
Gemmaの技術レポートを読み解く〜Google初のオープンLLM

Googleが、生成AIの基盤である大規模言語モデル (LLM) として、「Gemma」を発表しました。Googleとしては初のオープンなLLMです。
Gemma は、マルチモーダル生成AIのGemini からインスピレーションを受けており、その名前はラテン語で「宝石」を意味するgemmaを反映しているそうです。
そこで、Gemmaの技術レポートをベースにしつつ、足りない情報をLlama-2の論文やGeminiの技術レポートで補いながら、多角的に技術レポートを読み解きます。
具体的には、オープンなLLMの代表格であるMeta社の「Llama-2」、Llama2を超えたとして頭角を表したフランスのMistral AI社の「Mistral」に加えて、LLMのトップランナーであるOpenAIの「GPT」、Google DeepMindの虎の子である「Gemini」などと比較します。
モデルの概要
Gemmaには、2つのパラメーターのサイズがあります。
Gemma (2B) : CPU およびオンデバイス・アプリケーションのための20億パラメーター・モデル
Gemma (7B) : GPU および TPU での効率的な導入と開発のための70億パラメーター・モデル
アーキテクチャーは、他のLLMと同様にTransformerをベースにしており、コンテキスト長は8,192トークンです。また、Transformerの登場後に発表された最新研究も参考にしています。
マルチクエリーAttention : 2BモデルはマルチクエリーAttention、7BモデルはマルチヘッドAttention
RoPE : 絶対位置埋め込みではなく、各層で回転位置埋め込み (Rotary Positional Embeddings)
GeGLU活性化
各Transformerのサブレイヤーの入力と出力の両方を正規化
Gemmaならではの学習時の工夫もあります。
学習データは、Webドキュメント・数学・コードからの主に英語のデータであり、Gemma (2B)が 2T トークン、 Gemma (7B)が 6T トークン
Geminiとの互換性のために、Gemini の SentencePieceトークナイザーのサブセットを使用
学習前のデータ混合物からすべての評価セットをフィルタリングし、対象を絞った汚染分析を実行して評価セットの漏洩をチェックし、機密出力の拡散を最小限に抑えることで暗唱のリスクを軽減
そして、環境への配慮も言及されています。
事前学習による炭素排出量:131 𝑡𝐶𝑂2𝑒𝑞
Google データセンターはカーボン・ニュートラルであり、エネルギー効率、再生可能エネルギーの購入、カーボン・オフセットの組み合わせによって達成される
ベンチマークによる評価
学術的な性能評価は、以下の表にまとめられています。

しかし、この表は、各ベンチマークの詳細を知らないと見通しが悪いです。そこで、Llama-2の論文の体系で分類します。
総合評価 (Aggregated Benchmark):MMLU, AGIEval, BBH
常識推論 (Commonsense Reasoning):HellaSwag, PIQA, SIQA, Boolq, Winogrande, CQA, OBQA, ARC-e, ARC-c
世界知識 (World Knowledge):TriviaQA, NQ
コーディング (Code) : HumanEval, MBPP
数学 (Math) : GSM8K, MATH
また、Llama-2の34Bや70Bのデータがなかったり、大規模言語モデルのトップランナーであるGPTやGeminiとの比較もなく、LLM全体でどの程度の性能に位置するのか見通しが悪いです。そこで、GPTとGeminiでも評価されたベンチマークを選別・比較します。
総合評価 (Aggregated Benchmark):MMLU, BBH
常識推論 (Commonsense Reasoning):HellaSwag
世界知識 (World Knowledge):なし
コーディング (Code) : HumanEval
数学 (Math) : GSM8K, MATH
総合評価
MMLU (Massive Multitask Language Understanding)では、Gemma (7B)が Mistral (7B)を上回り、パラメーターの大きいLlama-2 (34B)も上回っています。ここから、Gemmaが効率の良い学習をしていることが分かります。Gemma (7B)のパラメーターを少し増やせば、GPT-3.5やLlama-2 (70B)を超える期待も持てます。

BBH (Big Bench Hard)では、Gemma (7B)がLlama-2の最大パラメーターである 70Bモデルを上回っています。しかし、Mistral (7B)がさらに性能が高いことから、どちらかというと、Llama-2がBBHを苦手としている解釈できそうです。

常識推論
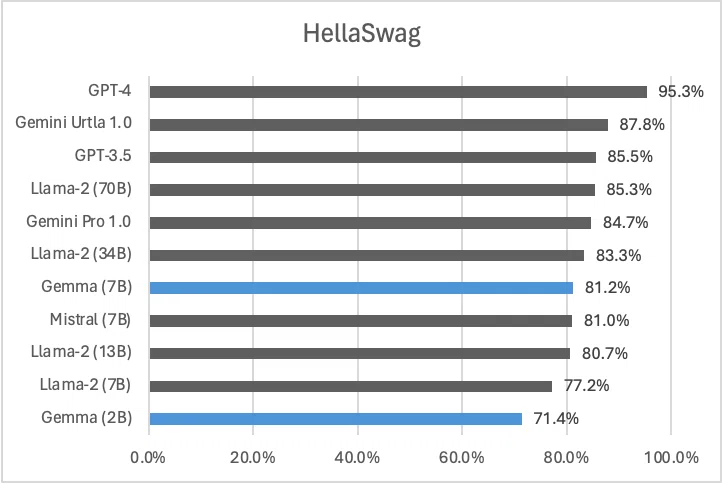
HellaSwagでは、Gemma (7B)が、Llama-2 (13B)やMistral (7B)を少しだけ上回っています。しかし、全体として80%を超えていることから、常識推論のベンチマークとしてHellaSwagが飽和状態にありそうです。そして、GPT-4の高性能ぶりが際立っています。
コーディング
HumanEvalでは、Gemmaの2B・7Bモデルが共に、Llama-2の大きなパラメーターのモデルを上回っています。このことから、Gemmaはコーディングが得意だと言えます。しかし、GPT-4やGeminiとは大きな差がある点に注意が必要です。

数学
GSM8Kでは、GemmaがLlama-2やMistralに対して健闘しているように見えます。ただし、技術レポートをよく読むと、モデル毎に評価手法が少しずつ異なるようで、この結果は鵜呑みにしない方が良さそうです。

MATHでは、Gemmaの2B・7Bモデルが共に、Llama-2の大きなパラメーターのモデルを上回っています。このことから、Gemmaは数学が得意だと言えます。なお、GPT-4やGemini Urtlaですら50%程度であることから、MATHは難易度の高い数学のベンチマークであると分かります。

安全性
学術的な安全性評価は、以下の表にまとめられています。

ここから、Geminiでも評価されたベンチマークを選別・比較します。
毒性 (Toxicity) : RealToxicity
バイアス (Bias) : BBQ (Bias Benchmark in QA), Winogender, Winobias
毒性 (Toxicity)について、Geminiの技術レポートでは、Geminiが約6%と報告されています。Gemmaの2Bが6.86%であり、7Bになると7.90%と悪化することが気になりますが、パラメーターを増やせば、6%前後に改善すると予想されます。
バイアス (Bias)について、Geminiの技術レポートでは、具体的な数値が報告されておらず、以下のように述べられています。
これらのデータセットのほとんどは、特に非常に能力の高い大規模モデルを評価しているため、99% に近い精度スコアですぐに飽和状態になります。
most of these datasets quickly become saturated with accuracy scores close to 99%, especially since we are evaluating highly capable large models.
二元的な性別や一般的な固定観念を超えて、偏見と固定観念を測定する新しい方法を開発することが必要
the need for developing new ways to measure bias and stereotyping, going beyond binary gender and common stereotypes
バイアスの評価は、既存のデータセットでは良いスコアが出るが、より高度なデータセットの構築が必要なようです。
責任ある開発
オープンなLLMを公開するには、責任ある開発が求められます。Gemmaの技術レポートでは、LLM公開の影響として、便益・リスク・対策・評価が整理されています。
便益
LLMをオープンに公開するだけでも開発コミュニティに便益がありますが、さらに、さまざまなプラットフォームでの実行サポートもされています。
Gemma が幅広い開発者のニーズをサポートできるようにするために、さまざまな環境を最適にサポートする 2 つのモデル サイズもリリースし、これらのモデルを多くのプラットフォームで利用できるようにしました (詳細については Kaggle を参照してください)。
To ensure Gemma supports a wide range of developer needs, we are also releasing two model sizes to optimally support different environments, and have made these models available across a number of platforms (see Kaggle for details).
実際にKaggleを見ると、モデルの対応バリエーションとして、Keras, PyTorch, Transformers, Gemma C++, TennsorRT, MaxText, Pax, Flaxなどがあります。
リスク
2つのリスクが述べられています。
Gemma の使用禁止ポリシーに違反する方法での Gemma モデルの使用を禁止する利用規約の対象であるにもかかわらず、悪意のある者が悪意を持って Gemma を微調整することを防ぐことはできません
有害な言語の生成や差別的な社会的危害の永続、モデルの幻覚、個人を特定できる情報の漏洩など、オープンモデルの意図しない動作
対策
2つ目のリスクへの対策として、「Generative AI Responsible Toolkit (責任ある生成AIツールキット)」がリリースされており、以下のようなノウハウやツールがあります。
安全ポリシーの設定、安全性の調整、安全性分類器、モデルの評価に関するガイダンス
Learning Interpretability Tool(LIT): Gemma の動作を調査し、潜在的な問題に対処します
最小限の例で堅牢な安全性分類器を構築するための手法
評価
リスクに対する評価が興味深いです。
最終的に、既存のエコシステム内でアクセス可能な大規模システムの機能を考慮すると、Gemma のリリースが AI リスク ポートフォリオ全体に与える影響はごくわずかであると考えられます。
Ultimately, given the capabilities of larger systems accessible within the existing ecosystem, we believe the release of Gemma will have a negligible effect on the overall AI risk portfolio.
これは、Gemma (7B)は、現在のオープンLLMの最高性能であるLlama-2 (70B) や Mistral (7B) をいくつかのベンチマークで少し上回る程度であり、「他のプレーヤーが先にオープンにしているんだから、Googleが追随しても影響は小さい」と予防線を張っているように見えます。
逆の見方をすると、他のプレーヤーに性能で勝ることを証明しつつ、手の内を明かしすぎないギリギリのラインが、Gemma の7Bモデルだったのでしょう。
今後、他のプレーヤーが Gemma (7B) を上回る性能のLLMを公開すれば、Googleも(仕方なく)より大きなパラメーターのLLMを公開するかもしれません。
最後に、Googleの次世代マルチモーダル生成AI「Gemini」の技術レポートに興味がある方は、こちらからどうぞ。
いただいたサポートは、note執筆の調査費等に利用させていただきます