
ビジネスデータ処理について学んだ(その10)

今回はDataFrameを利用してデータ処理ができるようになり、データをグラフで可視化できるようになることが目標。
新規ファイルとコメント
新規ファイルの作成
Google Colabのファイルメニューから「ノートブックを新規作成」をクリック。空のノートブックが立ち上がる
ノートの名前を変更する
コメントの付け方
#の記号を入れることにより 、プログラムとは別のコメントを挿入することができる。
コメントは緑色になり、プログラムとして処理されない。
読み込んだデータの表示と読みこむ場所を分けておくことができる。
(その9)で行ったようにpandasをpdとしてimportし、read_csvで東京都のデータを取り込む(今回はprintはしない)
1行目は#を入れたコメントなので緑色になっていることに注目(図1)
新しいコードを開いて、print(myData)を入力すると2つ目のコードでデータを読み込んでくれる。こうするとデータの読み込みは一度で済む。

データの抜き出し
print(myData)ではズラズラとデータが出てきてExcelと比較すると非常に見づらい(図2)。この辺りをもう少し見やすくしたい。
まずはprint(データ名.columns)機能でヘッダ行だけ表示させることができる。ヘッダの名前がわかれば、そのカラムの情報だけ抜き出しが可能。
まずヘッダー行のみ表示させる(図3)
そこから特定の列のみ選んでその列(column)の中身だけ表示させる(図4)。print(myData["ヘッダ名"]) 。ヘッダ名を囲むのは大カッコであることと、ダブルクォーテーションを忘れちゃダメ。


loc (Locationの指定)
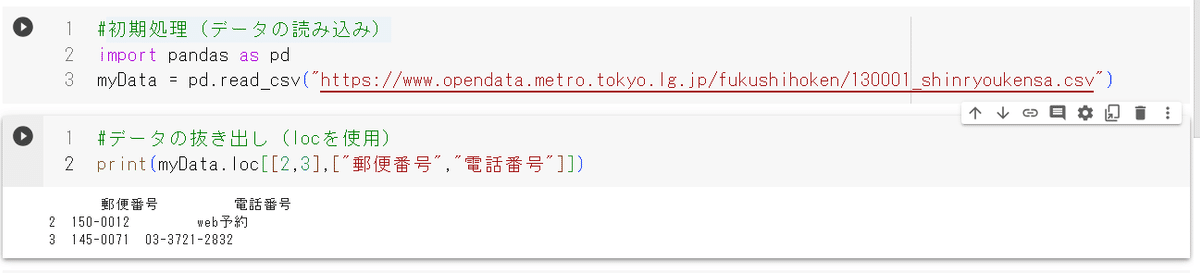
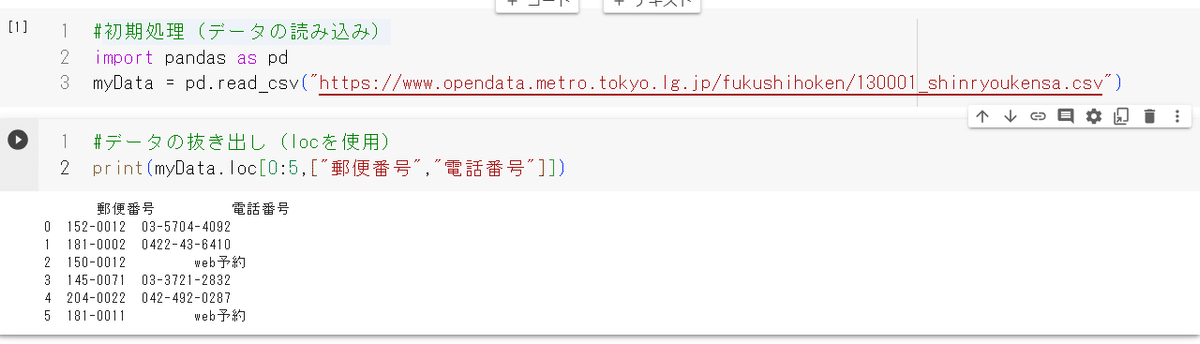
図4にあるように4843行もあるため、printだけすると「・・・」となり全部のデータが見えず閲覧性が悪い。そこで行名(カンマで複数指定)(図5)もしくは範囲(X行からY行までをX:Yであらわす)で閲覧する行を指定することが可能(図6)また、カンマでつなげれば複数の列を指定して表示させることも可能(図5,6)
locの後ろは大カッコ([ ]), 行と列を複数指定するときはさらに大カッコでくくってあげる。一方、行の範囲を指定する場合には大カッコは要らない。
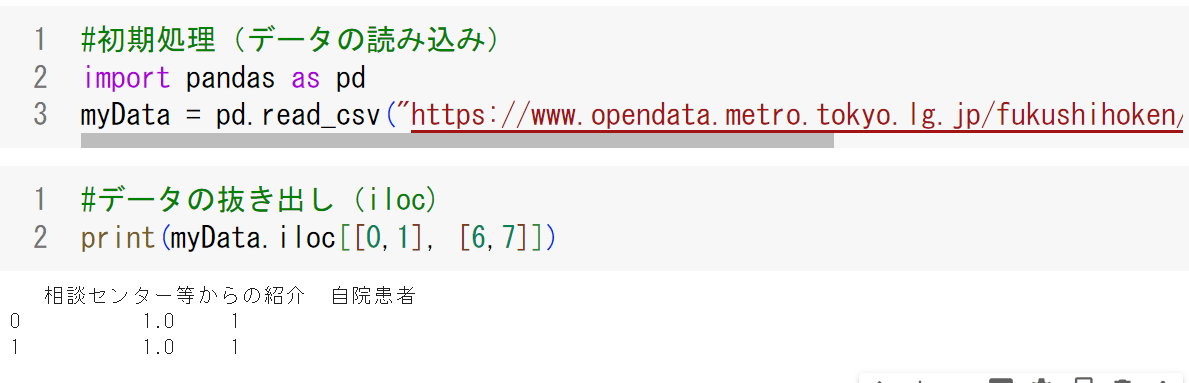
iloc(integer location)
行番号と、列番号で指定する。すなわち、
print(myData.iloc[[0,1], [6,7] ➡ 0行目、1行目x6列目、7列目
print(myData.iloc[0:5,2:4]➡ 0~5行目、x2~4行目講義に沿ってソースを書いて実行するが、データの読み込みの時点でエラーが出てしまう。前回と同じソースなのに。。。エラーの内容がHTTP error forbidden等々と書いてあったので、サーバーのメンテでもしているのかと勝手に推測して寝てしまった。翌朝トライしたらすんなり実行できた(図7)
範囲指定でも抜き出してみる。範囲指定の時は範囲を大カッコで囲む必要がない(図8)。小カッコ( )、大カッコ[ ], 波カッコ { }の使い分けが理解できていない。年齢とともに理解力、記憶力が衰えている。時間はかかるけどnoteに備忘ノートを書き連ねていく。
図3のように、範囲指定の場合は行を[0:5]で指定すると、2~6列、行を[0:4]で指定すると、A~D列が指定される。う~ん。ややこしい。

ilocで要注意なのが範囲指定の番号。Excelのケースに置き換えた、図9のケースでは列を[2:4]とするとC列、D列が指定される。行も[0:5]とすると2~6行が指定される。データが多くなってくるとややこしそう。

統計データと集計
基本的な統計情報はmyData.describe( )で表示が可能(図10)
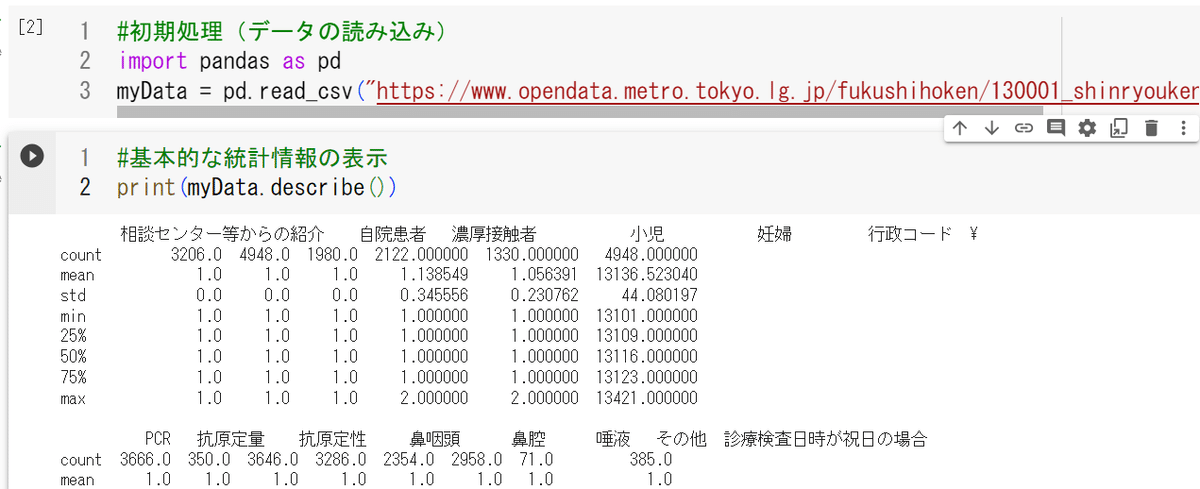
25%,50%,75%とあるのは、1/4分位数、中央値、3/4分位数のこと。
次は単純集計とクロス集計
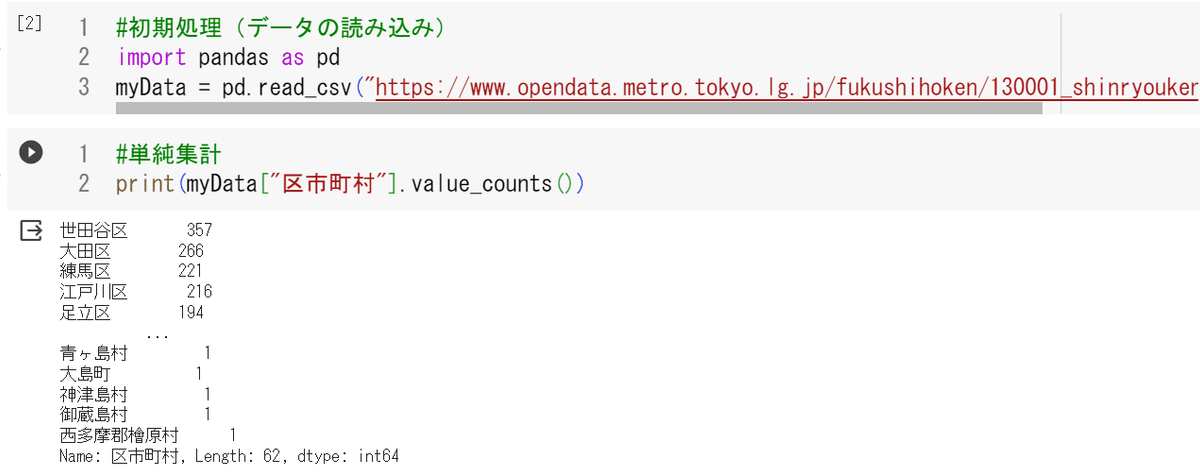
個数の集計はvalue_counts()で表示可能(図11)
クロス集計はpd.crosstab()で表示可能(図12)
value_counts( ), pd.crosstab( )の( )はこれは機能ですよという意味らしいがよく理解できず。

Pandasというライブラリの機能であるDataFrameのコマンドは⇩のリンクで確認可能
DataFrame — pandas 2.1.1 documentation (pydata.org)
ただし、DataFrame+やりたい事でGoogle検索をかけたほうが早い。ビジネスデータ処理の第10回はここまで来るのに3日。遅々として進まない。
操作結果の保存
DataFrameで処理したデータをどのように自分のPCに保存するか?DataFrameで処理したデータは1次元ならばSeriesで、2次元のデータならばDataFrameのデータとなる。
SeriesやDataFrameはto_csv(ファイル名)でCSVファイルとして保存が可能。ただし、Google Colabの場合はダウンロードの作業が必要
まずcrosstabにより得られたクロス集計のデータのタイプを確認するとDataFrameになっている(図13)

res.to_csv( )でcsvファイルに変換し、Colabo上に保存。f.downloadでPCにダウンロード

PCのダウンロードを開くと確かにダウンロードされている(図15)。

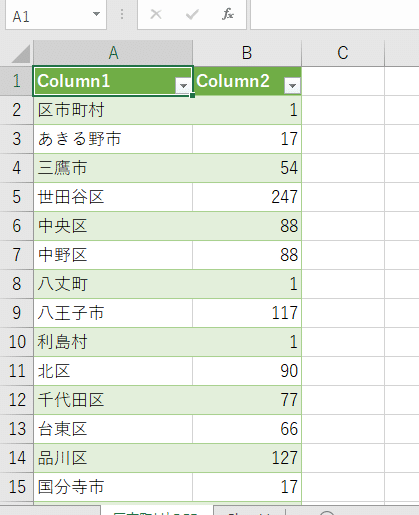
ダウンロードされたCSVファイルをそのままダブルクリックすると文字化けてしまう。(図16)

そこで空白のブックの「データ」タブの「テキストまたはCSVから」を選択し、ファイルを開くと、図17のような窓が出てきた。読み込みを押すと図18のように表示された。表示された表を見渡して東京には結構「村」があるのだなぁと感心してしまった。

グラフの表示
DataFrameにはグラフを描いてくれるプロットという機能がある。
集計結果がDataFrameであれば、簡単にグラフ化してくれるが、Google Colabでは日本語が文字化けする。
そこで、pipコマンドでjapanize-matplotlibという機能をインストール。pipはPythonに何かインストールをするコマンドと覚えておけばよい。
pipの前には感嘆符を付ける決まりがあるらしい(図19)。インストールが上手く行きました。

japanize_matplotlibをimportしてresを上と同様に規定して、plotコマンドで簡単にグラフができた。デフォルトが折れ線グラフとの事。軸も日本語になっている。

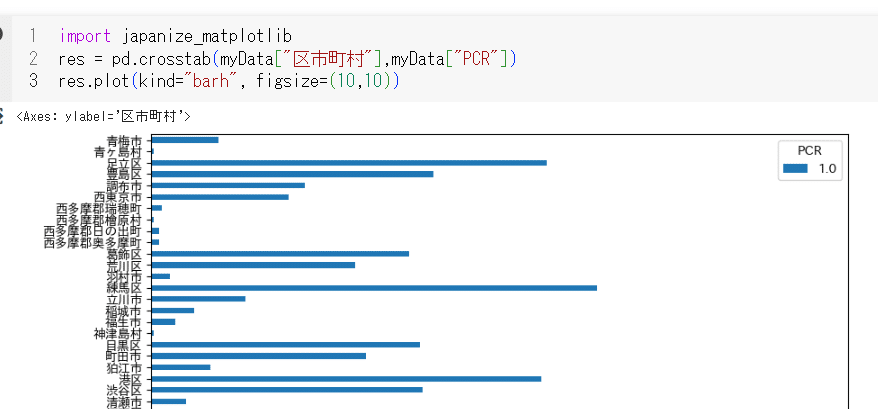
そこで、カッコの中にkind="bar"と棒グラフだよと指定してやると棒グラフで出る(barにはダブルクォーテーション付けないといけないようだ。つけずにやったらエラーが出ました。)(図21)

横棒は"barh" (多分bar horizontalから来ているのでは?)図21にあるように軸のラベルが重なってつぶれてしまうのでグラフのサイズも、figsizeというコマンドで変更してみる。(図22)
折れ線、棒グラフ以外にも様々なグラフに対応(図23)

ここまで来るのに5日がかりで、読み返さないと理解は難しそう。一方、グラフを描くにはDataFrameのプロット機能よりさらに高機能なMatplotlibやSeabornというライブラリも有るらしい。Seabornは機械学習にも使われ、されにきれいなグラフができる。Pythonのグラフ描画の解説ではどのライブラリを使っているかの確認が必要。
先生はMatplotlibやSeabornにも挑戦してみてねと言われていたがここで限界。
この記事が気に入ったらサポートをしてみませんか?