
OMDb APIとwikipedia APIを使ってウェブからデータをインポートする

DataCampのIntermediate Importing Data in Pythonを学習中です。
今回は②Interacting with APIs to import data from the webの内容を復習します。Open Movie Database (OMDb) APIやwikipedia APIを使用します。
APIとは
APIはApplication Programming Interfaceの略で、ソフトウェアアプリケーションを構築して相互作用するためのプロトコルとルーティーンのセット。
2つのソフトウェアプログラムが相互にコミュニケートすることを許す。APIを通じてデータを転送する基本形はJSON。
JSONとは
JSONはJavaScript Object Notationの頭文字。notationは表記法の意味。
必ずしもFlashやJavaに頼る必要のない、リアルタイムのサーバーとブラウザーコミュニケーション。人が読める形式。
コンマで区切られた、名前と値のペアで構成される。→JSONをPythonにロードする場合、辞書に格納する。JSONのキーは常に引用符で囲まれた文字列。
ローカルディレクトリからJSONをロードする
APIを使ってウェブからダウンロードする前に、ローカルディレクトリからJSONをロードする方法を学びます。
DataCampと同じデータを用意するために、まず、'snake.json'ファイルを作成します。OMDb APIのサイトに行き、Title:snakes on a planeで検索。ちなみに邦題は『スネーク・フライト』といい、飛行機の中で毒蛇が暴れる映画のようです。なぜこの映画をDataCampは選んだんでしょう?
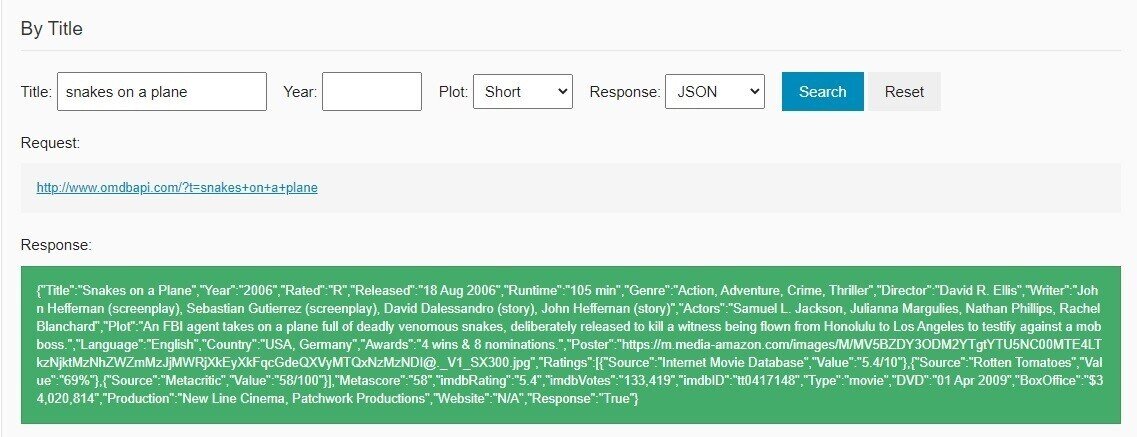
Responseをコピーしてテキストファイルに貼り付け、'snake.json'で保存。
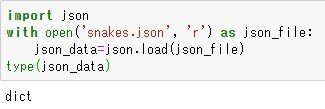
jsonモジュールをインポートし、ファイルへの接続を開き、json.load()関数でJSONをロードします。typeはdictです。
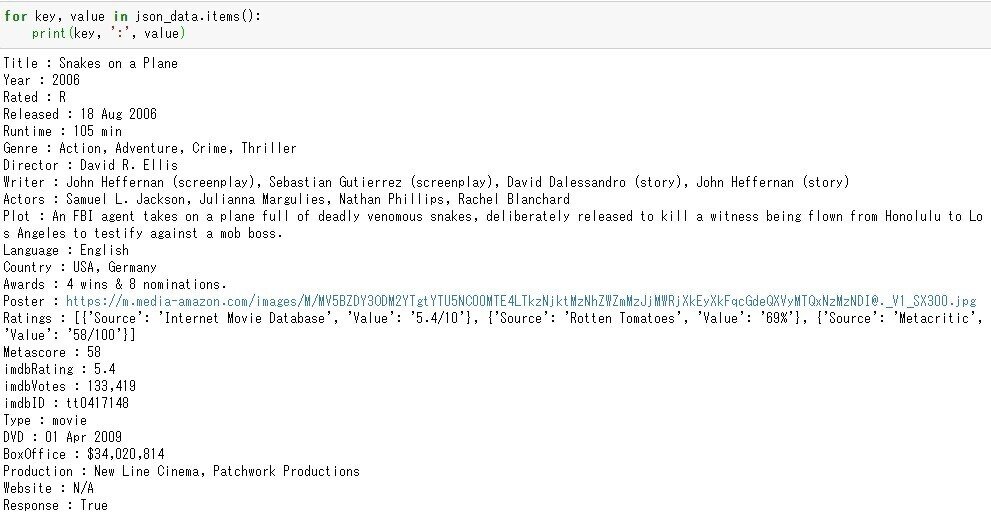
キーと値を出力。
PythonでAPIに接続する
いよいよAPIに接続します。例通りに実行すると…

あれ?API keyが与えられていません??
DataCampでは書かれていませんでしたが、APIを利用するには、API Keyが必要なようです。API Keyは1000日限定で無料で利用できるみたいです。1000日…3年弱。無料期間ではかなり太っ腹。

Twitter APIとは異なり、Useは短くても大丈夫です。そしてSubmit押してすぐメールが来たので、機械処理している模様。API Keyはメールで送られてきます。
クエリ文字列は ?apikey=*******&t=hackers とします。
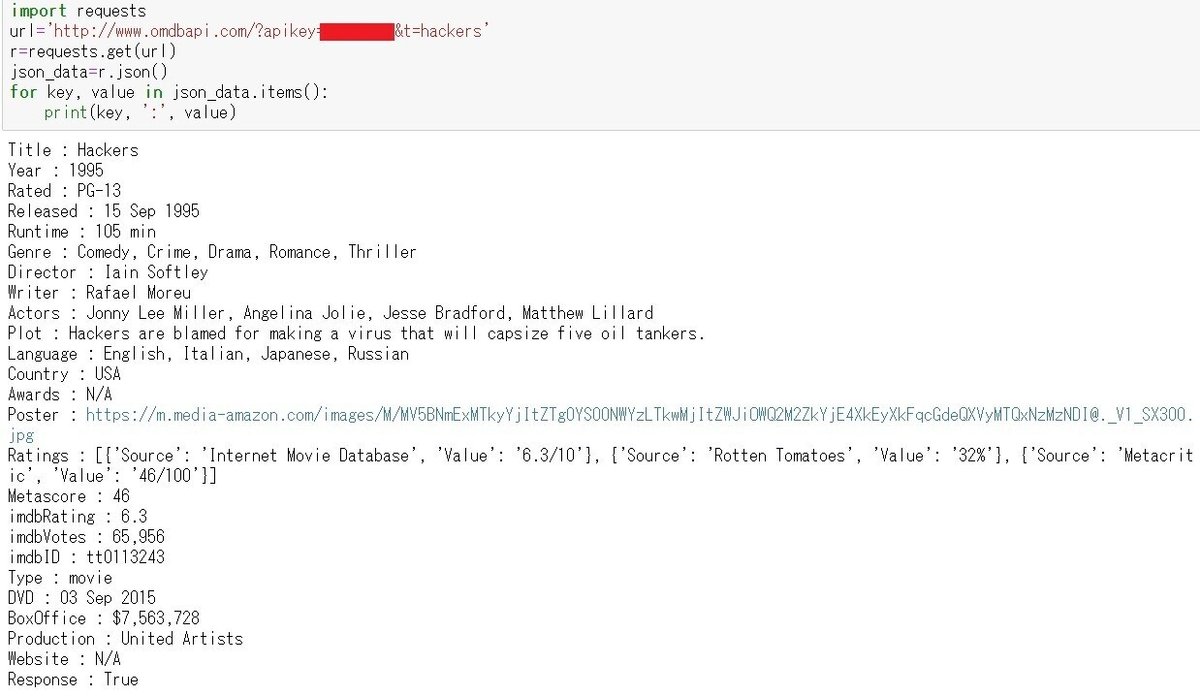
できました!
the social networkもこの通り!

wikipedia API
wikipedia APIを使って、pizzaのページからextractのHTMLを出力します。

pizza_extract = json_data['query']['pages']['24768']['extract']
print(pizza_extract)
wikipedia APIはAPI Keyなどなくてもできました。nested JSONなので分かりにくいですが。
URLは英語だと'https://en.wikipedia.org/w/api.php'から始まります。
action=query:操作
prop=extracts:記事の各構成要素を取得。解説(サマリー)
format=json:出力フォーマット
titles=pizza:記事のタイトル
print(type(pizza_extract))<class 'str'>
ちなみに、どんな構造になっているのか調べてみました。
print(json_data.keys())dict_keys(['batchcomplete', 'warnings', 'query'])
print(json_data['query'].keys())dict_keys(['normalized', 'pages'])
print(json_data['query']['pages'].keys())dict_keys(['24768'])
json_data['query']['pages']のキーは'24768'だけなんですね。30,000ページくらいあるのかと思った…
print(json_data['query']['pages']['24768'].keys())dict_keys(['pageid', 'ns', 'title', 'extract'])
Python (programming language)のページでは、同じコードを実行すると、
['batchcomplete', 'warnings', 'query']
['pages']
['23862']
['pageid', 'ns', 'title', 'extract']
となりました。少しずつ違いますね。
['pages']のキーがページによって異なるので、自動化できないか試しました。json_data['query']['pages'].keys()はdict_keysで、そのままでは使いづらいのでリスト化しました。
page=list(json_data['query']['pages'].keys())[0]
pizza_extract = json_data['query']['pages'][page]['extract']
print(pizza_extract)で抽出できました!!
ところで、pizzaのページからextractのHTMLを出力しましたが、読みづらいのでBeautifulSoupを使ってみましょう。

できました!
get_text()でテキストだけ抽出します。

かなり読みやすくなりました!
まとめると、extractのテキストを抽出する方法は
from bs4 import BeautifulSoup
import requests
title="Python (programming language)"
url='https://en.wikipedia.org/w/api.php?action=query&prop=extracts&format=json&exintro=&titles='+title
r=requests.get(url)
json_data=r.json()
page=list(json_data['query']['pages'].keys())[0]
extract = json_data['query']['pages'][page]['extract']
soup=BeautifulSoup(extract)
print(soup.get_text())titleの部分を変えると、他のページのextractも抽出できます。
この記事が気に入ったらサポートをしてみませんか?