
2023年の開発を振り返る

お久しぶりです。りょうまです。早いもので2023年も残すところあとわずかとなりました。
普段はあまりnoteを書かないのですが年末に経験・スキルの棚卸しもかねて振り返りnoteを書いています。
2022年の振り返り記事はこちら↓
現在、稼働時間の大小はありますが複数社に参画しております。NDAを考慮して具体的な企業名やサービス概要はぼかしてますのでご容赦ください🙏
はじめに

今年一年、お仕事をさせていただいた参画先、チームのメンバーに心から感謝いたします。おかげさまで今年も刺激溢れる開発ライフを送ることができました!
あーでもないこーでもないと議論をしながら一緒になってプロダクトを成長させていく喜びを感じられる最高の一年だったと思います。
2024年も引き続きよろしくお願いします🙇♂️
そして、年末のゆっくりモードの時にこのnoteを見てくださる皆様、ありがとうございます。2023年の開発の中で試行錯誤した結果をたくさん書いてますので、少しでも何かのお役に立てれば幸いです。
2023年のトピック
初めに、個人的な2023年のトピックを2つ書きます。
メガベンチャーに参画。ハードに働く
年始から某メガベンチャーに参画しました。結論としては、レベルが高すぎて常にラーニングゾーンにいる感じです。
今の現場、めちゃくちゃ背伸びしてようやくチョットワカルのレベルになったと思ったら、少し別のディレクトリを見るとまたすんごいハイレベルなことをしていて技術の終わりが見えない。。この前はGrafanaとかPrometheusと睨めっこしてたけど、今週はデータ基盤周りでdbtと格闘してる。最高。
— りょうま@フリーランスエンジニア (@engineer_ryoma) October 27, 2023
レベルが高い、をもう少し具体化すると
上昇意欲が高いメンバーが多い
新卒でカナリアリリースの基盤を組んでいたり、新しく登場したCDサービスをサクッと導入してたり、OSSコミッターがいたり、という風景が当たり前
TerraformやKubernetesによるIaCが徹底されており、ソースコードを見れば全てわかる (メンバー全員が基礎教養としてこれらの技術は使いこなせている)
自動化が徹底されており、属人的なマニュアル反復作業が介在しない。自動化への投資を一切惜しまない
DDDの設計思想の足並みが揃っておりコードが理路整然と整理されている
といった感じでしょうか。そういう環境に身を置くと嫌でも仕事に身が入ると言いますか、今年は例年に比べて業務時間以外で調べものをしたり、キリが良いところまで夜更かしして開発したりと仕事に没頭した1年だった気がします。
生成AIの登場!業務の生産性が2倍になる
2023年最大トピックはやはり生成AIの進化ではないでしょうか。ChatGPTやGithub Copilotに始まり、その他ビッグテックの生成AIへの進出など勢いが止まりませんでした。
旧Twitterでも生成AIのクオリティを前にして自身の存在意義に悩む投稿が溢れかえり、シンギュラリティの始まりを感じたエンジニアも多かったのではないかと思います。
僕自身の仕事にも大きな恩恵があり、体感では時間あたりのアウトプットが2倍以上になりました。
これまで謎の厨二病精神でGithub Copilot入れてなかったんだけど、チームメンバーに勧められて試してみたらびっくり!コーディング速度という観点では熟練のVimmerにCopilotを使ったジュニアが勝てる世界線にきてる。こうなってくると以下にCopilotフレンドリーな関数名を付けられるかゲーになりそう。
— りょうま@フリーランスエンジニア (@engineer_ryoma) October 3, 2023
これまでググっていた文法はGithub Copilotが予測してTab駆動開発できるようになりましたし、苦手としていたシェルスクリプトもChatGPTやCopilot Chatが一瞬で組んでくれるようになりました。
最近は何をどこまで書けばCopilotが適切に予測をしてくれるかという勘所が掴めるようになり、Copilotリテラシーがかなり高くなってます笑
勝手な想像ですが、今後は生成AIの影響で強いエンジニアのパワーが増幅され、実力のないエンジニアの仕事が激減していくのではないかと思っています。AIに仕事を奪われるのではなく、AIを味方につけてより活躍できる側のエンジニアになれるようになりたいものです。
2023年 深く関わった技術キーワード
2023年は以下の技術に深く関わりました。Goの周りで開発をしているとよく目にするキーワードかなと思います。
Go
Terraform
Kubernetes
DDD
GCP
Elasticsearch
MySQL
意図した訳ではないですが、フロントエンドには一切触れておらず、完全にバックエンド、インフラの領域にスキルセットが寄っていった感じです。
Elasticsearch
検索の精度改善タスクを鬼のようにこなしたおかげでかなり詳しくなりました。function scoreをつけて検索結果に重み付けをしたり、painlessスクリプトを書いてさらに細かいロジックを組んだりと、地道な精度改善を続けました。
MySQL
アンチORMで、ほぼ生SQLを書くプロジェクトに入った恩恵で、MySQL自体の理解が深まりました。経験5年目にしてようやく排他制御やトランザクション分離レベルを意識した設計ができるようになりました。
2023年に業務で使用した技術
自分が0→1で導入したものから、すでに導入されていてキャッチアップしたものまで様々ですが、2023年に触れた技術を雑な粒度で並べます。
## 言語、FW
Golang、Ruby on Rails
## GCP
Workflows、Cloud Functions、Cloud Storage、Cloud Scheduler、Pub/Sub、Transcoder、Cloud Run、Cloud Tasks、Cloud DNS、Video Intelligence、Vision API、Cloud CDN、Cloud Load Balancing、GCE、GKE、Artifact Registry、Container Registry、Firebase、Container Analysis、Secret Manager、Cloud SQL、Workload Identify、Identify-Aware Proxy
## AWS
Cloud Front、API Gateway、ECS Fargate、Lambda、ECR、Aurora RDS、EventBridge、SQS、Session Manager、StepFunctions、AWS Batch、CodePipeline、Systems Manager、Sessoin Manager, SecretsManager、S3、Cognito、WAF、Cloud Watch、QuickSight、Athena、Kinesis Data Firehose、Kinesis Data Streams
## Kubernetes関連
ArgoCD、ArgoWorkflow、Istio
## APIデータ通信
gRPC Connect、GraphQL、REST
## IaC
Terraform、Terraform Cloud、Kubernetes
## モバイルアプリ
Codemagic、fastlane、Firebase Cloud Messaging、RevenueCat
## CI/CD
Github Actions、ArgoCD、CodePipeline
## DB関連
Cloud SQL、Aurora、Firestore、Elasticsearch、Memorystore for Redis、BigQuery
## その他
Grafana、Prometheus、Metabase、dbt、Sentry
2023年に対応したタスク
先に前提としてお伝えすると、APIの開発のようなドメイン知識が多いタスクは省いてます。粒度はバラバラですが個人的に思い入れの強いものをつらつらと並べていきます。
gRPC Connect 導入
パフォーマンス改善の一環で、これまでREST APIで行っていたマイクロサービス間通信を一部 gRPC Connectに置き換えました。
Connectとはなんぞやというと、goで書かれたgRPCの不満点を解決したbetter gRPCのような立ち位置です。
・パッケージが軽い
・Goの標準的なhttpミドルウェアを使える
・ウェブから使う場合でもプロキシが不要
・デバッグしやすい などなど
といったメリットがあります。
全てのマイクロサービス間通信をgRPCにリプレースするのは現実的ではないため、リクエスト数の多いところから順次置き換える方針としました。
マイクロサービス間のリクエスト数を出すには色々とやり方がありますが、すでにPrometheusが稼働していたので、Grafanaの画面でPromQLというPrometheus版SQLのようなクエリを書いて可視化する方法を採用しました。
Connect自体がかなり新しいサービスということもあり、情報が少ない中での移行作業は大変でした。とあるConnect関連のパッケージのバージョンを上げるとバグが出るという未解決Issueがあり、丸3日ハマり続けるという苦い思い出もできました。後にも先にもこれ以上ハマる経験はないかなと思います笑
とはいえ、そのプロダクトでは綺麗なDDD構成が徹底されている、かつサービスメッシュとしてistioを入れていたので移行自体はかなりスムーズにできたかなと思います。
追加の対応として、マイクロサービス間通信を俯瞰的に見えるようにすべく、OpenTelemetryとGCPのCloud Traceを導入しました。
これらを入れることで、レスポンスタイムが見れるようになったり、どの通信でエラーが起きているかわかりやすくなったりといった恩恵があります。

Kubernetes コスト最適化により生じた副作用の解決
Kubernetesのコスト改善のために検証環境をプリエンプティブルノードという、いつ止まるか分からないけど安く使えるノードで動かしていました。(AWSのスポットインスタンスに相当)
が、リグレッションテスト実施中にもしばしばサーバが落ちてQA担当の方に迷惑をかけていました。
この状況を解決すべく、常に起動して欲しいIstio関連のPodについてはオンデマンドインスタンスに配置させるようにNode Affinityの設定をしました。
プリエンプティブルノードonlyで運用していた時よりは多少コストが高くなりましたが、検証環境が安定稼働するようになり全体としては大きなペインの解決に繋がりました。
都道府県・市区町村マスターメンテナンスツール作成
市区町村のマスターデータは不定期で変更が入るため全エンジニアが頭を悩ませる問題だと思います。
DBにマスターテーブルを作成しても、定期的にパッチを当てるのは大変だし、アプリケーションからLoadクエリを発行するのも面倒。できれば定数管理したい。とはいえ、ちゃんとメンテナンスされているライブラリもない。
なければ作ってしまおう、という考えでGo製の市区町村マスタライブラリとそのメンテナンスツールを作りました。
市区町村のマスターデータをベタな定数で管理
データソースはお役所が出しているAPI
メンテナンスコマンドを実行することで、APIを実行し、定数を管理するGoのコードを自動で生成
go mod tidy でインストールして手軽に使用可能
これにより、年に一度メンテナンスコマンドを実行することで定数ファイルを最新に保てるようになりました。
S3のアクセス制限
複雑なアクセス制限のあるS3バケットを設定しました。
アクセス制限の要件
・Github Actionsからアップロード可能
・指定のIPアドレス以外からは閲覧不可
この用件を満たすには、多くのエンジニアが感覚でやってきたであろうパブリックアクセスブロックの4項目をちゃんと理解し、最低限の穴を開けた状態で適切なバケットポリシーを組む必要があり、地味に難易度の高いタスクでした。

S3のアクセス制限で丸一日ハマってた。結論以下を理解できてなかった。
— りょうま@フリーランスエンジニア (@engineer_ryoma) April 20, 2023
網羅的にまとまっている記事がないので、後でQiitaにまとめる。
・パブリックアクセスブロックはバケットポリシーより優先される。…
結論、以下をちゃんと理解しておく必要があり、これまでS3完全に理解したレベルだったんだなと痛感しました。(S3の設定ミスで漏洩事故が起きてしまう理由がよくわかる)
S3のアクセス制御を完全に理解するために把握するべき項目👇
— りょうま@フリーランスエンジニア (@engineer_ryoma) April 20, 2023
・IAMユーザー
・IAMロール
・IAMポリシー
・CORS
・ACL
・ブロックパブリックアクセス
・バケットポリシー
・STS AssumeRole
これまでノリで設定してたけど改めてS3の奥深さを垣間見た一日。
Artifact AnalysisによるDockerイメージの脆弱性診断
Dockerイメージの脆弱性を検知すべく、GCPのArtifact Analysisを導入しました。
脆弱性診断の全体の流れとしては以下の通りです。
Artifact Registryにイメージをpush
Artifact Analysisが脆弱性診断を開始
結果をPub/Subが検知してCloud Functionsを起動
Cloud Functionsにて脆弱性の種類を分類、フィルタリングしてslackに通知
注意点としては、全環境でArtifact AnalysisをONにすると月額で数万円単位の課金になるので、push頻度の少ない特定の環境に絞るなどの工夫が必要です。
加えて、この手のアラートは狼少年にならないようにすることが大事なので、本当に対処すべき脆弱性のみに絞って通知するようにしたり、通知をみた人が何をすれば良いかわかるようなslack文言にしたりといった工夫をしました。
狼少年とは「狼が来た」と嘘をついて周囲の大人を惑わせ、本当に狼が襲って来たときに大人に信じてもらえず、羊を食べられてしまう羊飼いの少年についての寓話。 転じて、何でもかんでもアラートを飛ばすと「これは対応しなくて良いやつ」という暗黙の無視が定常化して本当にやばい障害が起こった時に誰も反応しなくなる、というIT業界の教訓としてよく使われます。
セキュリティ施策 Cloud SQL インスタンス分離
新規マイクロサービスを開発するにあたり、セキュリティの要件が厳しかったため、新規のCloud SQL インスタンスにDBを作成することになりました。
それにあたり、既存の基盤では単一インスタンスにしか対応できていなかったため、拡張して複数インスタンスを扱えるようにしました。
具体的には以下の箇所を拡張した感じです。
DB migrationを実行するArgoWorkflow
データメンテナンスを行う踏み台サーバ (GCE)
DB migrationを実行するArgoWorkflow
複数インスタンスに対してmigrationを実行する必要があるため複数のWorkflow管理が必要になりました。
基本的にDBの接続情報以外は使いまわせるため、既存のWorkflowをテンプレート化して、引数を変えることで複数のインスタンスに対して並列でWorkflowを実行できるようにしました。
データメンテナンスを行う踏み台サーバ (GCE)
DBに対して直接SQLを実行するようなメンテナンスは踏み台サーバ経由で行うことが多いかと思います。
元々はVMの中にCloud SQL Proxyのコンテナが1台動いており、コンテナ経由(docker exec)でmysqlコマンドを実行していました。
この仕組みを以下の図のように拡張しました。

簡単に説明すると、
VM起動時のスクリプトにて、以下を実行してコンテナを複数台起動
docker認証
Artifact RegistryからCloud SQL Auth Proxy のimageをpull
dockerコンテナをインスタンス数だけ起動
データメンテナンスを行う開発者はsshでVMにログイン
docker execでmysqlコマンドを実行 (エイリアスを設定)
今回の改修に乗じて、
Container Registry → Artifact Registryへの引っ越しを行ったり、
Terraformの既存moduleをリファクタしたり、
Cloud SQL Proxyをprivateモード、publicモードの切り替えをできるようにしたり、
と欲張って色んな追加改修を行なった副作用で地味に大規模な工事になりました。多少面倒でも一つずつ片付けていった方が良いですね。。
グローバル化対応の設計・開発
プロダクトを6ヵ国にグローバル展開するにあたりバックエンド側の設計・開発を行いました。
具体的にやったことは以下の通り↓
ユーザーにタイムゾーン、国、言語を持たせる
言語単位の変換表をファイル管理
ユーザーの言語にカスタマイズされた検索結果になるようにElasticsearchのアルゴリズムを全体的に改修
ちなみにGoでグローバル対応を行う際のライブラリを色々と検討しましたが以下が良さげでした!
GCP workflowsを使った投稿フローの大規模リファクタ
投稿機能を司るAPIが歴史とともに巨大となり、少しつつくとどこでバグが出るか分からない時限爆弾のような負債となっていました。
ざっくりですが、1つ投稿するだけでも色々な処理が走ります。
投稿は動画と画像、テキストの3種類
動画の場合は変換処理が必要
AIにより投稿内容のコンテンツチェック
設定により運営含む3種類のユーザーの目視確認
DBへのinsert処理
Elasticsearchへのインデックス処理
上記はほんの一例で、細かい分岐処理やif文が山ほど登場します。
非同期処理も入るので、複数のAPIに跨った処理となっており、その場しのぎのif文が量産され、もはやメンテナンスできない状態となっていました。
この負債をGCP workflowsを使って4ヶ月がかりで解消していきました。
GCP workflowsとはAWSでいうところのStep Functionsに相当してまして、APIやCloud Functionsなどをステップ by ステップで呼び出せるオーケストレーションサービスです。ワークフロー自体はymlファイルで管理します。
この巨大ミッションを以下のステップで進めました。
既存フローを図で整理
新規フローの設計
責務に応じて複数のAPIに分離
ワークフローから1つ1つのAPIと繋ぎこみ
当初のイメージでは、人間の確認処理が入ると非連続になるためworkflowsは導入できないのでは?と思っていたのですが、コールバックの仕組みを使えば突破できることがわかり、本格導入に至った経緯です。
最終的に50ステップ超えの巨大なワークフローが完成しました。
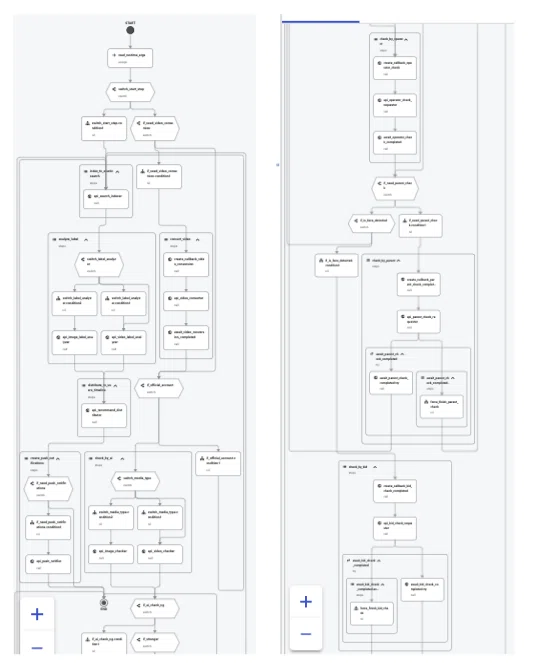
よくここまで複雑な処理を2、3個のAPIで頑張っていたなと思うのと同時に、全体の仕様をyamlファイルから自動生成されるフロー図で鳥瞰できる恩恵をひしひしと感じています。
2023年に最も時間をかけた巨大ミッションだったので詳しめに書かせていただきました笑
Codemagic, fastlaneによるアプリ自動申請パイプラインの構築

これまでアプリリリースの申請をする際、ローカル環境のMacbookでビルドし、Google PlayとApp Store Connectの両プラットフォームにバイナリデータをアップロード。6カ国分のリリースノートを作成という作業をアプリエンジニアが全て手動で行っていました。
このトイルを解決すべく、Githubのmainブランチにmergeしたら自動でビルド、マルチプラットフォーム(iOS/Android)へデプロイ、リリースノートの作成まで完了するパイプラインを構築しました。
使用技術
Codemagic:
アプリ専用のGitthub Actionsという立ち位置。Xcodeを使ったiOSのビルド料金が安く、App Store ConnectやGoogle Play Store との認証が簡単にでき、めちゃくちゃ便利でした!
fastlane
Ruby製のOSS
Codemagic単体では、多言語対応のリリースノートのアップロードができなかったので補助ツールとして使用しました。
iOS、Androidそれぞれでリリースノーとのディレクトリ構成が異なるため、マスターディレクトリから両プラットフォームに対応したディレクトリ構成に整えるためのシェルを組むなどひと工夫が必要でした。
pubspec.ymlの仕様や各ストアへの認証方法、アプリの申請フローなど、モバイルアプリ開発独自の知識も必要のため、バックエンドエンジニアの自分にとっておは総合格闘技のようなミッションでした笑
改めて、いつも地道に申請・リジェクト対応をやってくださるアプリ開発メンバーに感謝です。
自動申請パイプラインの稼働開始後、アプリエンジニアのリリース工数が大幅に削減し、大変好評をいただいてます✨

データマイグレーションファイル自動生成ツール作成
DBとしてFirestoreを使っているプロダクトにて、既存データのマイグレーションを実行する機会が多く、似たようなフォーマットのGoスクリプトファイルを毎度作成していました。
しばらくはファイルを複製して都度カスタマイズして凌いでいましたが、地味に1~2分はかかる作業だったので、流石に限界が来てツールを作りました。プログラマの三大美徳の「怠惰」ってやつですね。
railsのmigrationファイル生成コマンドのように引数を適宜変えることでフォーマットにに沿ったGoのスクリプトファイルが生成されます。
ChatGPTが登場してこの手のツール作成作業がかなり楽になりました。おかげさまでこれ以外にも多数の個人用怠惰ツールを作っています笑
データ分析基盤の改修

ユーザーから不具合のお問い合わせがあった際、CSチームから開発チームへそのまま調査依頼が来ており、調査工数が肥大化している状況でした。
少しでもCSチームでお問い合わせ対応が完結するような仕組みを作りたいという目的で、CSチームが普段使っているMetabaseの分析ダッシュボードにユーザー単位のエラーログを表示する改修を入れました。
そのプロダクトのデータ分析基盤は、
あるゆる情報をBigQueryに集約 (データレイク)
dbtでデータを変換し、見たい情報がサマライズされたviewテーブルを作成 (データマート)
Metabaseから参照
という構成でできており、2と3の箇所に改修を入れました。
このタスクをきっかけに、これまで自分の中でブラックボックス化していたデータ分析基盤への理解が深まったので、今後も機会があればどんどんタスクを拾っていきたいです。
ハイブリッド暗号方式によるデータ暗号化
DBにユーザーのセキュアな情報を保存する際、データの暗号化、および定期的なキーローテーションが非機能要件としてありました。
保存する対象が数万バイトを超える巨大データのため、一般的なAES256形式での暗号化ではキーローテーションで詰みます。
数万バイト×数万レコードの全データを古い鍵で復号化 → 新しい鍵で暗号化すると単純計算でも数日はかかりますし、セキュアなデータをいじること自体やりたくありません。
解決策としてハイブリッド暗号方式を採用しました。
詳細はピヨ太君がわかりやすく解説してくれていますが、簡単にいうと暗号化する鍵1自体を別の鍵2で暗号化するやり方です。キーローテの対象は鍵2になるので、鍵1とデータ自体は不変となり、高速なキーローテを行えます。
このキーローテを行うバッチ処理をCronWorkflowで実装しました。
ハイブリッド暗号方式は基本情報技術者試験の勉強でちょっと聞いたことがあるなという程度でしたが、このように業務で役に立つ瞬間に立ち会えるのは実に面白いなと思いました。暗号化はブロックチェーンのコア技術にもなっていますし、実に奥が深い分野なので今後も勉強していきたいです。
検索エンジン(Elasticsearch) のアルゴリズム改善
冒頭にも書きましたが、2023年は検索結果をチューニングし続ける一年でした。
なんとなくで検索結果を出すことは難しくないのですが、1ユーザー視点でしっくりくるような結果を出すには実に泥臭い検証作業が必要でした。
具体例として、
国、言語
興味関心タグの一致率
最終アクセス日時
の4つのパラメータから検索順位をつけるケースを考えます。
国、言語 > 興味関心タグの一致 > 最終アクセス日時 の順に重み付けを行うとしてMaxのスコアを以下のように割り振ります。
国、言語 → 10点
興味関心タグの一致率 → 3点
最終アクセス日時 → 2点
国、言語は一致していれば点数を入れるだけなので簡単です。
しかし、興味関心タグや最終アクセス日時に点数をつけるのは容易ではありません。
最終アクセス日時に重み付けを行う場合
ある地点を0点、現在時刻をMaxとして基準を置く場合、線形で増やすのかガウス関数的に増やすのかで結果が全く異なります。

興味関心タグの一致率に重み付けを行う場合
興味関心タグを1つ登録しているユーザーに1つヒットするのと、10個登録しているユーザーに10個ヒットするのでは同じ100%でも点数は変わるべきです。(もちろん10個ヒットしているユーザーの方がハイスコア)
このような複雑な条件下では、Elasticsearchが用意しているFunction Score queryだけでは対応できないので、Painless というスクリプト言語を書く必要があります。
本番のデータを検証環境にコピーして、上記のパラメータを少しずついじりながら、1ユーザーとしてしっくり来る検索結果になるようにチューニング作業を続けていきました。
地道な改善を続けた結果、検索機能がキラーコンテンツとして使われるようになり、大変やりがいを感じました。今後も検索アルゴリズム改善エンジニアとして精進していこうと思います笑
さいごに
つらつらと今年の振り返りをしてみました。
たくさんチャレンジし、時に失敗も経験しながら着実に前進できた一年だったように思います。こうして振り返ることで少しは自分を褒めてあげられるきっかけになると思いますので、皆さんも時間があれば是非やってみてください!
最後までお読みいただきありがとうございました!
良いお年を〜
この記事が気に入ったらサポートをしてみませんか?