
早いと噂のStable Diffusion WebUI Forge試してみた

こんにちは、Rcatです。
今回は画像生成AI Stable Diffusionの高パフォーマンス版が出たということで、早速試していきたいと思います。
Stable Diffusion WebUI Forgeとは
Stable Diffusion WebUI Forge(以降Forge)は、既存のWebUIを高速化した物のようです。つまり、今まで使ってきた人なら簡単にこちらに乗り換えることができてしまいます。
推論の高速化とメモリの使用量軽減が図られているようです。
vramの少ない型落ちのGPUを使っている私にはありがたい存在です。
とはいえ、文字で色々言われても分からないので、とりあえず使ってみましょう。
実験条件
GPU
RTX2060 6GBモデル
SakuraMixサンプラー
DPM++ 2M Karrasサンプリングステップ
20サイズ
512×768生成枚数
5枚アップスケーラー
R-ESRGAN 4x+ Anime6B 1.7倍
Forgeのインストール方法
下記からダウンロードすることができます。
https://github.com/lllyasviel/stable-diffusion-webui-forge
私はgitコマンドをインストールしているので、下記のように任意のフォルダでコマンドを実行して入手しました。
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.git後で確認しましたが、Download ZIPのボタンでも全く同じものが入手できます。

入手が完了したら一番下のバッチを実行すれば立ち上がります。
中身にSHファイルがあるので、どうやらLinuxでもOKみたいですね。
初回はセットアップの時間もあるので、環境によってしばらく時間がかかります。
しばらくまではいつものUIが表示されるようになるはずです。
WebUIが立ち上がったら、後はいつも通りフォルダの中にモデルとvaeを入れてポチるだけです。
その辺も普通のWebUIの方と全く同じなので戸惑うことはありません。

WebUI Forgeの実力
早速Forgeを試していきましょう。
まずはアップスケールなしでの生成結果です。
1枚あたり約5秒で終了しています。
画像生成の間隔が多少空くので5×5秒ではないですね。
とりあえず40秒程度で5枚生成することができました。
To load target model BaseModel
Begin to load 1 model
[Memory Management] Current Free GPU Memory (MB) = 4746.2412109375
[Memory Management] Model Memory (MB) = 1639.4137649536133
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 2082.8274459838867
Moving model(s) has taken 0.38 seconds
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:06<00:00, 3.28it/s]
Memory cleanup has taken 0.64 seconds████████████████████████████████████████████████| 100/100 [00:36<00:00, 3.30it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 100/100 [00:38<00:00, 2.56it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 100/100 [00:38<00:00, 3.30it/s]
次にアップスケールを込みの場合です。
1枚あたり40秒程度で生成ができました。
To load target model BaseModel
Begin to load 1 model
[Memory Management] Current Free GPU Memory (MB) = 4719.02294921875
[Memory Management] Model Memory (MB) = 1639.4137649536133
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 2055.6091842651367
Moving model(s) has taken 0.37 seconds
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:25<00:00, 1.28s/it]
Memory cleanup has taken 0.83 seconds████████████████████████████████████████████████| 200/200 [03:16<00:00, 1.28s/it]
Total progress: 100%|████████████████████████████████████████████████████████████████| 200/200 [03:22<00:00, 1.01s/it]
Total progress: 100%|████████████████████████████████████████████████████████████████| 200/200 [03:22<00:00, 1.28s/it]

ネガティブに何も入れてないので、ちょっと微妙な感じになっちゃいましたw。プロンプトの内容は仲良し姉妹の微笑ましい光景です。
旧WebUIの実力
1枚あたり10秒ほどで、生成が完了しました。
画像生成の間の間隔があるので、ぴったり50秒ではないですね。
しかし、これだけ見てもforgeは倍くらい早くなっていることがわかります。こんなに差があるとは思いませんでした。
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.92it/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.94it/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.94it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 100/100 [00:55<00:00, 1.79it/s]次にアップスケール込みで試したんですが、Forgeではできた設定がこちらではかなりきつそうです。
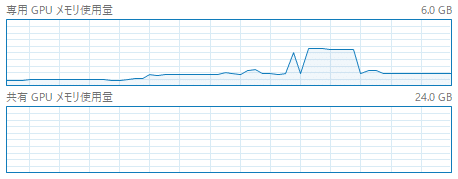
というのもアップスケールはメモリを大量に使うので、GPUの専用メモリを使い切ってしまい、システムの共有メモリまではみ出ています。
そしてこうなった瞬間激おそになるのがこのAIなんですよね…。
共用メモリのグラフ上限は24GBなので、大体6Gくらいはみ出ていたということでしょうか…。

ちなみにForgeの時は以下のようなグラフになっていました。
なんとメモリを半分も使っていません。
遅すぎて5枚やっていないのですが、1枚当たり9分かかってます。なんとForgeの13倍以上時間がかかっています。
もう少し設定を緩やかにして、GPUメモリ内に収めてあげればもう少し早く生成できるとは思いますが、そもそも同じ条件で実行できないというところでも差が現れていますね。
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.93it/s]
Total prTile 1/1510%|██████▌ | 20/200 [00:19<01:28, 2.02it/s]
Tile 2/15
Tile 3/15
Tile 4/15
Tile 5/15
Tile 6/15
Tile 7/15
Tile 8/15
Tile 9/15
Tile 10/15
Tile 11/15
Tile 12/15
Tile 13/15
Tile 14/15
Tile 15/15
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [07:59<00:00, 23.97s/it]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.93it/s]
Total prTile 1/1530%|███████████████████▌ | 60/200 [09:21<01:13, 1.90it/s]
Tile 2/15
Tile 3/15
Tile 4/15
Tile 5/15
Tile 6/15
Tile 7/15
Tile 8/15
Tile 9/15
Tile 10/15
Tile 11/15
Tile 12/15
Tile 13/15
Tile 14/15
Tile 15/15
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [08:30<00:00, 25.51s/it]
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:10<00:00, 1.89it/s]
Total prTile 1/1550%|████████████████████████████████ | 100/200 [18:22<00:51, 1.93it/s]
プロンプトの入力は上と同じ。
今まで使えなかったモデルが使えるようになった
だいぶ前のことですが、emiというモデルを使ってみようとしたことがあります。
しかし、こちらモデルのサイズが大きく読み込みまではできるんですが、生成ができない状態でした。具体的にはスタートボタンを押すと走るんですが、途中で落ちるんです。vramが足りないから仕方ないかと諦めていたんですが、そこに登場したForge。これは使ってみるしかない!!。
生成結果はこちら
なんと普通に生成できちゃいました。
なかなかに独特な絵柄ですね。

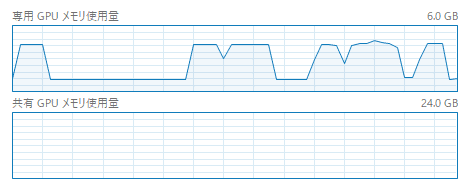
ちなみにメモリの使用状況はこちら。
先ほどまでのアップスケールよりもさらにメモリを使用しています。さらにここからアップスケールとなるとちょっと厳しいでしょうか?

と思ってやってみたのですが、なんかあんまり変わりませんね。
一番後ろが普通の先生の山で、その前の山がアップスケールの山です。
これを見る限りアップスケールの大きさを大きくしたところで、メモリを使用量は増えないということでしょうか?

蛇足…アップスケールMAXでも動くのか
生成サイズを変えずに、UpscalerのスケールをMAXの4倍にしてみました。
(モデルは戻してsakuramixです)
4倍にすると高さが3000超えますね…行けるでしょうか

結果…10分かかりましたがいけました!
o load target model BaseModel | 0/20 [00:00<?, ?it/s]
Begin to load 1 model
[Memory Management] Current Free GPU Memory (MB) = 4712.58935546875
[Memory Management] Model Memory (MB) = 1639.4137649536133
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 2049.1755905151367
Moving model(s) has taken 0.45 seconds
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:04<00:00, 4.70it/s]
Memory cleanup has taken 0.67 seconds█████████████████ | 20/40 [00:04<00:04, 4.69it/s]
Cleanup minimal inference memory.
tiled upscale: 100%|███████████████████████████████████████████████████████████████████| 15/15 [00:01<00:00, 12.59it/s]
To load target model BaseModel
Begin to load 1 model
[Memory Management] Current Free GPU Memory (MB) = 4956.85400390625
[Memory Management] Model Memory (MB) = 1639.4137649536133
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 2293.4402389526367
Moving model(s) has taken 0.65 seconds
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [07:31<00:00, 22.59s/it]
To load target model AutoencoderKL█████████████████████████████████████████████████████| 40/40 [08:13<00:00, 22.63s/it]
Begin to load 1 model
[Memory Management] Current Free GPU Memory (MB) = 4951.59619140625
[Memory Management] Model Memory (MB) = 319.11416244506836
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 3608.4820289611816
Moving model(s) has taken 0.73 seconds
Total progress: 100%|██████████████████████████████████████████████████████████████████| 40/40 [09:54<00:00, 14.86s/it]
To load target model BaseModel█████████████████████████████████████████████████████████| 40/40 [09:54<00:00, 22.63s/it]
メモリの使用状況はこの通り。
完全に共用メモリにはみ出てますが、それでもMAXのアップスケールに耐えてしまいましたね…。ちなみにメモリは48Gです。
元ネタ

4倍化
大きくしたはいいけど崩れてますね…。
できるけどやり過ぎは良くないと…。

APIは使えるのか
下記の記事で紹介したDiscordBOTは、WEB UIのAPIを用いてDiscord経由での画像生成を可能にしています。
こちらとForgeの連携ができれば使用可能ということになります。
結果…使えました。
もともとWEB UIをベースにしているだけあってその辺は変わらないようですね。

ちなみにCPUで使えるのか試してみた
下記の記事でCPUで画像生成を行っているのでForgeでも試してみました。
結論から言うと駄目です。
エラーの中に出てくる"CUDA"というのはNVIDIA製のGPUつまりGTXとかRTXとかそういったグラボのためのプログラミング言語です。それ関係でエラーが出ていることから、Forgeが最適化を行っているのはGPUの内部処理のようで完全にGPU専用のものとなっているようですね。
Cannot locate TCMalloc. Do you have tcmalloc or google-perftool installed on your system? (improves CPU memory usage)
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0]
Version: f0.0.17v1.8.0rc-latest-273-gb9705c58
Commit hash: b9705c58f66c6fd2c4a0168b26c5cf1fa6c0dde3
Legacy Preprocessor init warning: Unable to install insightface automatically. Please try run `pip install insightface` manually.
Launching Web UI with arguments: --skip-torch-cuda-test --precision full --no-half --listen
Traceback (most recent call last):
File "/SSD/stable-diffusion-webui-forge/launch.py", line 51, in <module>
main()
File "/SSD/stable-diffusion-webui-forge/launch.py", line 47, in main
start()
File "/SSD/stable-diffusion-webui-forge/modules/launch_utils.py", line 541, in start
import webui
File "/SSD/stable-diffusion-webui-forge/webui.py", line 17, in <module>
initialize_forge()
File "/SSD/stable-diffusion-webui-forge/modules_forge/initialization.py", line 50, in initialize_forge
import ldm_patched.modules.model_management as model_management
File "/SSD/stable-diffusion-webui-forge/ldm_patched/modules/model_management.py", line 122, in <module>
total_vram = get_total_memory(get_torch_device()) / (1024 * 1024)
File "/SSD/stable-diffusion-webui-forge/ldm_patched/modules/model_management.py", line 91, in get_torch_device
return torch.device(torch.cuda.current_device())
File "/SSD/stable-diffusion-webui-forge/venv/lib/python3.10/site-packages/torch/cuda/__init__.py", line 769, in current_device
_lazy_init()
File "/SSD/stable-diffusion-webui-forge/venv/lib/python3.10/site-packages/torch/cuda/__init__.py", line 289, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabledまとめ
今回は高速化が素晴らしいForgeを使用してみました。
正直もう少し遊びたいならGPUを買い換えないとなあと思っていたんですが、どうやらその必要はなさそうですね。今までスケールアップをすることすら難しかったのがこちらを使用することで全く問題ないレベルになっています。
GPUを積んでいる人であれば、こちらに乗り換えは確実でしょう。
それではまたお会いしましょう。
情報が役に立ったと思えば、僅かでも投げ銭していただけるとありがたいです。