
ビジネスデータ処理について学んだ(その12)

Pythonによるエクセルの自動化。
冒頭先生から、「やみくもに何でも自動化しようということではなく、データを中心に自動化を考えられるようになることが大切。RPAでは業務フローからシナリオを作るが、Pythonはデータを見る。データがどこに有って、どのように処理されて、どこに溜まっていくかの流れで見ていく。」とコメント。
今回は様々なライブラリを使って処理の自動化を試してみる。
データを中心にみる
データフローダイアグラム
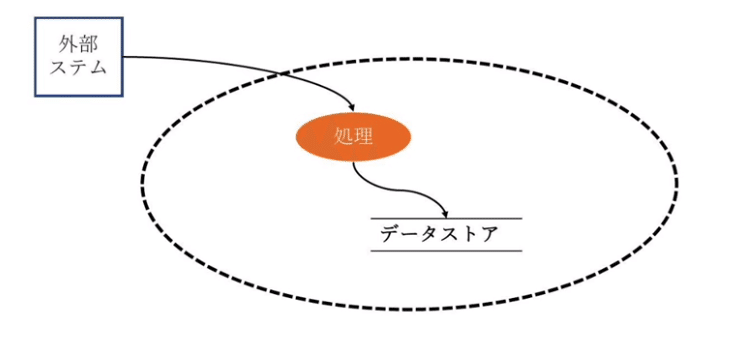
データフローダイアグラム(図1, 講義のスライド資料より)。要件定義にあたって、業務フローの書き出し、整理に使われてきた。データ中心に「データがどこから入ってきて、どんな処理をしてどこに溜まるか(データを中心に書かれている)

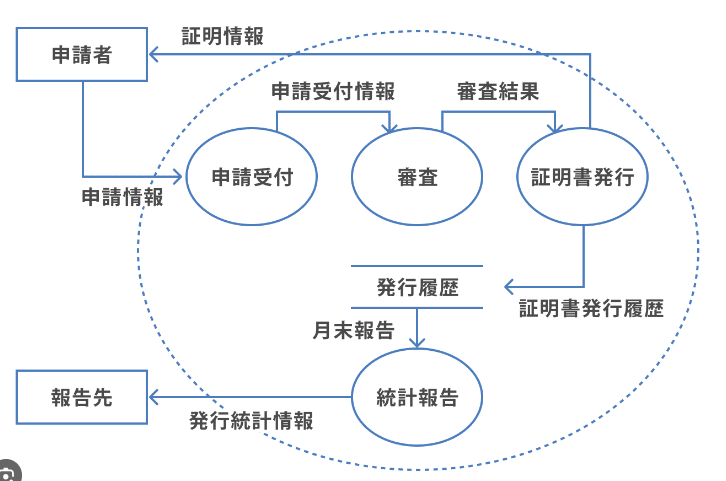
Googleで検索すると色々なデータフローダイアグラム(DFD)の例が出てくる。あくまで一例として図2を貼り付けました。
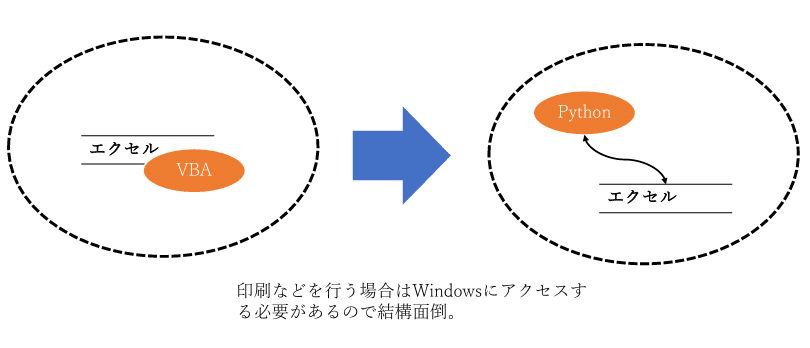
エクセル内のデータ処理の自動化。
元々はエクセル+VBAでやっていたものをPython+エクセルでやろうというもの(図3 講義のスライド資料より)
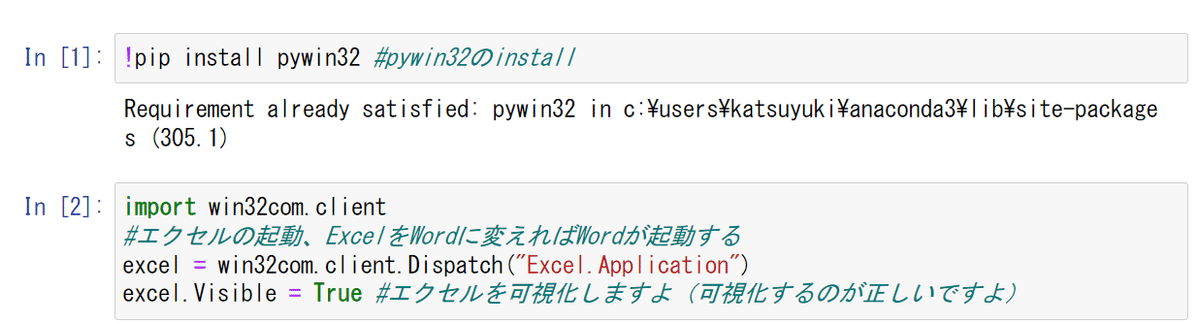
ライブラリpywin32をインストールし、ブックを開く
今回はpywin32というライブラリを使う(Windowsを操作するライブラリなので、Winでしか使えないらしい)。openpyxlはエクセルの仕様に合わせてエクセルを操作するライブラリ(LinuxやMacでも使える)。
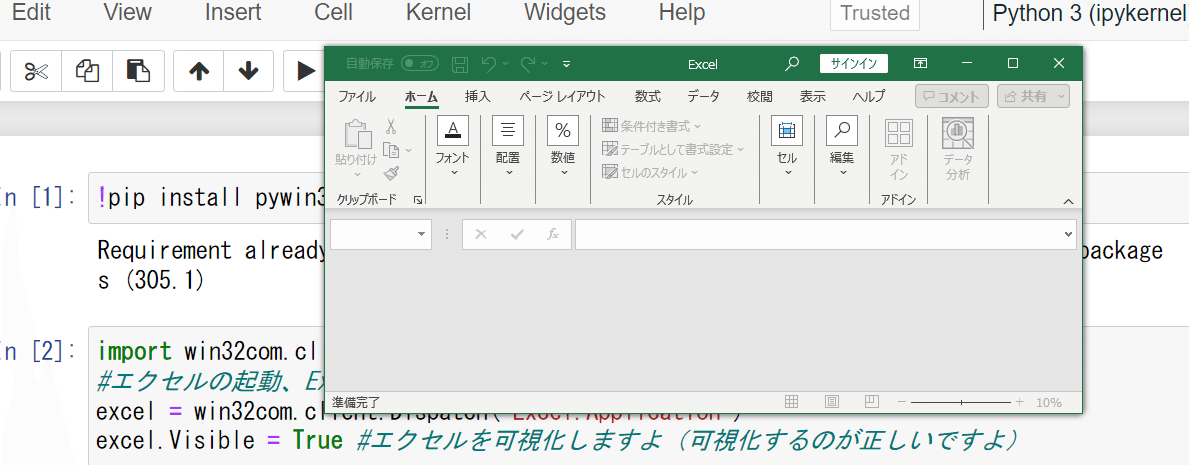
以下の処理で、空のExcelが立ち上がって驚き(図4,5)
win32comのcomはURLの.comではなくて通信の意味だよと先生が仰っていたがよく分からず。
ブックを開く(ブック→シート→セルの流れを忘れない)。
図6のようにコマンドするとブックが立ち上がるはずがエラー(図7)。驚いたことに日本語でエラーの説明が出た。bbtのファイルのすぐ下に会員名簿のファイルを置いていなかった私のミスだった。
置きなおしてやり直す。ちゃんと呼び出せました(すごい)(図8)。ここまでで1日目は終わり、出勤時間になってしまった(私の勉強時間は出勤前)。わずか20分の動画聴講に1時間かかってしまった。


指定したシートを開く
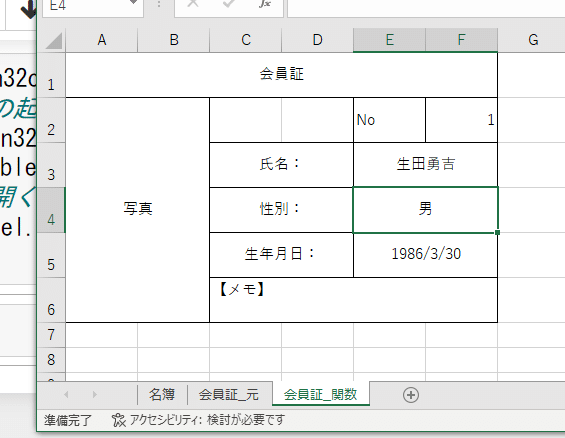
このコマンドは最後に保存されたときにアクティブだったシートが開く。したがって、図8の名簿のシートを表示して保存したときは名簿のシートが立ち上がってくる。
但し、今回の講義では”会員証‗関数”のシートを操作したいので会員証_関数のシートが立ち上がるようなコマンドを入れる(図9)。本当に”会員証_関数”のシートが立ち上がる。

次に図10のF2セルに違う会員番号を入れてその人の会員証を出してみる(図11)
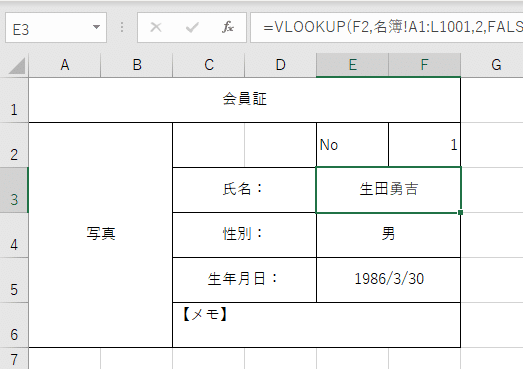

Valueとして7を入れると、会員番号7番の植松さんの会員証が立ち上がる(図12)

PDFで出力する
次にPDFで出力してみる。sheetを固定されたフォーマットで出力しますよというコマンドsheet.ExportAsFixedForamatを入力し、FixedFormatとして、PDFを意味するType=0を入力する。さらに、Filenameコマンドでpdfファイルの名前と保存場所を指定してやる。(図13)

繰り返し処理を使って範囲で出力す
何度も間違えたが、動画を視聴しながらなんとか出力に成功。bbtフォルダーに11番から21番の会員証のpdfが格納された。(図15)本日はここで限界。なかなか進まない。

PC内のデータとエクセルの連携
ここまでは、エクセル内のデータをPythonで書き換えてみた。書き換えたデータ(会員証)はvlookup関数で他のデータを引っ張ってくるので、それぞれの会員さんの会員証を呼び出すことができた。
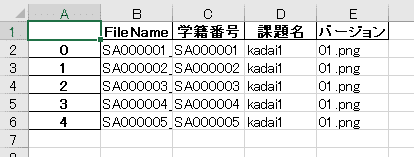
今回は、PCの中に保存されているファイル名を取得してエクセルで一覧にする。(図16 講義のスライド資料より)

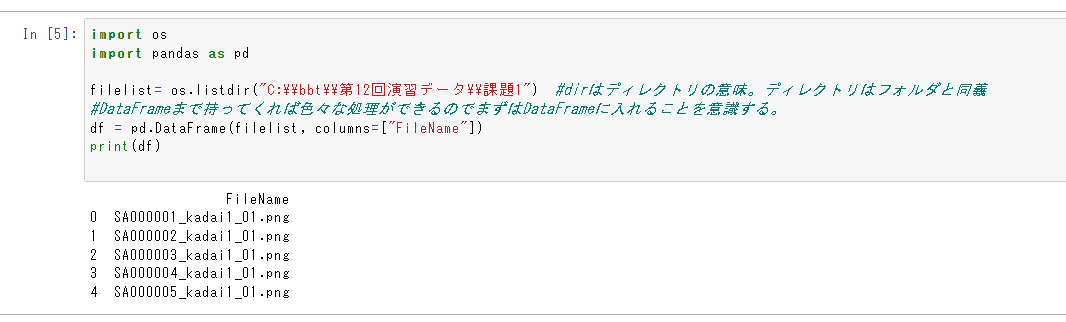
osの機能を使う。osのlistdirという機能を使うと、( )内のフォルダーの中のファイルをリスト形式で出してくれる(図17)

pandasを呼び出して、図17で呼び出したファイルリストを名前はFileNameだよとDataFrameの形で出してあげる。(図18)
今日はここまで。いつ終わるのか??
図18でprintしたDataFrameは学籍番号、課題名(kadai1),バージョン(01)がアンダースコアで区切られている。このアンダースコアを目印にファイル名を分割する(ん?分割?何のこと?)。
講義の動画を見ながらコードを打っていくと、カラム0番は学籍番号、カラム1は課題名、カラム2はバージョンの表形式にしていく作業のようだ(図19)
コードを実行するといきなりエラー(図20)。エラーの内容をググるとどこかに全角が入っている可能性があるとのこと(図21)


どのスペースが全角かよくわからなかったので取り敢えず、すべてのスペースを詰めてしまい、スペース自体をなくして実行。また別のエラー(泣、図22)サイドググると原因と解決策が判明(図23)。ほげ隊長(講師の先生)が講義のどこかで「ググれば大抵の解決策は載っている」と言われていたが、沢山の人が無償で状況を提供してくれていてありがたいなぁと思う。

その後も何度もエラーが出て悪戦苦闘。やっと打ち出せた(図24)ときにはすでに出勤時間(泣)。今回分かったことは、殆どのエラーはググれば誰かが原因と解決法を載せてくれているということ。動画で10分も進まなかった。

表24の表形式を今度はエクセルで保存する。DataFrameのto_excelという機能を使い、ファイルの指定をするだけ。
「するだけ」、「簡単です」と先生は言っていたが、どうなることやら。まずはやってみる。(図25)大事なこととして、図25のdf.to_excelは内部的にopenpyxlを利用しているので、openpyxlが利用できない環境だと使えない。Anaconda上で行っている場合はopenpyxlが組み込まれているので大丈夫。


今日はここまで。本当に全然進まんなぁ。この講座だけでプログラミングができるようになるとは全く思えないが、D1C全体を通しては本当にいろいろ学んでいる気がする。
プログラマーへのレスペクト
どんなことをしているか大体つかめたこと。
ファイル名の指定を守らない人がいたら?
ファイル名の指定を守っていないと手動で一つ一つ修正しないといけない。このようなデータでは、ファイル名の指定を徹底することも効率性の上で重要。
外部データとの連携
図1で出てきた外部システムとの連携を行う。
データがcsvであれば、Pythonで受け取って、エクセルで保存することは簡単。
東京都のオープンデータのサイトで、世帯と人口と検索してみるとすべての市区町村がcsvでデータを公開しているわけではないことがわかる。結構バラバラ(図29)

このようなバラバラのデータを一つにまとめてエクセルで保存するようなことがPythonでは可能。
東京都のオープンデータのサイトからcsvをデータフレームで読み込む。pandasをインポートし、csvデータのURLを定義し、read_csvで読み込む。読み込み時にエラーが出たら、encodeをshift_jisに変えてあげる。今日はここまで。遅々として進まん。
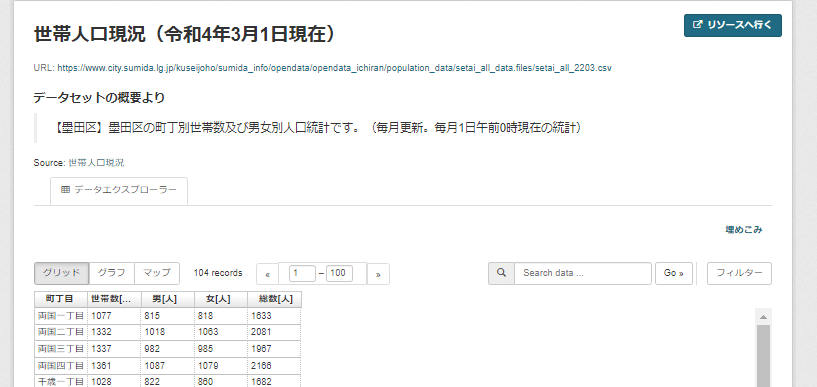
オープンデータのサイトで「世帯と人口」と検索し、一番上に出てきた墨田区の「世帯人口現況(令和4年3月1日)」(図30)のcsvアドレスをコピー
pandasをインポートして、先ほどコピーしたurlをurl変数として指定。printしてみる。以前も作業が正しいか確認のために都度printと先生が言われていたことを思い出す。printしたけどエラー。UnicodeDecodeErrorとある。ユニコードで読み込もうとしたけれども変換がうまく行かなかったというサインらしい。これはデータがshift jisになっていることによるケースが多い。
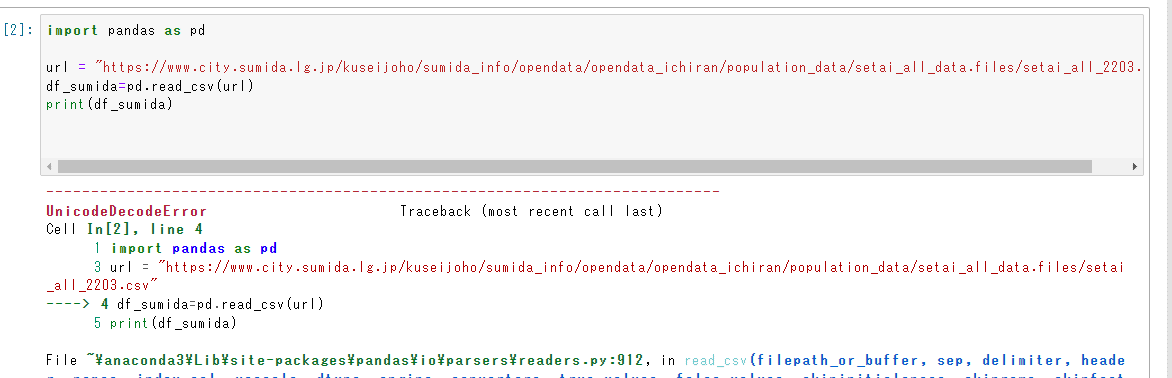
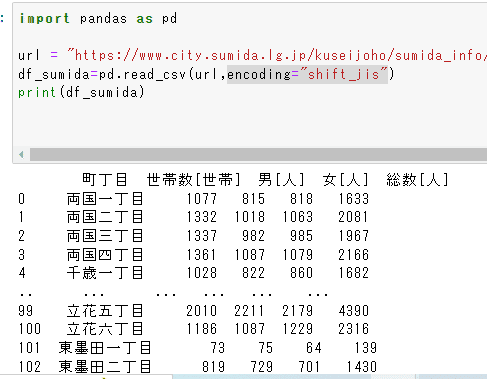
そこで、urlの後に、encoding="shift_jis"として、shift jisで読んでねと入れてあげる。(図31) 。エラーの後にうまく出力されるといつも感動してしまう。
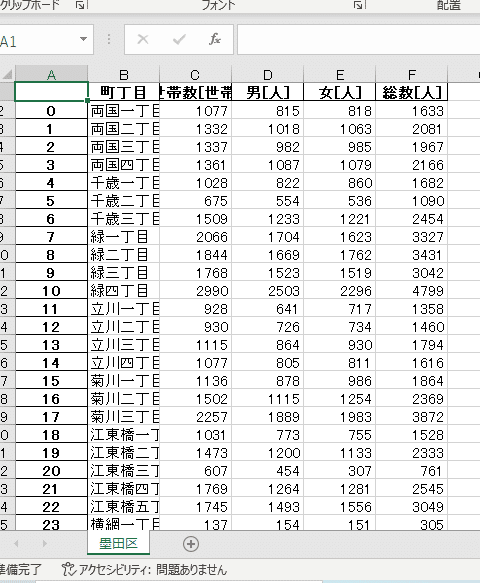
ここでいったんエクセルにして保存する。新しい文法 with とas write:という記載が出てくる。asは~としてという意味で、ここではファイル名を「世帯と人口」と指定したpdのExcelWriterをwriterとして使っていきますよということ。そしてdataframeである、df_sumidaをexcelで保存しますよ、場所はwriterで(要するに世帯と人口ファイルだと言っているのだと思う)、sheetは墨田区ですよと命令している.(図32)
何度もエラーが出るが一つずつ修正しながら、bbtフォルダーに世帯と人口ファイルが出現(図33)。同じような処理を他の区にも行っていくと、世帯と人口のデータを一つのエクセルにまとめることができる。今日はここまで。

練馬区と杉並区のデータも同じブックにまとめていく。杉並区はexcelでデータを出しているのでpd.read_excelで読み出せる。エクセルはencodingは不要のようだ(図34)
練馬区は2年だけ住んでいたので懐かしい地名があるかもしれない。23区内でこのような公開データの形式が違うことに驚いてしまった。
実行してやると、ちゃんと練馬、杉並のデータが追加されている。今回はほとんどコピペだったのでエラーは一回も出なかった(😂)(図35)

実習はここまで。今回は長い道のりだった。最後の振り返り
データ中心にみる
データがどこに有ってどのように処理して、どのように保存されていくのか?処理にあたってPythonやExcelといったツールが出てくるのでうまく使う必要がある。Excelの操作にはいくつかの方法がある。
pywin32は操作は簡単だが、エクセルがインストールされているWindows機のみでしか使えない。
openpyexはいろいろな環境でも使えて早いが、print等行おうとすると複雑(先生曰く結構大変)
ファイル名が重要
アンダースコアでやらないといけないのにハイフンになっていたらだめ。外部のデータをいったんエクセルに集約する方法を学んだ。
動画を見ながらカチカチとコードを打ちこんで、指示通りにエクセルが立ち上がったり、シートが保存されたりすると楽しくて、夢中になってしまうのだが、結局Pythonで何ができて何がやりたいのかが、自分には今一つよく分かっていないので消化不良なところもあり。引き続き取り組んでいきたい。
写真は神戸の六甲山にある「森の音ミュージアム」。珍しいオルゴールが沢山有り、オルゴールによる演奏会が楽しめる。庭が心地よいお気に入りの場所です。
この記事が気に入ったらサポートをしてみませんか?