
tabulaでPDFをDataFrameにする。

目的
モスバーガーの栄養成分表PDFをCSVにしたい。(その後はDB化して、Djangoで色々いじりたい)
Python
Javaをインストール。
コマンドプロンプトでtabulaをインストール。
プログラムを実行すると…
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8c in position 1: invalid start byte
encoding="shift-jis"で直りました。
import tabula
pdf_file = "nutrition.pdf"
df = tabula.read_pdf(pdf_file, pages=1, encoding="shift-jis")
print(df)
[43 rows x 21 columns]]
出力されました。Jupyter notebookで見たいなあ…。
そういえば、これ何の形式?と type(df) としたら

<class 'list'>
print(df[0])

Jupyter notebook
Anaconda promptに
pip install tabula-pyJupyter Notebookを開いて
import tabulaValueError: numpy.ufunc size changed, may indicate binary incompatibility. Expected 216 from C header, got 192 from PyObject
Anacondaを入れ直す。

DataFrameじゃなくてリストなので、きれいに表示されない。
どうしようかな~。
なんとなくdf[0]してみたら、あっさり解決しました。

よく分かりませんが、df[0]はDataFrameになっていました。

0-2行を削除

列も削除してスッキリ!

ん?エネルギーとたんぱく質が同じ列になっている!!

分割できました。

df1[["エネルギー", "たんぱく質"]]=df1.iloc[:, 2].str.split(pat=' ', expand=True)
df1=df1.drop("エネルギー たんぱく質", axis=1)
df1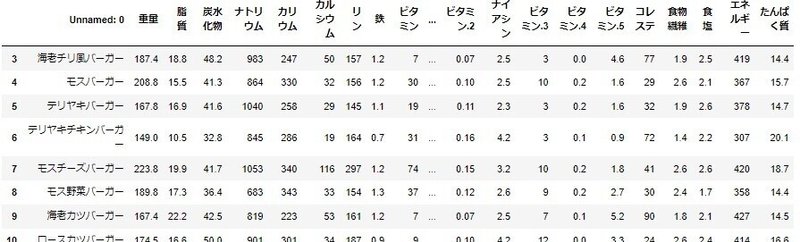
エネルギーとたんぱく質は最後の列になってしまいました。元の位置に戻したい。
これだと、全ての列名を書かなきゃいけない?めんどくさい。
列番号でどうにかならないかな?
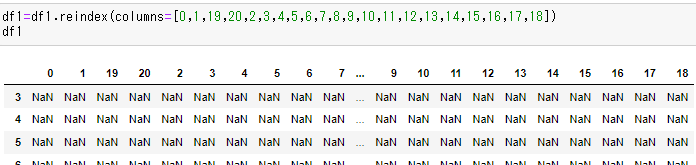
失敗。
ilocでできました。

列名に単位を足したいのですが、それは宿題にします…。
元のPDFを見ると、二枚目はライスバーガーやサイドメニューだったので、これも追加します。
こちらもエネルギーとたんぱく質が同じ列になっています。

モスキチンパック5本入りから、重量とエネルギーが同じ列になっていて、めんどくさいのでモスキチンまでのデータとします。(モスキチンパック5本入りとか頼まないし…)

44行中20行を抽出する…。抽出か、削除か。
今回は抽出にしてみました。1から25までの集合を作って、引きたい数の集合の要素を取り除く。


あとは上と同じ作業をしていきます。
表を結合。インデックスを削除してできた!


CSV化して…
df_new.to_csv('mos.csv')ちゃんとできていました。
![]()
この記事が気に入ったらサポートをしてみませんか?