[RDB]IN、EXISTS、JOINの実行プランを比較してみた

背景
前提知識の無い人が最初に触れる情報の精度はかなり大切だと思っていて、
新人教育を担当することもあり、以下のようなことを時々確認します。
・自分の知識が古くなっていないか
- 誤った情報を人に教えてしまうことがないか
・ググった時に出てくる情報がどんなものか
- 「ググれば分かる」と言える世界かどうか
今回たまたまSQLの確認をしていてEXISTSとINの違いについてちょっと気になる(疑わしい)情報が目についた、というのが背景です。
exists in でググってトップに出てくるのがこちら。
SQLのexistsとinの違いは、返り値とカラム指定するかどうか
気になった点
・「existsとinは、どちらも速度が遅い」
・JOINにすべきという話
・EXISTSの例とINの例で全く別なテーブル別なSQLを扱っていて、比較はしていない
(・大文字と小文字の一貫性が無い)
理論上そんなことないはずだけどな~と思いつつ、
記憶や経験則を根拠にするのは良くないので検証したいと思います。
使用した環境
・Windows 10 pro 64bit
検証したデータベース(少ないですが)
・SQLServer 2012 11.0.5058.0(手元にあったので)
・MySQL 8.0.26
良いサンプルが思いつかなかったのでデータベーススペシャリストの過去問から拝借。
データベーススペシャリスト平成24年春期 午前Ⅱ 問11

(いやぁヒドいもんですね……)
結論
先に結論を言ってしまいますが、EXISTSもINもINNER JOINも
たいてい実行プランが同じなのでパフォーマンスの違いはないです。
確認手順
手始めにSQLServerから。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [社員](
[社員番号] [int] NOT NULL,
[部門] [varchar](4) NOT NULL,
[社員名] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_社員] PRIMARY KEY CLUSTERED
(
[社員番号] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT [社員] ([社員番号], [部門], [社員名]) VALUES (11111, N'1000', N'佐藤一郎')
INSERT [社員] ([社員番号], [部門], [社員名]) VALUES (22222, N'2000', N'田中太郎')
INSERT [社員] ([社員番号], [部門], [社員名]) VALUES (33333, N'3000', N'鈴木次郎')
INSERT [社員] ([社員番号], [部門], [社員名]) VALUES (44444, N'3000', N'高橋美子')
INSERT [社員] ([社員番号], [部門], [社員名]) VALUES (55555, N'4000', N'渡辺三郎')
GO
CREATE TABLE [プロジェクト](
[プロジェクト番号] [varchar](4) NOT NULL,
[社員番号] [int] NOT NULL,
CONSTRAINT [PK_プロジェクト] PRIMARY KEY CLUSTERED
(
[プロジェクト番号] ASC,
[社員番号] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT [プロジェクト] ([プロジェクト番号], [社員番号]) VALUES (N'P001', 11111)
INSERT [プロジェクト] ([プロジェクト番号], [社員番号]) VALUES (N'P001', 22222)
INSERT [プロジェクト] ([プロジェクト番号], [社員番号]) VALUES (N'P002', 33333)
INSERT [プロジェクト] ([プロジェクト番号], [社員番号]) VALUES (N'P002', 44444)
INSERT [プロジェクト] ([プロジェクト番号], [社員番号]) VALUES (N'P003', 55555)
GO同じ結果が得られるSQLを3種類用意します。
IN、EXISTS、INNER JOINです。
SELECT
T1.[プロジェクト番号],
T1.[社員番号]
FROM
[プロジェクト] T1
WHERE [社員番号] IN (
SELECT T1I1.[社員番号] FROM [社員] T1I1
WHERE T1I1.[部門] <= '2000'
)
;SELECT
T1.[プロジェクト番号],
T1.[社員番号]
FROM
[プロジェクト] T1
WHERE EXISTS (
SELECT 1 FROM [社員] T1E1
WHERE T1E1.[社員番号] = T1.[社員番号]
AND T1E1.[部門] <= '2000'
)
;SELECT
T1.[プロジェクト番号],
T1.[社員番号]
FROM
[プロジェクト] T1
INNER JOIN
[社員] T2
ON T2.[社員番号] = T1.[社員番号]
AND T2.[部門] <= '2000'
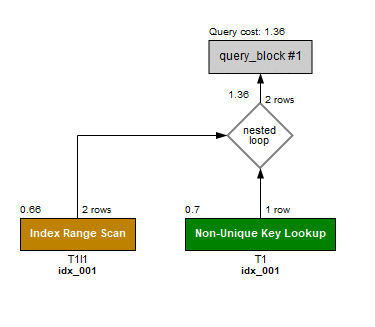
;実行プランはこのようになりました。

はい、完全に同じでs……じゃないですね。
3つの中でINNER JOINだけ実行プランが違います。
コストも若干高いです。
ただ、この状態ではインデックスが適切でありませんので判断するには早いです。[社員]テーブルは[部門]が、[プロジェクト]テーブルは[社員番号]が抽出条件になっていますね。
以下をキー列にしたインデックスを追加します。
・[社員].[部門]
・[プロジェクト].[社員番号]
SET ANSI_PADDING ON
GO
CREATE NONCLUSTERED INDEX [idx_001] ON [dbo].[社員]
(
[部門] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [idx_001] ON [dbo].[プロジェクト]
(
[社員番号] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
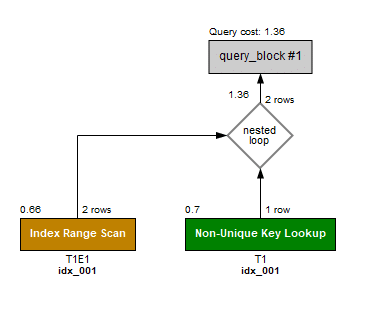
GOこれで改めて実行プランを見てみます。

はい、完全に同じですね。
※厳密には「実行ごとの予測行数」が違いますが。
MySQLは手元に無かったので公式からCommunityServerとWorkbenchをダウンロードしました。触るの自体も久しぶりだったので、こちらのブログを参考に構築しました。
Windows 10にMySQL 8.0をMSIインストーラを使わずにZipファイルからインストールする
省略しますがMySQLでも同じテーブル、インデックス、データ、SQLを用意して実行しました。
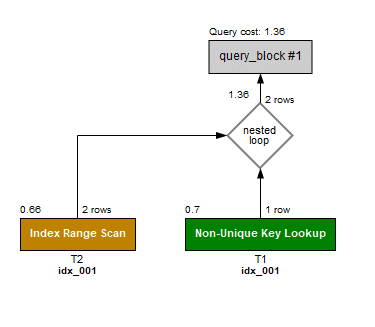
はい、同じですね。
SQLServerと違って[社員]テーブルがIndexRangeScanになっていますが、
[部門]を小なりイコールで絞っていますのでまぁ順当かと思います。
レコード数を増やした時にどうなるか確認すべきですね。別途時間をとって検証したいと思います。
EXISTSやINが遅いという説の出どころは、おそらくMySQLの相関サブクエリだと思います。
太古の昔、MySQLの相関サブクエリのアルゴリズムが悪かったらしく、極端に遅くなることがあったそうです。しかしながら5年以上前に私が初めてMySQLに触った時には既に解消されていましたので今は心配するところではありませんね。
まとめ
Q.EXISTSやINは遅くてJOINなら速い?
A.変わらん。
むしろtrueが得られた時点で走査が打ち切られるEXISTSが一番速い可能性が考えられます。今回はそこまで手が届いていませんが。
SQLのパフォーマンス比較をするなら、まず実行プランを比較しましょう。
以上。
この記事が気に入ったらサポートをしてみませんか?