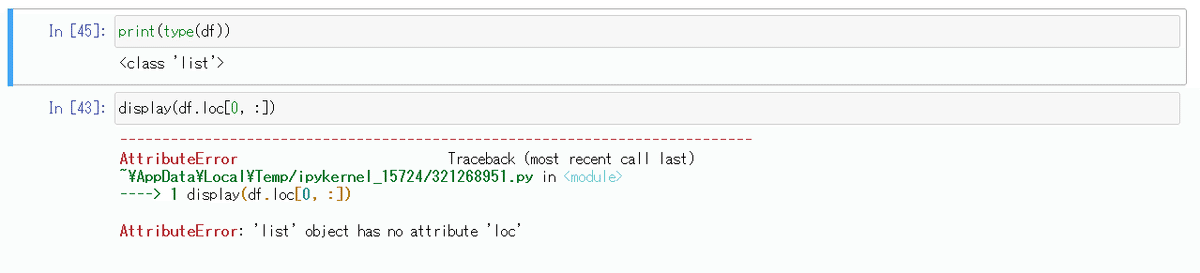
どうすればいいのかというとdfの中は表が1つのlist型ということになるので要素の番号を指定してあげればOK。
import pandas as pd
url = 'https://ja.wikipedia.org/wiki/Microsoft_Windows'
df = pd.read_html(url, match='日本語版')
display(df[0])
表を複数取得した場合も、要素を指定してあげればdf型として処理ができる。
もし参考になったらいいねとフォローよろしくお願いいたします。
この記事が気に入ったらサポートをしてみませんか?