
Google ColaboratoryでPythonを始める-10/DataFrameでのデータ抽出

こんにちはロック204チャンネルです。
この動画は「Google ColaboratoryでPythonを始める 10DataFrameでのデータ抽出」をお送りします。
この動画の内容は
・Excelのサンプルデータを読み込む
・比較演算子を用いたデータ抽出
・論理演算子を使用したデータ抽出
について解説します。
Excelのサンプルデータを読み込む
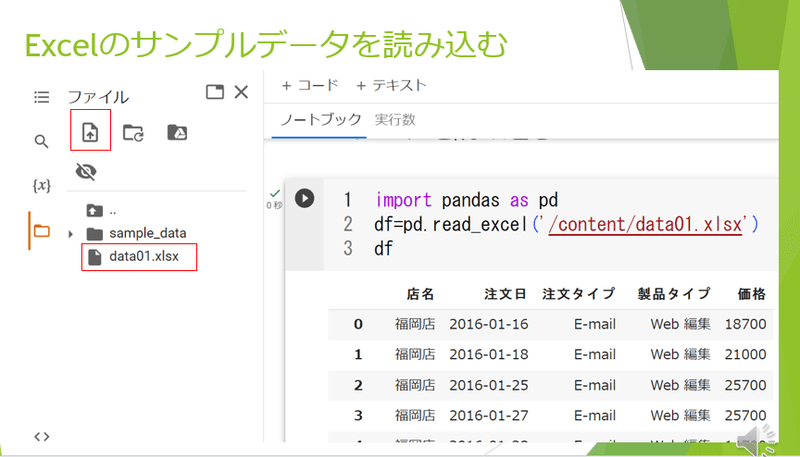
最初にexcelのサンプルデータをコラボに取り込んでいきます。
コラボ画面の左のサイドバーよりファイルアイコンをクリックし領域を広げます。
そしてuploadボタンを押しファイル選択メニューを開き、目的のエクセルファイルをクリックし開きます。
するとファイル表示領域にデータがアップロードされます。
このファイルをプログラムで用いるには、pandasモジュールを使います。
import pandas as pdでpandasを利用可能とします。
そしてdf=pd.read_excel(の中に文字列でファイルのアドレスを書き込みます。
ファイルのアドレスは 目的のファイルで右クリックしパスを入手しそれを貼り付けます。
比較演算子を用いたデータ抽出
比較演算子は右辺と左辺のデータを比較します。
等しい場合はイコール イコール
小なりの場合は不登校で<を入れます。
同様に大なりも不等号>を使用し比較します。
また以下、以上では小なりイコール、大なりイコールを使用します。
右辺と左辺が等しくない条件を設定するには、ダッシュイコールを使用します。

この例では店名が福岡店のデータを抽出する場合の例となります。
結果を入れるdf01の変数に取得したデータフレームdf角括弧の中にdf[‘店名’]==‘福岡店’と条件式を入力します。
そしてdf01で抽出されたデータフレームの結果を表示します。

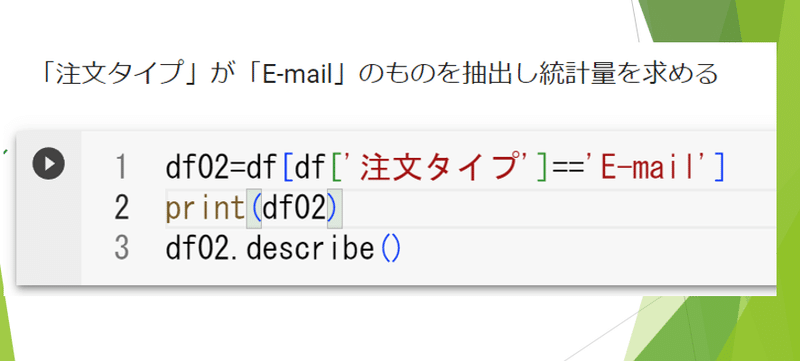
こちらは「注文タイプ」が「E-mail」のものを抽出し統計量を求める方法を示しています。
結果をdf02として、dataframe dfよりの条件としてdfの項目名が「注文タイプ」が「E-mail」であるものを「==」演算子で抽出しています。
二行で抽出されたデータを表示し
三行目で統計量を表示しています。
こちらは「店名」が「福岡店」以外のものを抽出する条件式となります。
df03に結果を入力します。
この場合の条件式はnot条件になりますので!=を使用し抽出を行います。

この例は「福岡店」のレコード数は全体の何パーセントかを抽出するプログラム例となります。
最初に変数fukuokaに「店名」が「福岡店」のものを抽出し そのレコード数をlen関数を使用し計算しています。
そして全体のレコード数はlen()関数の中に 元のDataFrame dfを入れて求めています。
そして三行目はprintでパーセント演算子を用いて それぞれのデータを表示しています。
「福岡店=」の後の%dは後ろの変数fukuokaを表示し
「全体=」の後の%dは変数bfの内容
「福岡県の割合=%f」のパーセントfは実数表記となります。
この部分はfukuoka割るbf0×100の式が対応します。

こちらは「価格」が1000円以下のものを抽出し統計量求めるプログラムになります。
変数bf4にDataFrame dfの中より価格が1000円以下のものを選び出し
二行目で統計量を算出しています。

論理演算子を使用したデータ抽出
複雑な抽出条件を使用するにはand条件、or条件、not条件を使用して行きます。
and条件は何なにかつ何なにと言うように二つの条件が成立した場合に使用して行きます。
この場合論理演算子は&マークを使用します。
or条件は何なにまたは何なにのような場合に使用します。
論理演算子は縦棒(|)を使用します。
この例ではa=1又はa=100の論理式を示しています。
ノット条件は~記号を使用します。
この例ではaが一ではないものを抽出する場合に使います。

論理演算子の使用例を示します。
「価格」が1000円より小さく かつ 「店名」が「福岡店」のものを抽出する場合のコードになります。
変数df3に結果を抽出します。
抽出条件はDataframe bf3に「価格」が1000円より小さく かつ 「店名」が「福岡店」のものを条件設定しています。
論理演算子は&マークを使用しています。

この例はor条件の例となります。
「店名」が「福岡店」または「大分店」の統計情報を求めるコードを書いています。
変数df4にdataframe dfより「店名」が「福岡店」または店名が「大分店」のデータを抽出するのが一行目となります。
この場合論理演算子は縦棒を使います。
二行目はデータフレームdf4の統計量を求めています。

最後に「福岡店」以外の平均値を求めるコードを示しています。
変数df5を用意しDataFrame dfより「福岡店」以外のデータを抽出しています。
この場合「以外」に当たる部分は~を使用しています。
そして括弧の中に「福岡店」を抽出し、~でそれ以外のデータと定義しています。
三行目は抽出されたdf5の平均値を求めるためmean()関数を使っています。

今回はDataFrameより比較演算子と論理演算子を使用したデータ抽出の方法を解説して行きました。
また抽出されたデータに対して統計量を求める方法についても説明しました。
次回はグラフを作成するプログラムについて解説します。。
ご視聴ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?