
高性能多言語埋め込み

こんにちは。レトリバの飯田(@HIROKIIIDA7)です。新技術研究開発室で
チームのリーダーをしています。このブログでは、SimCSE[1]、DiffCSE[2]など、教師なし文表現の紹介を行ってきました。近年、ついに多言語で使用可能な埋め込み表現 ME5が現れ、話題となっているため、今回はそのベンチマークを日本語で行いました
ME5について
ME5はE5(EmbEddings from bidirEctional Encoder rEpresentations)の多言語版です。E5[3]はテキストをベクトルに変換するエンコーダで、 こちらのブログでも紹介されているとおり、 CCPairsという埋め込み表現訓練用のコーパスを作成し、それを用いて対照学習を用いて埋め込み表現の事前学習を行います。 その後、NLIやMS MARCOといった既存の人手でつけた教師データを複数用いて、対照学習で埋め込み表現の学習を行います。
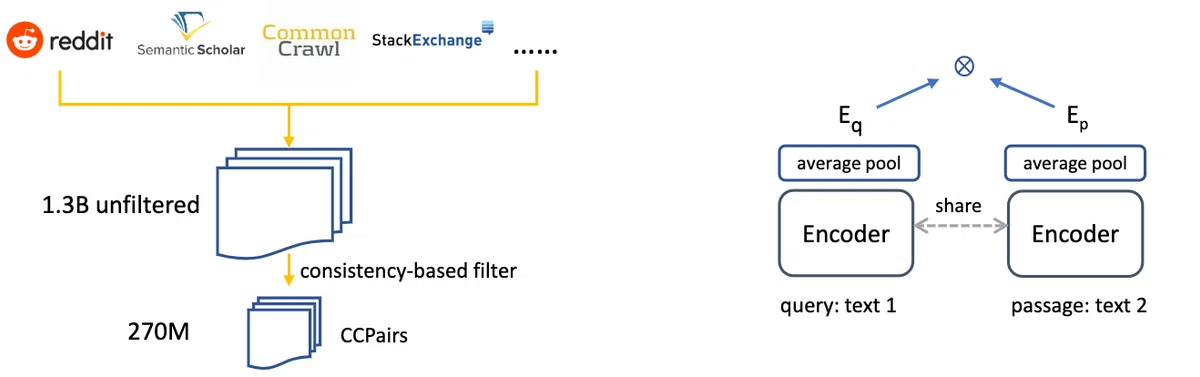
CCPairsは、Reddit・Stackexchangeといったサイトの投稿と返答のペアや、Wikipedia・科学論文のタイトルと要旨のペア などのテキストのペアを集めたコーパスです。元々は1.3B程度のテキストペアが存在しますが、 これをフィルタリングして、比較的高品質な270Mのテキストペアにしています。 フィルタリング方法は、一度1.3Bのテキスト対で学習したのち、その学習したモデルを用いて検索タスクを行い、 元々のテキスト対を上位k件にランキングできたペアのみを残すことでフィルタリングしています。 これにより、ノイジーなテキストに対するモデルのオーバーフィットを防いでいます。
E5は、Zero-shot検索のベンチマークデータセットであるBEIR[4]や クラスタリング・分類などの埋め込み表現を用いる多数のタスクのベンチマークデータセットであるMTEB[5]で 既存のよりパラメータ数が多いモデルよりも高い精度を達成しています。 ただし、BEIRのいくつかのタスクでは、CCPairsが結果的に教師データを使用しているのと同様の設定になっていることには注意が必要です。 このようなことから、論文の示唆としては、テキストの埋め込み表現の学習において、 マルチタスク学習が個別のタスクの精度低下をあまり引き起こさないということが言えそうです。 詳細は論文をご覧ください。
ME5はE5のマルチリンガル版であり、モデルカードを見る限りでは、 自動収集されたテキストペアにmC4などのマルチリンガルコーパスを追加するともに、 人手の教師データにもマルチリンガルなものを加えて学習しています。
ベースラインモデル
今回の検証では、ME5のモデルとしてintfloat/multilingual-e5-largeを使用します。比較モデルとして、前回用いたDiffCSEに加え、pkshatech/simcse-ja-bert-base-clcmlpとOpenAIのtext-embedding-ada-002を使用します。なお、text-embedding-ada-002を除き、平均プーリングを使用しています。
ベンチマークタスク
前回DiffCSEで用いた文類似度タスク、クラスタリングに加えて、検索タスクを使用します。
文類似度タスク
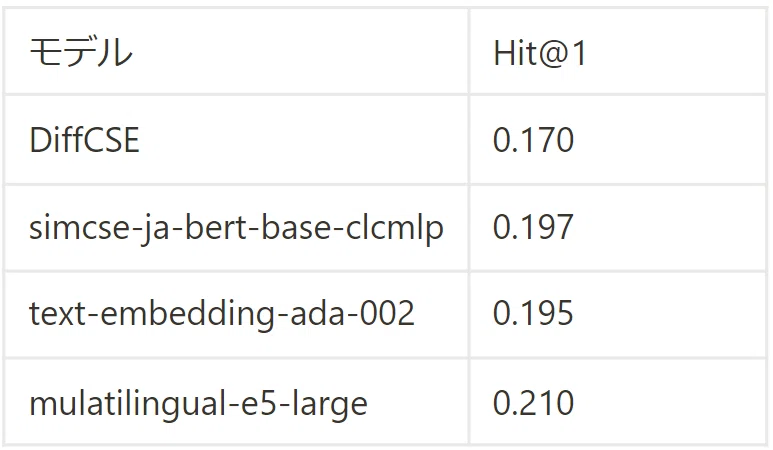
評価にはJSTSタスク[6]のvalidationデータを用いて実験を行いました。 評価方法は、こちら[7]の論文に従い、評価データ中で類似度が上位25%のデータで作成された文集合に対して、1文をクエリとしてcos類似度で順位づけをし、元々のペアがtop1に来ている割合(Hit@1)を用いています。
結果は以下の表のとおりです。ME5が最も良い値を示しています。 simcse-ja-bert-base-clcmlpが2番目に良い値を示しています。 simcse-ja-bert-base-clcmlpは、JSNLI[8]という日本語の自然言語推論のデータセットでチューニングされています。 自然言語推論のデータセットは文類似度タスクに有効なデータであることが知られています。 そのため、比較的高い精度を示していると考えられます。
クラスタリング
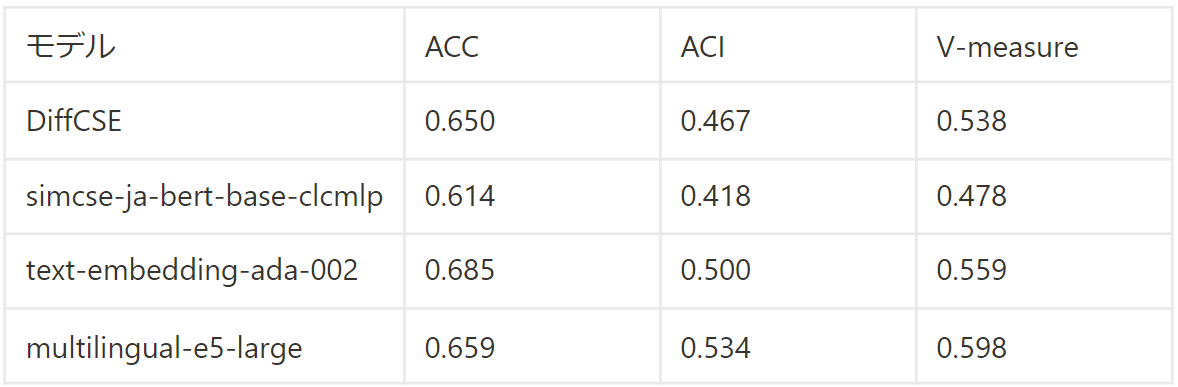
livedoorコーパスを用いた、クラスタリングによる結果を掲載します。クラスタリングアルゴリズムはk-meansを使用しています。クラスタ数はこのコーパスの分類数である9としています。 評価尺度については、以前のSimCSEの記事をご覧ください。
結果は以下の表のとおりです。こちらでもME5が最も良い精度となっています。ただし、ACCではtext-embedding-ada-002が最も良い値を示しています。 一方、文類似度タスクにおいて、2番目によかったsimcse-ja-bert-base-clcmlpがDiffCSEよりも低い値になっており、 全指標で最も低い値になっています。他方、DiffCSEは教師データを用いていませんが非常に高い精度となっています。 クラスタリングでは、トピックなど比較的粒度の情報で人の感覚と合致しているかどうかが重要になると考えられます。
これに対して、ランダムな負例を用いることが寄与したと推察されます。そのため、simcse-ja-bert-base-clcmlpも より多くのデータで学習することで、精度の向上が期待できます。
検索タスク
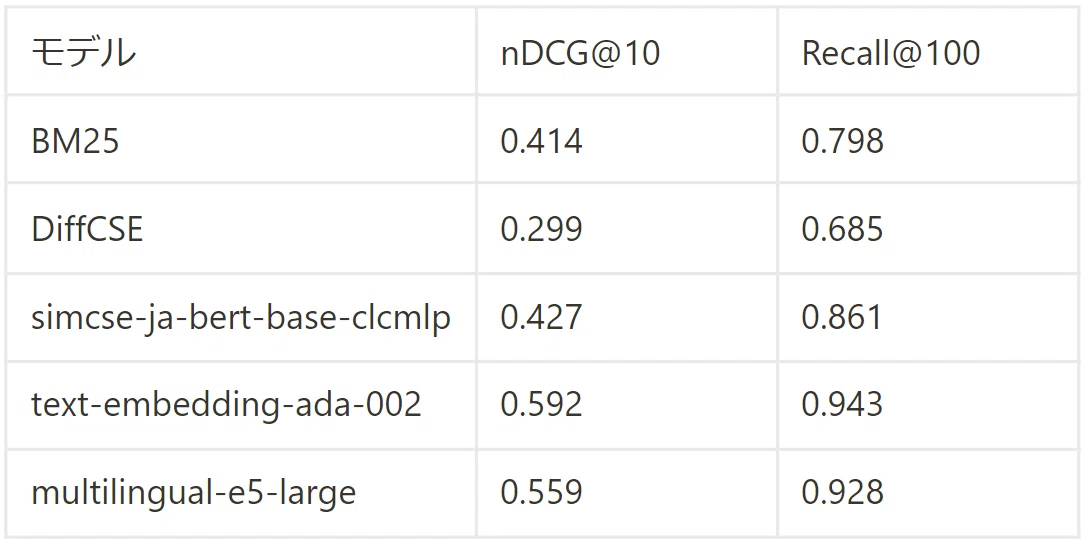
検索タスクとして尼崎市のQAデータ[9]を使用します。評価指標は、当該論文とは異なり、nDCG@10とRecall@100を使用しました。検索のデータセットであるため、ベースラインとしてBM25の結果も載せています。
結果は以下の表のとおりです。こちらでは、text-embedding-ada-002が最も良い値を示しています。 また、依然として ME5も非常に高い値を示しています。 さらに、興味深いことに、simcse-ja-bert-base-clcmlpも BM25を上回っており、 単語マッチでは比較的正解になりにくいデータセットであることが伺えます。
一方、こちらのデータセットでは、DiffCSEの精度が非常に低くなっています。 検索ではより細かい判別が必要になります。 DiffCSEにはそのような細かい判別ができていないことが伺えます。
まとめ
近年公開された、ME5という文表現の埋め込みモデルに対して、日本語データでベンチマークを行いました。 ベンチマークしたデータセットにおいては非常に高い精度を示しており、まず使ってみるには非常に良いモデルであると思います。
埋め込み表現も、大量のデータを用いて学習する重要性がME5で明らかになったと思います。 埋め込みも遂にmulti-lingualができるようになり、数年前とは隔世の感があります
余談ですが、ME5自体はMITライセンスなのですが、MS MARCOなどは研究用途限定なので、それで学習されたモデルのライセンスは果たして??
参考文献
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Text Embeddings by Weakly-Supervised Contrastive Pre-training
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Just Rank: Rethinking Evaluation with Word and Sentence Similarities
FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance