
ControlNet+ADetailer+α で立ち絵の表情差分を量産し服や手の差をなくす StableDiffusion WebUI API コード

概要
APIでControlNetとADetailerを利用して立ち絵量産し、指や服や髪型など細かい部分の差を埋めるプログラムです
環境はWindowsです


1. 準備
まず、Stable Diffusion web UIにControlNetのOpenPoseとADetailerを導入します
次にStable Diffusion web UIがインストールされているフォルダの webui-user.bat をテキストエディタで開いて set COMMANDLINE_ARGS に
set COMMANDLINE_ARGS=--apiと追記します
webui-user.batをダブルクリックしてStable Diffusion web UIを起動します
Settings→ControlNetの「Allow other script to control this extension」
にチェックを入れて上部のApply settingsを押します
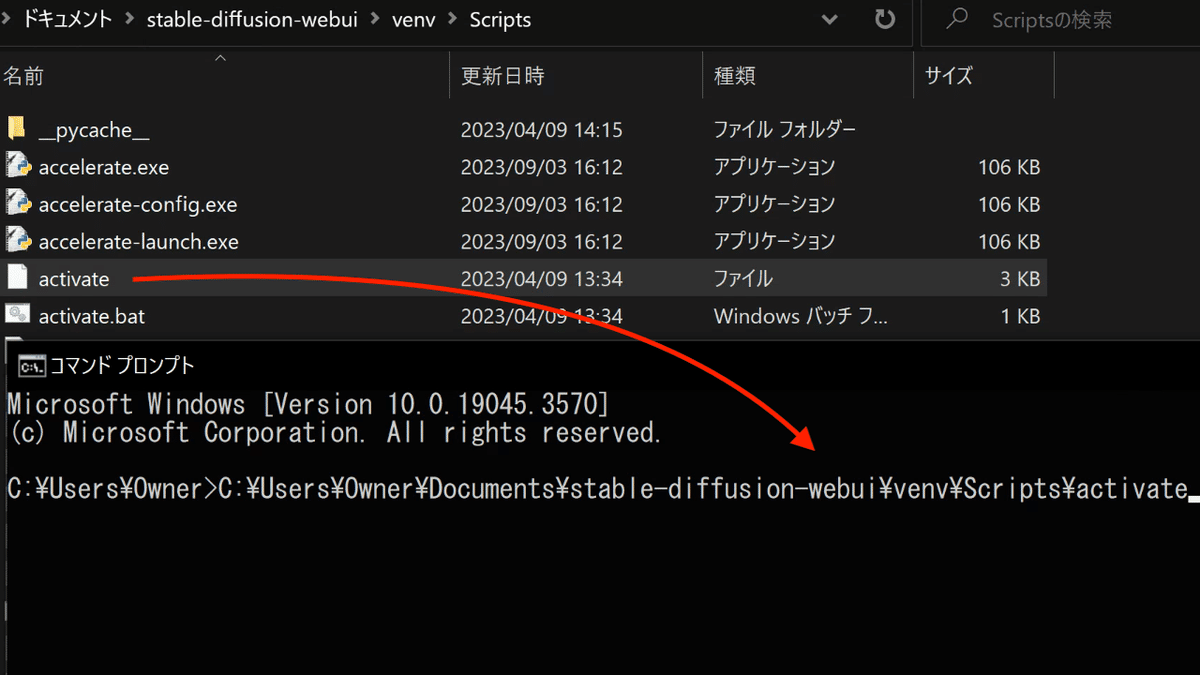
コマンドプロンプトを起動して、
stable-diffusion-webui/venv/Scripts
のactivateをドラッグドロップしてエンターキーを押します
openpose用の下の画像をダウンロードします。

2. まず表情違いの似た画像を量産
コードの全体
import requests
import base64
from pathlib import Path
from PIL import Image
import random
import datetime
import io
import time
url = "http://127.0.0.1:7860/sdapi/v1/txt2img"
faces=['smile','cry','angly','dismay,discouraged','surprise,open mouth','fear,pale','shy,blush','closed eyes','closed mouth','open mouth']
eyes = ['Red eyes', 'blue eyes', 'pink eyes','green eyes','brown eyes','purple eyes']
outpath = r"画像出力先フォルダのパス"
while True:
seed = random.randint(0,1000000000)
se = ['female','male']
se = se[random.randrange(len(se))]
eye = eyes[random.randrange(len(eyes))]
for face in faces:
with open(r"openpose画像のパス", "rb") as image_file:
data = base64.b64encode(image_file.read())
b64img = data.decode('utf-8')
p= f'({se}:1.3),{eye},standing,school uniform.,simple background'
np=' Negative prompt badhandv4 EasyNegativee'
if len(b64img)>0:
payload = {
"prompt": p,
"negative_prompt": np,
"seed": seed,
"subseed": -1,
"subseed_strength": 0,
"batch_size": 1,
"steps": 20,
"cfg_scale": 7,
"width": 512,
"height": 600,
"n_iter": 1,
"restore_faces": False,
"sampler_index": "Euler a",
#"enable_hr": True,
"denoising_strength": 0.7,
"hr_scale": 2,
"hr_upscaler": "Latent",
"alwayson_scripts": {
"ADetailer": {
"args": [
True,
{
"ad_model": "face_yolov8n.pt",
"ad_prompt": face,
"ad_confidence": 0.3,
"ad_dilate_erode": 50,
"ad_mask_blur": 4,
"ad_denoising_strength": 0.4,
"ad_inpaint_only_masked": True,
"ad_inpaint_only_masked_padding": 32
}
]
},
"controlnet": {
"args": [
{
"input_image": b64img,
"model": 'control_openpose-fp16 [9ca67cc5]',
"weight": 0.4,
"resize_mode": "Scale to Fit (Inner Fit)",
"guessmode": False,
"lowvram": False,
"processor_res": 512,
"threshold_a": 100,
"threshold_b": 200,
"guidance": 1.0,
}
]
}
}
}
response = requests.post(url=url, json=payload)
r = response.json()
dt_now = datetime.datetime.now()
d = dt_now.strftime('%y%m%d_%H%M%S')
image = Image.open(io.BytesIO(base64.b64decode(r["images"][0])))
destination = fr'{outpath}\{se}\{seed}'
dir_dest = Path(destination)
if not dir_dest.is_dir():
dir_dest.mkdir(0o700)
image.save(f'{destination}/{d}${seed}${eye}${face}.png')
time.sleep(1)使い方
上記コードをテキストエディタに貼り付けて sample1.py などの名前で保存します
activateをドラッグドロップしたコマンドプロンプトに「python」と入力して半角スペースを開け、作成したsample1.pyをドラッグドロップしてエンターを押します
ある程度生成されて終了したい場合はコマンドプロンプトの右上のXボタンを押します
outpath = r"画像出力先フォルダのパス"
例:C:\Users\Owner\Desktop\testに出力先のフォルダを指定します
with open(r"openpose画像のパス", "rb") as image_file:
例:"C:\Users\Owner\Downloads\pose.png"にopenposeの画像のパスを入力します
#"enable_hr": True,の#を消すとアップスケーラーがオンになります
サイズ等は希望の数値に変更してください
se = ['female','male']を
se = ['female']に変更すると女性のみ出力されます
プログラムのながれ
controlnetのopenposeで上半身が描画されるように指定
openposeを使用しないと頭が見切れて立ち絵として使える画像生成精度が落ちます
openposeの手を黒く塗りつぶすことで、キャラクターによって色々なポーズを出力させます
seed値と目の色を固定してADetailerで表情差分を出力
ADetailerは目の色を指定しておかないと表情によって違う目の色になってしまいます
髪型や服装などを細かく設定すると精度が落ちる印象です
faces=['smile','cry','angly','dismay,discouraged','surprise,open mouth','fear,pale','shy,blush','closed eyes','closed mouth','open mouth']この部分で表情を指定します。
必要であれば表情のプロンプトを追加・削除してください。
eyes = ['Red eyes', 'blue eyes', 'pink eyes','green eyes','brown eyes','purple eyes']ADetailerは目の色が変わってしまうことが多いので目の色だけ指定しておきます
追加で髪型や髪色を追加してもいいですが、プロンプトを追加しすぎると逆効果の場合が多かったです
ADetailerのad_confidenceの数値を変えると表情が大きく変わりやすいです
3. 服の微妙な差をなくすコード
準備
上記コードで出力した画像は、服や装飾に微妙な違いが生じてしまうので、出力画像を1枚選択して他の画像の顔のみ切り取り、ブラー(ぼかし)をかけて体に貼り付けます
下記ページからlbpcascade_animeface.xmlをダウンロードします。
*こちらはアニメ顔にしか対応していません
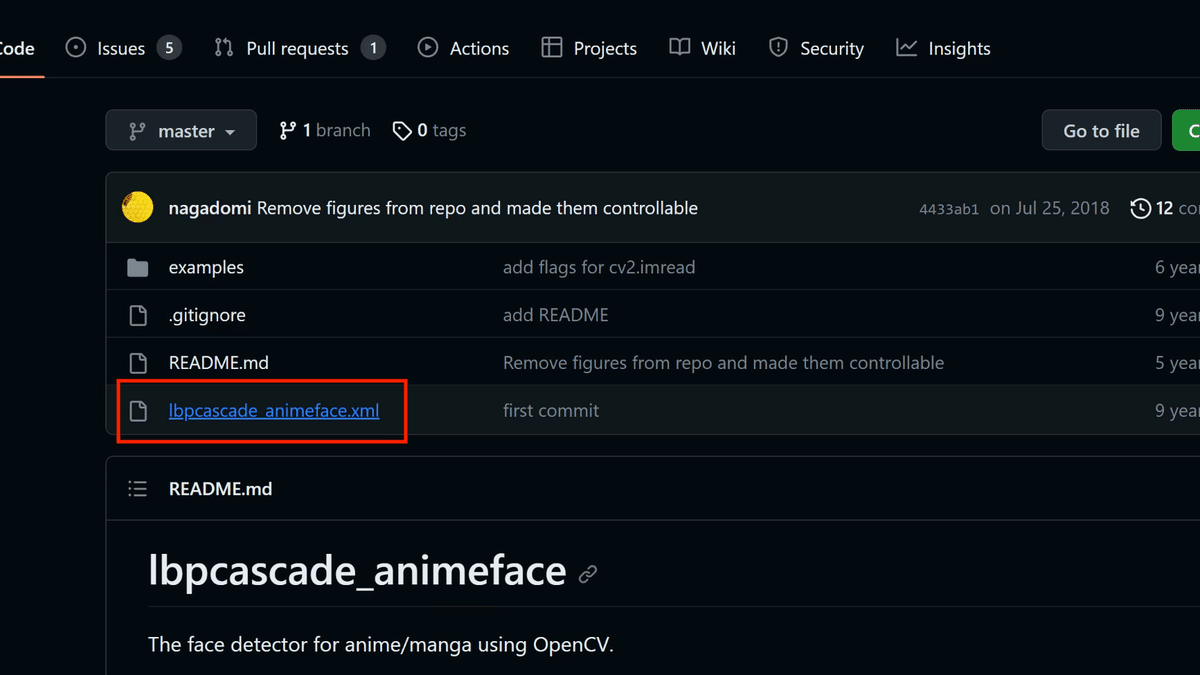

コマンドプロンプトを閉じた場合は、再度コマンドプロンプトを起動して、
stable-diffusion-webui/venv/Scripts
のactivateをドラッグドロップします
コマンドプロンプトに
pip install opencv-python
pip install opencv-contrib-python
pip install numpyを1行ずつ入力します
コードの全体
import numpy as np
import cv2
from pathlib import Path
# 顔検出器を初期化
face_cascade = cv2.CascadeClassifier(r"lbpcascade_animeface.xmlのファイルパス")
imgs = []
# コード2. で出力された画像が入っているフォルダ
for file in Path(r'出力された画像が入っているフォルダのパス').glob('*.png'):
imgs.append(file)
# 顔貼り付け先に使用する画像
img_body = cv2.imread(r"顔貼り付け先に使用する画像のパス")
# 出力先フォルダ
out_fol_path = r"出力先フォルダのパス"
for img in imgs:
img_face = cv2.imread(str(img))
# 顔を検出
gray = cv2.cvtColor(img_face, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray,
# detector options
scaleFactor = 1.1,
minNeighbors = 5,
minSize = (24, 24))
if len(faces)>0:
# マスクを作成
mask = np.zeros(img_face.shape[:2], dtype=np.uint8)
# 顔の領域をマスクに書き込む
for (x, y, w, h) in faces[:1]:
cv2.rectangle(mask, (x-10, y-10), (x+w+10, y+h+10), 255, -1)
mask_inv = cv2.GaussianBlur(mask, (51, 51), 0)
mask_inv = cv2.cvtColor(mask_inv, cv2.COLOR_GRAY2RGB)
#mask_inv = cv2.bitwise_not(mask_inv)
#img = img_a * (mask_inv / 255)
alpha = mask_inv / 255.0
#alpha = alpha[:, :, np.newaxis]
result = (img_body * (1 - alpha) + img_face * alpha).astype(np.uint8)
#img = mask_inv
# 結果を保存
cv2.imwrite(fr"{out_fol_path}\fc{img.stem}.png", result)
使い方
上記コードをテキストエディタに貼り付けて sample2.py などの名前で保存します
activateをドラッグドロップしたコマンドプロンプトに「python」と入力して半角スペースを開け、作成したsample2.pyをドラッグドロップしてエンターを押します
終了したい場合はコマンドプロンプトの右上のXボタンを押します
# 顔検出器を初期化
face_cascade = cv2.CascadeClassifier(r"lbpcascade_animeface.xmlのファイルパス")
上記からダウンロードしたxmlのパス# コード2. で出力された画像が入っているフォルダ
for file in Path(r'出力された画像が入っているフォルダのパス').glob('*.png'):
imgs.append(file)
例:r"C:\Users\Owner\Desktop\test\female\963920796"# 顔貼り付け先に使用する画像
img_body = cv2.imread(r"顔貼り付け先に使用する画像のパス")
例:r"C:\Users\Owner\Desktop\test\female\963920796\231002_122513$ 963920796$purple eyes$smile.png"# 出力先フォルダ
out_fol_path = r"出力先フォルダのパス"
例:r"C:\Users\Owner\Desktop\test\female\963920796"cv2.rectangle(mask, (x-10, y-10), (x+w+10, y+h+10), 255, -1)の数値を変更すると顔マスクの範囲を変更できます
例:cv2.rectangle(mask, (x+100, y+100), (x+w-30, y+h-30), 255, -1)4. プログラミングが分からない人へ
AIツールやAPIへの興味があるけどプログラミングが分からない方へ
Pythonを習得すると世界が変わります
Pythonを学べば今回紹介したような画像の量産だけでなくChatGPTのAPIでブログ記事を量産したり、今後動画生成AIや音楽生成AIでも有利になるかと思います
プログラミング経験が全くない方におすすめの本
Python入門には「Python1年生」がオススメです
書店でも目立つところに置いてある人気な本で、第1版の内容が修正・加筆された第2版が販売中です
とにかく絵が多く先生と生徒の会話で書かれているので読みやすくPyhonを始めるにはうってつけの本です
ただ読むのではなく実際にプログラムを書いて実行してみることをオススメします
2冊目は、こちらの本がおすすめです
様々な機能が細かく説明されています
初めは分厚さと文字の多さに嫌気がさしましたが、読んでみるとスイスイ読み進められました
資格を取るわけてもプロになる訳でもないので全ての機能を頭に入れる必要はありません
あんな機能やコードが載っていたな〜程度で十分です
こちらの本も実際にコードを書いて実行すると頭に残りやすいのでオススメです
Pythonで何ができるかだけ覚えておけば、その後実際に本を見返すことで使いたい機能やコードを確認できます
APIを利用するのみであれば、不必要そうな部分はとばして読んでも問題ありません
この記事が気に入ったらサポートをしてみませんか?