
RaspberryPiですぱこん!その① (1台でもスーパー!)

ひと昔前に『二位じゃいけないんですか!?』なんて暴言を浴びせられて有名になったスーパーコンピューターさん。
最近だと「富岳」さんとかが話題ですね。膨大な電力を使って汗水ながして(?)人類のためにコロナの解析など、時間かかる計算を必死に頑張ってくれてるスゴイヤツ。スーパーありがたい存在ですね。
まあ詳しくは
このあたりをご参照いただくとして、こんなスーパーなヤツをベリー・ベリー・リーズナブルに作っちゃって遊んでみようというのが今回のお題です。
で、突然ですが
本の紹介
そのまんま、ずばりやりたいことをやってくれている本がありました。
なのでこちらを参考に作っちゃってみようと思います。
まずは一台から。
では、まずは一台のRaspberryPiを使って1ノードのスパコン(この段階ではあんまり意味ないけどw)を作ってみます。
とりあえず普通にセットアップ。
※余談ですが、最近のRaspberryPi OSをインストールして立ち上げると、
デフォの設定画面でいきなりしゃべりよりましたw pic.twitter.com/C8Hca17TMj
— 神楽坂らせん@『ちょっと上まで…』10話公開!,,Ծ‸Ծ,,☆ (@auxps) May 31, 2021
いきなりしゃべってくれましたw(HDMI接続でディスプレイ📺につないでいたら、音声が📺のスピーカーから出てきましたw)いままでスピーカーのついていないヤツでやっていたので気が付かなかったけれど、こんなところで地道にアクセシビリティ強化してるんですね~)
さて、セットアップはいつものように
このあたりで済ませます(GUI環境は別にいらないので、セットアップ終わったらGUI環境は止めちゃう予定です(CPUの負荷をそれだけ少なくしたいので~)。最初はいろいろ便利なのでそのままいれておくます。
MPI環境のインストール
MPIというのはメッセージ・パッシング・インターフェースというやつです(マルチなPiではないのよw)、並列コンピュータのプロセス、プロセッサ間のタスク共有をたすけてくれるえらいヤツです。基本的なチュートリアルやプログラムのしかたなどは
↑に詳しいのですが、日本語のは結構リンク切れしているので自分で探さないといけないかも?><
Raspberry Pi にMPI環境のインストール
面倒なのでパッケージでずばっと入れます。
お約束の apt update と upgrade を済ませたうえで、
$ sudo apt install build-essential manpages-dev gfortran nfs-common nfs-kernel-server vim openmpi-bin libopenmpi-dev openmpi-doc keychain nmapでOK。(いらないものも入ってますが、本の真似したらこうなりましたw)
MPIプログラミング
いつものように(?)まずサンプルプログラムをそのまま動かしてみます。
サンプルはコレ。本の中にも最初にでてくるやつです
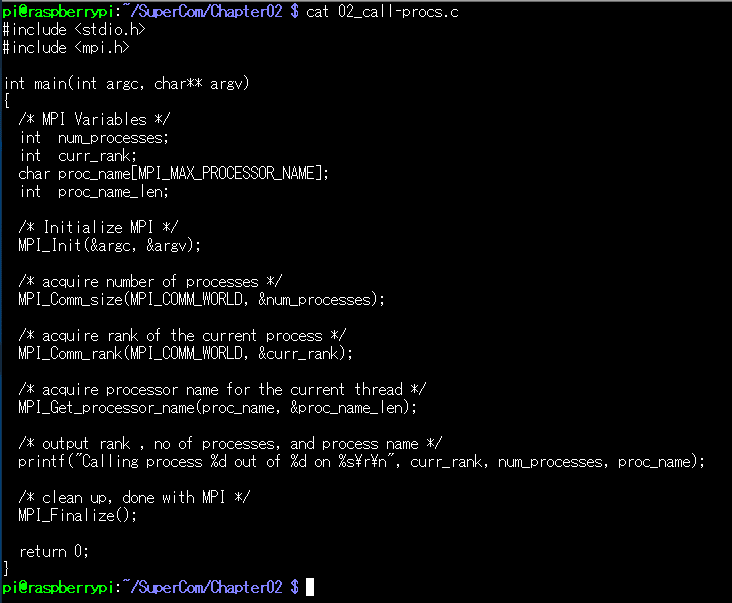
※詳しくは共立出版のHPからサンプルコードを持ってきてやってください。プログラムの著作権は著者のCarlos R. Morrison氏に帰属します。
コンパイルは
$ mpicc 02_call-procs.c -o call-procsのように、mpicc コマンドを使います。-o の後ろに作りたい実行ファイル名を書くと良いです。

↑やってみると、call-procs という実行ファイルができちゃっていることがわかります。
では、実行してみます。
実行は mpiexec コマンドを使います。

こんなかんじ。-n の後ろの数字は n個のスレッド(プロセス)をつかいますよ。という意味。なので、今回使っている Raspberry Pi 4 は 4コアCPUで4スレッド動かせるはずですから、nの値は4まで入れることができます。
やってみると、

こんな風になりました。
全部で四つあるプロセスの中で、1-2-0-3の順でそれぞれに割り当てましたよ。という意味のようです。(この順番はランダムに設定されるそう)
試しに割り当てられる最大値を超えてみたら、

こんな風に怒られましたw まああたりまえですねw
円周率計算してみる!
では、この4コアで時間がかかりそうなやつを実行してみます。有名どころで円周率計算ですね。(Piだけに!)
π方程式

をMPIで計算するようにしたプログラムが
ソースコード
/********************************************
* *** MPI pi code. *** *
* *
* This numerical integration calculates *
* pi using MPI. It converges very slowely, *
* requiring 5 million iterations for *
* 48 decimal place accuracy. *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/14/2017 *
********************************************/
#include <mpi.h> // (Open)MPI library #include <math.h> // math library #include <stdio.h> // Standard Input / Output library
int main(int argc, char*argv[])
{
int total_iter;
int n, rank, length, numprocs, i;
double mypi, pi, width, sum, x, rank_integral;
char hostname[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv); // initiates MPI
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // acquire number of processes
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // acquire current process id
MPI_Get_processor_name(hostname, &length); // acquire hostname
if (rank == 0)
{
printf("\n");
printf("#######################################################");
printf("\n\n");
printf("Master node name: %s\n", hostname);
printf("\n");
printf("Enter number of segments:\n");
printf("\n");
scanf("%d",&n);
printf("\n");
}
// broadcast the number of segments "n" to all processes.
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
// this loop increments the maximum number of iterations, thus providing
// additional work for testing computational speed of the processors
for(total_iter = 1; total_iter < n; total_iter++)
{
sum=0.0;
width = 1.0 / (double)total_iter; // width of a segment
// width = 1.0 / (double)n; // width of a segment
for(i = rank + 1; i <= total_iter; i += numprocs)
// for(i = rank + 1; i <= n; i += numprocs)
{
x = width * ((double)i - 0.5); // x: distance to center of i(th) segment
sum += 4.0/(1.0 + x*x); // sum of individual segment height for a given rank
}
// approximate area of segment (Pi value) for a given rank
rank_integral = width * sum;
// collect and add the partial area (Pi) values from all processes
MPI_Reduce(&rank_integral, &pi, 1, MPI_DOUBLE,MPI_SUM, 0, MPI_COMM_WORLD);
} // End of for(total_iter = 1; total_iter < n; total_iter++)
// printf("Process %d on %s has the partial result of %.16f \n",rank,hostname,
// rank_integral);
if(rank == 0)
{
printf("\n\n");
printf("*** Number of processes: %d\n",numprocs);
printf("\n\n");
printf(" Calculated pi = %.50f\n", pi);
printf(" M_PI = %.50f\n", M_PI);
printf(" Relative Error = %.50f\n", fabs(pi-M_PI));
printf("\n");
}
// clean up, done with MPI
MPI_Finalize();
return 0;
}こんなかんじです。しつこいですがコードの著作権はCarlos R. Morrison氏にあります。使いたい方は書籍を買ってあげましょうw(本の中のはコメントが日本語訳されていてちょっとわかりやすいですw あと微妙に表記(segmentsとか)がちがうような?)
ではこれを、mpicc でコンパイルし、mpiexec で実行します。
実行結果

こんなんでました~。 -n 1 で実行したのでめっちゃ時間かかりました。最初に入れている Enter number of segments: は、文字通り計算の分割数です。どれだけ細かくπの計算を分割して行うか、という値を指定します。ここでは300000個に分割しています。-n 1 なので1スレッドでやっているからまったく意味ありませんw (沢山のスレッドにばらまいて並列して計算させるためのものですネ)
で、だいぶ時間かかったのに計測していなかったことに気が付き(馬鹿)もっかい time 命令をくわえて実行してみます。
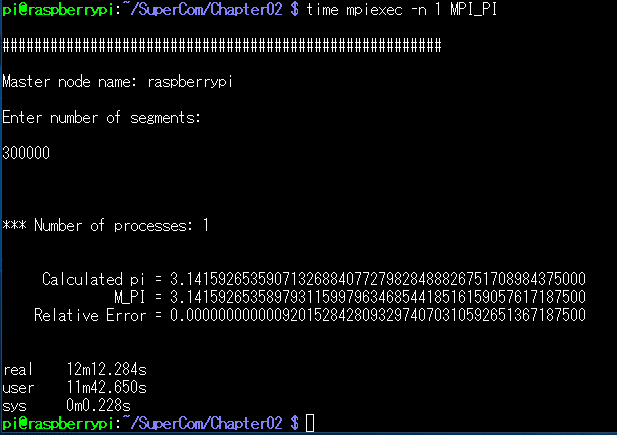
でました!
time の出力は

こういう意味なので、-n 1 で実行した結果は 12分12.284秒 かかったということですねー。
※なお、この実行結果はRaspberry Pi 4 B+ 2GB版、GUI等の計算以外の余計なプロセス走りながら版です。以後同様。
では、さっそく -n 4 して4コアでやってみます。
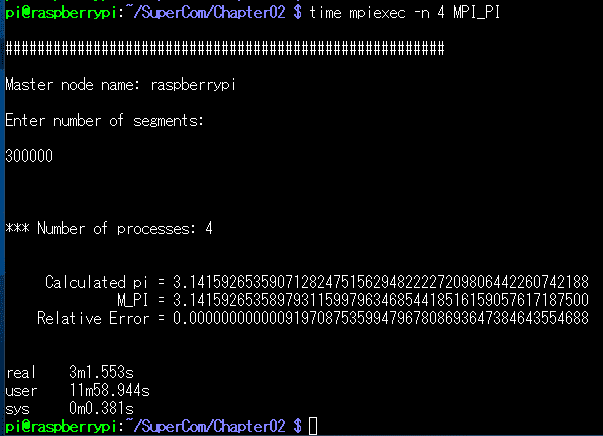
どん! おおー! なんと3分1.553秒! ほんとに1/4ぐらいになっちゃいました! user タイムが12分近いということは、各コアの動作時間を加算するとそれだけになるということで、まじで4倍速になってますねー。こんな理論通りに進むなんてびっくりですw
※実際には、コア間の通信や、(この後でてきますが)CPU間の通信がネックになってここまで綺麗にコア数を倍にしたら倍速になるような関係にはならないハズです。
とゆーわけで、とりあえず1台でやっつけた版はここまで、次回、実際に2台のRasPiをクラスター化してそれっぽいスパコンを作ってみることにします。以下次号ッ!
次号はこちらー
#RaspberryPi #PIクラスタ #スーパーコンピュータ #スパコン
よろしければサポートお願いします!いただいたサポートはクリエイターとしての活動費にさせていただきます!感謝!,,Ծ‸Ծ,,