
【競馬】機械学習の素人がPOG攻略法を求めて悪戦苦闘した1ヶ月の記録
競馬POGファンと機械学習に関心のある方に何らかの利益があると信じて書きます。
競馬には馬券でお金を儲ける以外にも楽しいゲームがあり、それをPOG(ポグ、あるいはピーオージー)と呼びます。競馬ファン以外の読者もいらっしゃる可能性があるので、POGについて少し解説。
POGとは、紙の上での仮想の馬主ゲームです。実際にお金を払うことなく、身内や競馬サイトコミュニティなどにおいて、セレクトした馬の一定期間の獲得賞金で競います。
基本的には競馬の花形である日本ダービーを終点として、デビュー前の馬をピックアップして、その1年間での獲得賞金をカウントします。
中でも最も大規模なPOG大会と思われる「JRA-VAN POG」を本記事では対象とします。1位賞金50万円、2位賞金20万円など、賞金総額300万円と頑張ればお金が稼げます。結局お金が絡んできます笑
当大会の特徴的なルールとして以下があります。
指名馬の選択・変更については当該馬の初出走日前日の23時59分まで選択・変更が可能ですが、それ以降は選択・変更ができなくなります。
これは特徴量の選択にも関わってきます。デビューの前日までの情報ならば特徴量として使えるということです。
(競馬ファンで機械学習に詳しくない方は、特徴量=ファクターだと思ってください)
機械学習の素人なりの戦略
まず私は機械学習については全くの素人であり、ふとPOG予測してみたいと思ったのが、2020年4月末のこと。
というのも、血統と配合にかねてから関心があり、そのデータ取得のためにスクレイピングをやるためにPythonを触ったのが3月。
例えば、サンデーサイレンスのクロスを3×4、4×3などパターン別の成績データなどに使える。
そしてPythonと競馬となると、機械学習ネタを目にすることも多く、POGで予測とかできちゃうの?!と機械学習の学習を始めた。
そこから何度も現れる小さな問題から根本的な問題まで、書籍やWeb、直感を頼りに対処してきた。
2020年の日本ダービーもコントレイルの圧巻のパフォで終わりを迎え、次のPOGのスタートが近づく中でいったん1ヶ月の試行錯誤の過程を記したい。
POG予測というテーマは、あまり活発ではないようで、直接的に参考にしたネタはわずかですが、少なからず同志は存在したようです。
POG予測の目的変数は何がいいのか?
まず悩ましいところが目的変数の設定です。
考えられる選択肢
1.獲得賞金額の予測 (回帰)
2.ある一定以上の賞金を獲得するか否か (分類)
3.獲得賞金の順位予測
このあたりかと思われますが、回帰で軽くやってみてもかなりゴールは遠そうでしたので、今回は2の”ある一定以上の賞金を獲得するか否か (分類)”を採用しました。(この境界線の設定がまた難しいところですが。)
というのも、そもそも「JRA-VAN POG」で上位入選するには細かい賞金予測は重要ではなく、たった数頭しかいないG1馬をチョイスしたいわけです。
アルゴリズムの選択
分類の問題で比較的評判の高い?ランダムフォレストを選択。GBDTなどKaggleで人気な手法についてはパラメータ等の煩雑さが時間対効果が悪そうなので見送り。今後の学習としたい。
POGデータの不均衡さ
たった数頭しかいないG1馬をできるだけたくさん拾わなければ、大会上位に組み込めないのです。
しかし肝心のG1は期間内に8レースしかないため、最大でもG1馬は8頭しかいない。
それに対して、毎年約4000頭ほどがデビューする。もちろんデビューできない馬も含めれば7000頭ほどになる。その中から8頭を選び抜くのが理想形ではあります。
2018世代の賞金ヒストグラフを見ると、

G1馬に限らずとも、1億円以上稼ぐ’当たり’がいかに少ないかがわかると思います。G1馬:その他 = 0.2 : 99.8という比率になります。
こうしたアンバランスなデータの処理ってどうすべきなの?って調べると「不均衡データ」の扱いということで類型化されているようです。
その他の記事や論文などを総合すると、POGデータのような不均衡なデータに際しては以下のようなアプローチがあるようです。
1.コスト考慮型学習
- 多数派の誤分類よりも、少数派の誤分類のペナルティを重くすることでrecall(再現率)の向上を目指すようです。
2.サンプリングの工夫
・Oversampling
- 少数派のサンプルを増やす
・Undersampling
- 多数派のサンプルを減らす
3. 異常検知の文脈で立ち向かう
具体的に何をすればいいかはわかりませんでした。
(危機管理系で異常値を見つけ出す場合に使われるようですが)
しかしサンプリングの工夫は極端な不均衡データにおいてはあまり効果がないという記述をちらほら見ていると、以下のようなスライドを発見。
https://www.slideshare.net/sfchaos/ss-11307051
スライド30ページにあるBalancedRandomForestClassifierなるものを活用すればランダムフォレストの各ツリーで正例と負例の数を揃えて学習してくれるらしい。
特徴量の取得
スクレイピングの技術が不足しており、適宜欲しいデータが取れないので、普段から愛用している競馬Target Frontier JVよりデータをCSV出力で取得した。
2017、2018年デビューの2世代のデータを約6000頭分の行を取得。
とにかくアルゴリズムに投げるまでの一連を体感したいということで取得したのがこれら。
・父年齢
・母年齢
・取引価格(万円) (取引なしの馬は「−1」に設定)
・誕生日数 (1月1日を始点とした誕生日までの日数)
・生産者 (いっぱいいるのでノーザンファーム・社台ファーム・その他に分類)
・調教師 (一人一人をラベルづけ)
・馬主 (一人一人をラベルづけ)
・所属 (地方を除外)
・供用先 (種牡馬の供用先をJBISよりスクレイピング)
・父タイプ (Targetの種牡馬分類を使用)
・母父タイプ (Targetの種牡馬分類を使用)
・初戦時期 (各年06月01日を始点にカウント)
・クラスタID
(種牡馬の産駒傾向を成績からクラスタ分類しラベルづけ)
以下のような分類で、なかなか実用性ありそうでは?
(亀谷さんがやってるPサンデーとかに近いです)
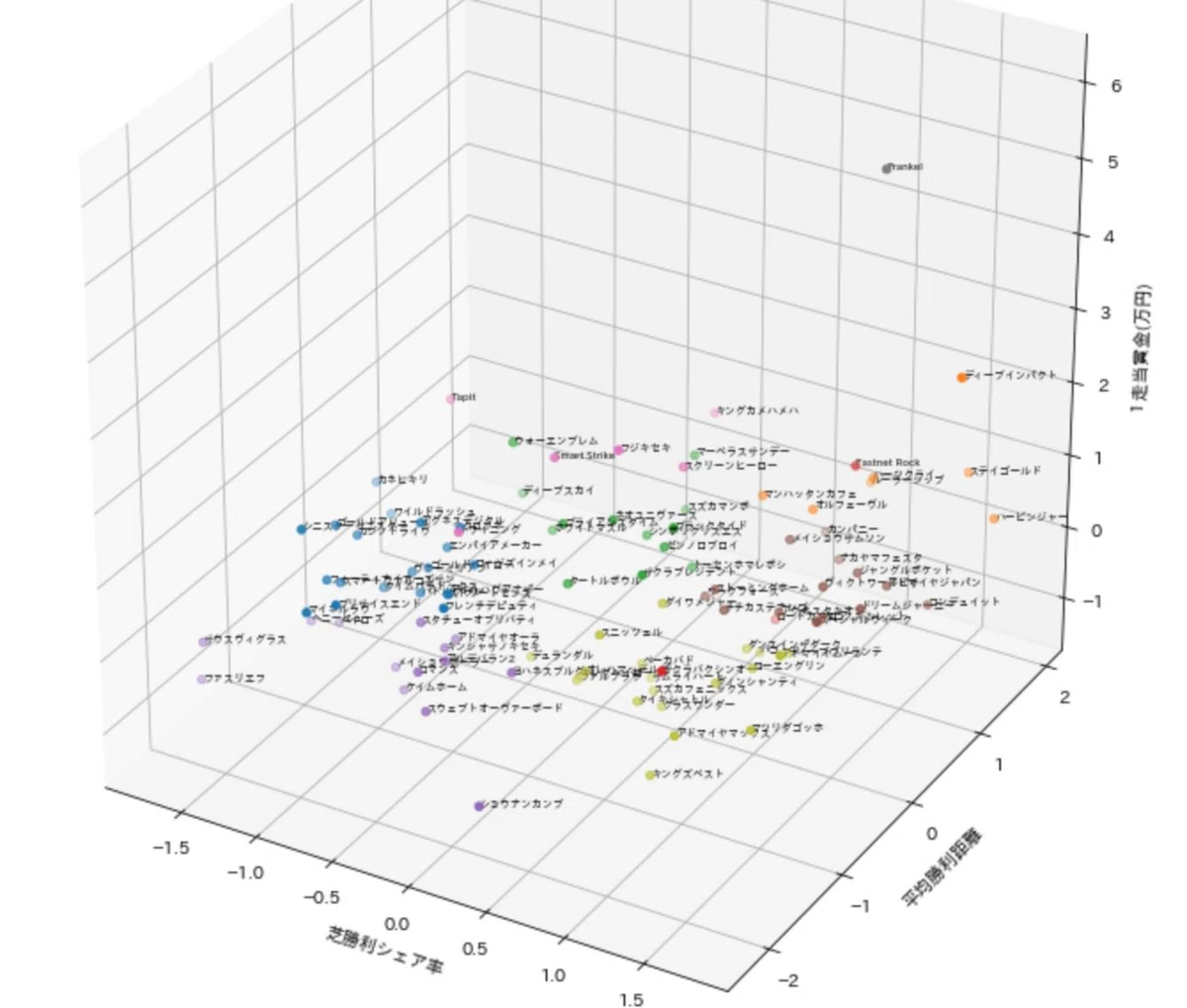
兄弟5頭平均本賞金(万円)
(※1.こいつが厄介で現時点での兄弟馬たちの賞金が取得されるので実際に、各馬がデビュー前の兄弟賞金とは異なります。
つまり、後々の兄弟馬の活躍を加味してしまいます。
この点については後ほど説明追記)

特徴量の加工の判断についてはJRAVANのマイニング指数の仕組みを参考にした。(https://jra-van.jp/fun/dm/mining.html)
そして目的変数の賞金の境界については1億円以上とそれ未満とした。
これでランダムフォレストにかけたところrecall(再現率)=0.18と撃沈。
やっぱりそんなに甘くない。
さて6月のPOG開幕までに何らかの成果を世に打ち出せるのか!と自身に問うたところ、こりゃキツイ何らかの妥協が必要だという判断に。
目標の妥協
POG予測器でPOGを上位入選できれば、何らかの仕事がもらえるのでは?という浅はかな野望を押し殺し、父親をディープインパクトに限定して困難を分割してみることにした。
実際のところPOGで馬選びするときは、まぁまずディープ産駒から良いのを選ぶのが基本線でしょうから、限定したとはいえ実用性はあるだろうと。
とはいえ、ディープ産駒だけではデータ数が少ないので
今回は2011年デビューから2018デビューの8世代分のデータをTargetより取得。
さらに、精度向上のためには、目的変数の妥協も必要に思われた。
本当に拾いたいG1級の馬はやはり少なすぎて、データの不均衡さが極端なので、それを和らげる為に獲得賞金上位25%を正例とした。

このようにディープ産駒の賞金上位25%の境界は、1223万円です。

この目標設定により、目的変数の割合は3:1になり、極端な不均衡さは解消されます。
まぁ1200万円以上ではまだまだ不十分ですが、ディープ産駒のハズレを引かないという意味では役立ちそうという望みを胸に突き進む。
特徴量の改善
とまぁ、これらの2つの妥協策だけでは精度向上もわずかなので、特徴量の質と量を改善した。
まずはJRA-VAN POGの出走前日まで馬指名ができるという点を考慮し、デビュー戦に関連した特徴量を加えることにした。
・初戦馬体重 (これは実際に前日には取得不可ですが大まかな情報は得られるので)
・初戦surface (ディープ産駒なので大半は芝デビューですが念の為)
・初戦距離
・初戦月(特に近年は早期デビュー馬の活躍が目立ちますから重要そう
なお3才時のデビューは一括で-1とした)
・初場所 (所属と相関高いが念の為)
(いずれもTargetより取得可能)
また以下のような記事を参考にして、木系のアルゴリズムでは特徴量のBin詰めも有効っぽいので、
初戦馬体重、初戦距離、初戦月、誕生日数など、1単位ごとの差の違いが重要でないものをBins加工した。
そして母父タイプ名や生産者など、最初はOne-Hot-Encoding処理していたのですが、どうも木系はできるだけスパースを避けた方がいいらしいので、Label-Encodingを施した。
また同様に要素の種類の多い、調教師や馬主については、Label-Encodingではなく、POG期間内の重賞での獲得賞金(過去5年分)の値で置換した。
再再再再・・・・実施
これでバランスランフォレにかけてみる
X = x_neo.values
y = test5['賞金上位25%'].values
X_train, X_test, y_train, y_test = train_test_split(X, y,train_size=0.7 ,random_state=0)
brf = BalancedRandomForestClassifier(n_estimators=100, random_state=0)
brf.fit(X_train, y_train)
# テストデータのyの予測値を求める
y_predicted = brf.predict(X_test)
ともかくRecall値を高めて、当たりを取り逃がさないことが重要なので、Recall値が0.76%と、ここに書いていない中でも何度も試行錯誤した中で、一番高い値が示された。
果たしてこの数値の価値とは?
今の状況を整理する。

テストデータに回った299頭について、実際には賞金上位25%が71頭いるうち54頭を拾えて、17頭を逃している。
また賞金上位25%だと予測したうち、80/134(約60%)は間違いデータが含まれている。
これは実際にどう活用できるでしょうか?
とり逃した獲物にG1級がいない保証はないですから、過信は禁物ですし、なおかつ予測したうちの60%のハズレは避けつつも、なおかつ残りの40%からG1クラスの馬をアナログに見つけ出す必要がある。
(これ以降のプロセスにも機械学習を加えるのは今後の課題としたい)
とはいえ、逃した獲物に後ろ髪を引かれつつも、余分な約60%の馬はフィルタリングで落として省力化できる。
POGで重要なファクター
ランダムフォレストは幸い特徴量の重要性が出ますから、そのメリットを享受しましょう。

割と実感と合致する結果だと思います、これ。
調教師のPOG期間の重賞賞金が最も高く出ていますが、やはり友道、池江、藤沢の3人は他を圧倒していますからね。
馬主のPOG期間重賞賞金も3番目に高いですが、 サンデーレーシング
キャロットファーム 、シルクレーシング 、 金子真人ホールディングス 、サトミホースカンパニー が圧倒的なのでそうでしょう。
問題は兄弟5頭平均賞金ですが、※1でも言及しましたが、Targetの運用上現時点での賞金が表示されるので、あまりスマートではないのです。
時系列が混在してしまっています。
ある馬がデビューする前の兄弟賞金データと向き合うのがリアルな状況ですが、そうしたデータの取得技術は持ち合わせていません。
しかしTargetとPyhtonを駆使すれば、ある馬の年上の兄弟の賞金だけをカウントすることはできました。それでも賞金自体は今時点からのカウントでリアルではないですが、少なくとも年下の成績をカウントしてしまうことは回避できました。
これによって母の初子であるかどうかも特徴量として取得できます。
しかし、そのようにできる限り現実の状況に近づけたデータに置き換えると、再現率の値が70%まで低下してしまいました。
実際の運用
このようにPOGの攻略とはほど遠いが、今後も改善を重ねながら、デビューする馬たちを予測器にかけ、予測をBlogなどで発信していく。
問題としては、初戦関連のデータが毎週木曜日にしか得られないため、今から一気に予測器にかけるようなことはできない。
また馬体重がわかった時には、POG指名期間を過ぎている。ということはテストデータには初戦馬体重の列は作れない。
このように学習データとテストデータで異なる列がある場合はどう対処すればいいのか?
まぁともかく動かしていきます。
今後の展望
POGというゲームのツボの提示
さらに精度向上させて、特徴量の重要性の信頼も上がれば、POGというゲームにおいて何が重要なのか、が分かる。
それはひいては、馬の生産に関わる方たちにとっても、より早い時期から賞金を稼いでくれるような経済効率の良い馬の作り方のヒントとなるかもしれない。
精度向上の継続
1年に1度しか結果が出ないゲームではあるが、各馬については年内であればデビュー前までにいつでも指名できるので、精度向上を続ける価値はある。
確率的な予測
今回は2値分類という形をとっているが、正例であることを確率的に予測できれば、馬Aよりも馬Bの方が5000万円以上稼ぐ確率が高い!みたいな判断ができ、より実用的なものとなるはずでその方策を探りたい。
おそらくロジスティック回帰がそれに当たると思うが、ここは今後の学習課題としたい。
血統・配合論のデータ化の困難さ
これはPOGに限った話ではなく、競馬予測AIでも同じだろうが、血統データの扱いが非常に難しい。
種牡馬レベルならそこまで種類が多くないが、母父レベルになると一気に種類も増えるので、頻度の少ないものを「その他」扱いにすることになる。
1つ1つのもつ意味が消えてしまう。
またPOGで重要性が増すのが、配合論だ。望田潤という血統評論家の配合論は魅力的だし、実用的だと思うが、それを特徴量として変換するのは困難だ。
配合をデザインした生産者の意向を学習データに組み込めないのは問題があるだろう。
ひとつひとつのレースに際して、配合論の重要度は決して高くないと思うが、POGのように年単位である馬がどの程度のクラスの馬になるかという予測では、かなり有用だと思う。
泥臭い方策としては、望田氏のような専門家の配合評価を点数化して取り込む、みたいなところか。
機械学習と向き合った1ヶ月
何も成し遂げていないし、まだまだこれからだが、機械学習の雰囲気はかんじられたような気がする。
特徴量の作成・選定が非常に煩わしくそれこそ機械がやってくれ、という感じはする。
あとはどんなゲームを解こうとしているのか、そこは常に意識するべき点だと感じた。
しかしこの機械学習がいじれるからといって、どう他者と差別化できるのだろうという感覚は常につきまとった1ヶ月だった。素人の自分でさえ形だけならば、一応動かせるのだから。
ビジネススキル、ドメインの知識、これらがカギになるとは雑誌でも読んだがそうだろうなと。
競馬のドメイン知識はある程度ある自分にとっては、データサイエンスのスキルはもちろんのこと、どう外部に価値ある形としてアウトプットできるかという部分は模索していきたい。
余談だが、ふだん競馬予想を提供している身としては、馬券が非常に好調になるという相関が生まれた。
これは機械学習が何たるかを少し理解できたことで、JRA-VANが提供するデータマイニングがこれまでただの数字でしかなかったが、意味ある数字として自分の予想に取り込めたこともあるだろう。
つまり、AIの予測値を私の予測の特徴量の1つとして取り込んだことにより、予想精度が高まったという感じ。
競馬予想に限らず、様々なシーンでAI判断を個人の判断の1特徴量として取り込んでいくのはデフォになるのかなぁと。
そのために最低限の機械学習の知識は必須になりそう。
おまけ_POGデータ ディープインパクト8世代
ディープ産駒 デビュー馬体重と賞金
ディープ産駒 デビュー月と賞金
※「0」は年明けデビュー
ディープ産駒 兄弟の獲得賞金と賞金

ディープ産駒 母の年齢と賞金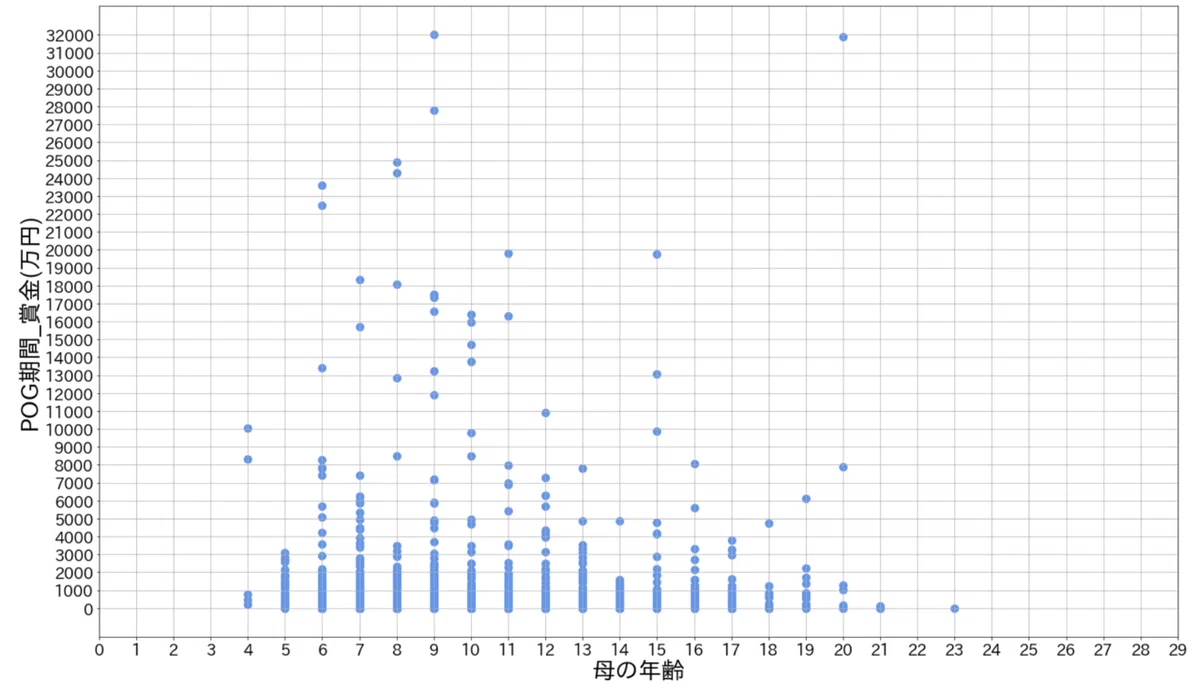
ディープ産駒 取引価格と賞金
※-3000は「取引なし」を見やすさを考慮して設定
ディープ産駒 誕生日数と賞金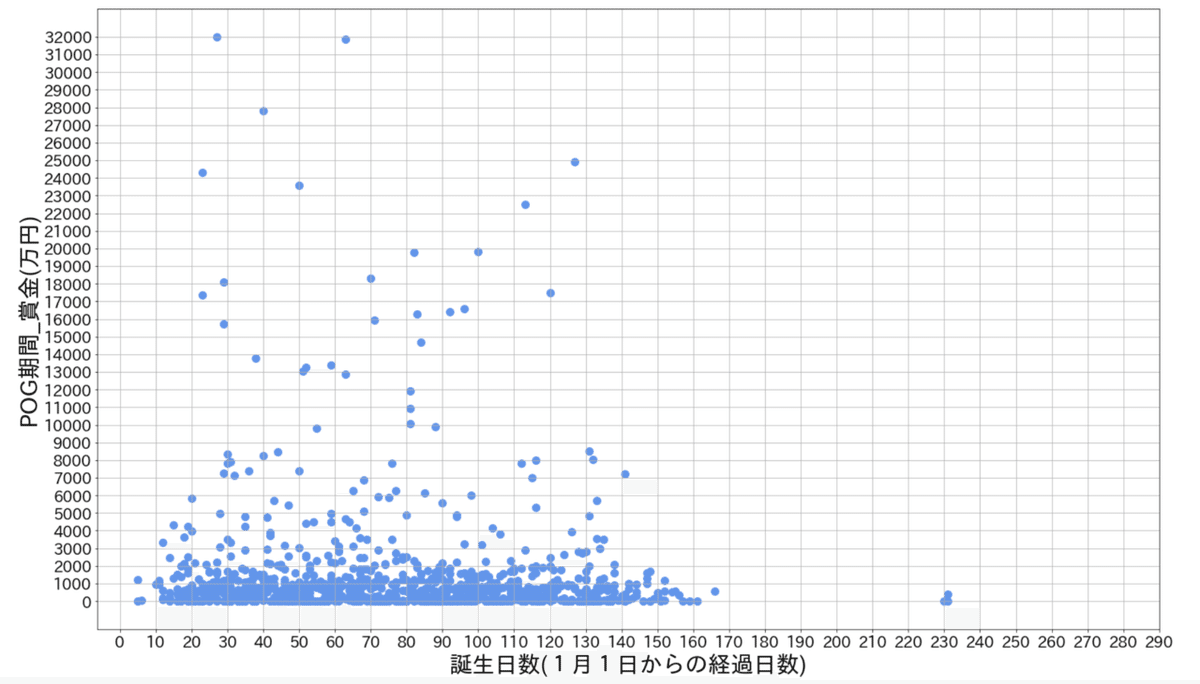
この記事が気に入ったらサポートをしてみませんか?