
RaspberryPiですぱこん!その②(いよいよクラスター化!)

↑の続きです。
ではいよいよスパコンっぽく、複数のRaspberry Pi をつないでクラスター化をやってみたいとおもいます。
用意するモノ
・Raspberry Pi 4 B+(2GB) x4
・MicroSDカード 16GB x4 (容量は少な目で良いです)
・Pi4用ACアダプタ x4
・LANケーブル(短め) x4
・Piクラスターケース(4台用)x1
・ギガビットイーサネットHUB(5ポート)x1
・(できれば)テーブルタップ(5口以上)x1
てなかんじですね。
電子工作の知識と技術があればACアダプタは大きな電源を一つ用意してまとめて供給してもいけそう。今回はつかいませんでしたが、PoE電源なんてワザもつかっちゃうとカッコいいかもしれませんw
Piクラスターケースは、
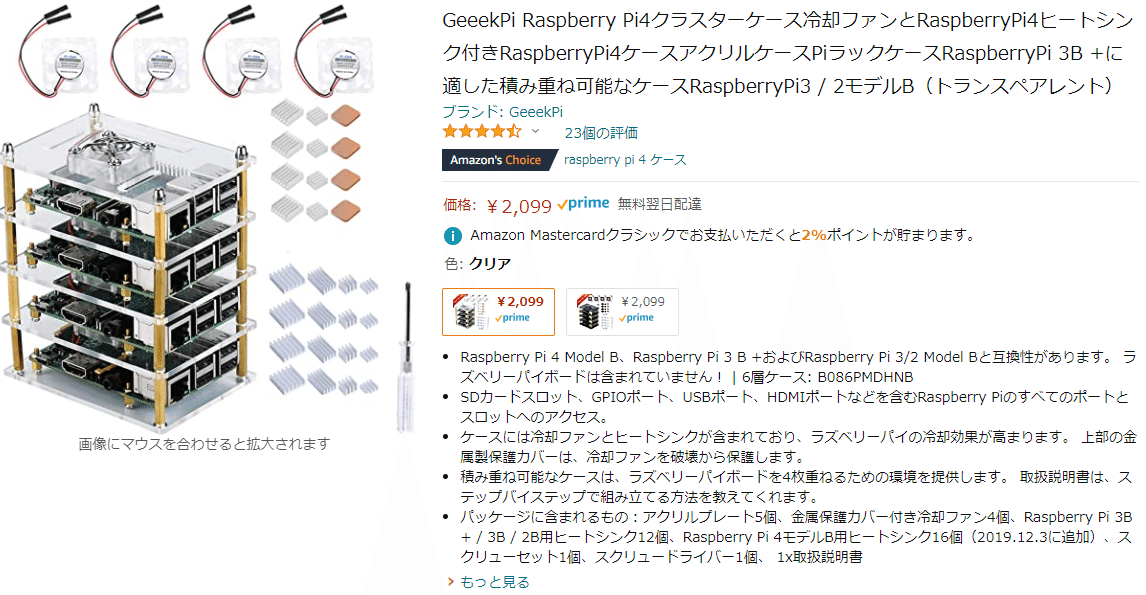
こんなばっちりなモノを見つけてしまったので即ポチしました。ケースにファンに、ヒートシンクまでセットで約2000円。ありがたやです☆
スーパーコンピュータキット届いた pic.twitter.com/TDE26GIhaN
— 神楽坂らせん@『ちょっと上まで…』10話公開!,,Ծ‸Ծ,,☆ (@auxps) May 31, 2021
そうそう、使用したRaspberryPi 4は、今回の用途ではメモリがそんなに必要ないと考えリーズナブルな容量少な目の2GB版にしました。
組み付けてみる
組み付けてみた☆
— 神楽坂らせん@『ちょっと上まで…』10話公開!,,Ծ‸Ծ,,☆ (@auxps) May 31, 2021
いろいろ捗りそう☆ pic.twitter.com/iwKEF3NM0m
こんな感じですね☆
これに、LANケーブルとイーサネットHUBをくわえると、

こんなかんじでごちゃっとなりますw
クラスター設定
組みあがったら、各々のRaspberryPiの初期設定を済ませて、ネットワーク的な組み合わせの設定を行います。
前回実験した1台目のRaspberryPi をマスター0(Mst0)として、それ以外の2台目~4台目を、スレーブ1(Slv1)~3(Slv3)と命名しておきます。
1台目:Mst0: 192.168.1.101
2台目:Slv1: 192.168.1.102
3台目:Slv2: 192.168.1.103
4台目:Slv3: 192.168.1.104
という構成ですね。
今回は192.168.1.101~192.168.1.104までの固定IPアドレスをそれぞれにふって、ホスト名(コンピュータ名)をMst0~Slv3に変更します。
IPアドレスの固定方法は「RaspberryPi IPアドレス固定」とかでぐぐってくださいましw
※ /etc/dhcpcd.conf の修正でおけw
ホスト名は、 /etc/hostname と /etc/hosts を書きかえてあげます。
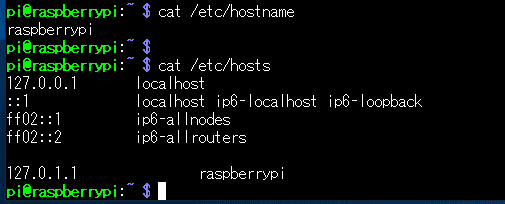
↑before
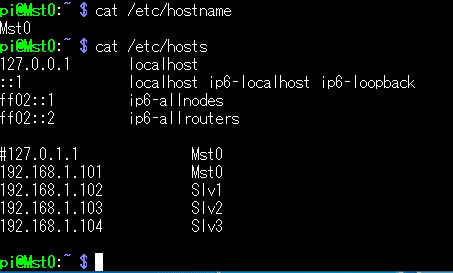
↑after
というかんじにすればOK(これはMst0の場合)
こういうことを、スレーブの三台にもそれぞれやっておきます。
※ここで参考書ではalphaという新規ユーザを作成してそこでやるように書かれていますが、面倒なのでRasPiのデフォルトのまま、piユーザーで進めていきます。
認証鍵の設定
それぞれのノード(RaspberryPi)へパスワード無しでログインできるよう、認証鍵を設定しておきます。
Mst0へログインしている状態で、
$ ssh-keygen -t rsaと入力します。
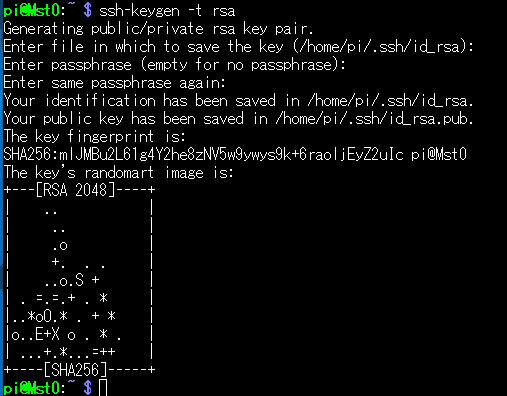
何処にkey保存するん? と聞かれるので最初はそのままエンター。次にパスフレーズ (パスワードじゃないので注意ね)を入力。確認入力をしたのち、 /home/pi/.ssh/id_rsa ファイルが生成されます。
認証鍵の転送
$ ssh-copy-id pi@Slv1 で、Slv1へ認証鍵を転送します。

初めてのSSH接続なら、つないでいいのかいねと聞かれるのでYes、その後、Slv1のパスワードを入れてねと言われるので入れて転送Done.
では、Mst0からSlvへssh接続してみます。
$ ssh Slv1すると、パスワードではなくパスフェーズを聞いてくるので入力します。
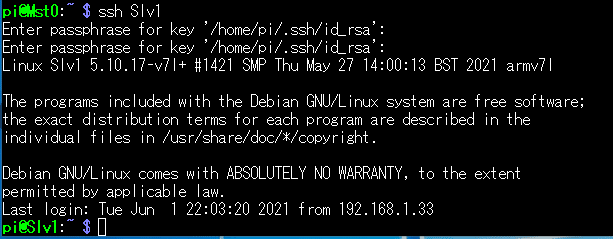
↑一度入力ミスりました(てへぺろ
二度目で成功、無事、Slv1に入れています。
.bashrc の編集
Mst0へ戻り、(exitコマンド) vi (nanoでもいいよ) で.bashrc を編集します。
$ vi .bashrc.bashrcファイルの最後に以下の3行を追加します。
# Logic for Keychain
/usr/bin/keychain $HOME/.ssh/id_rsa
source $HOME/.keychain/$HOSTNAME-sh
と追加して、
$ source .bashrcで .bashrc を再度読み込みます。
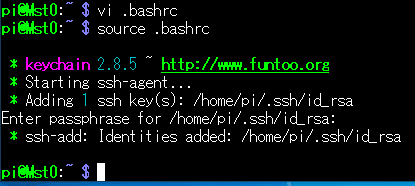
すると、またパスフェーズの入力を求められるので、入れてやります。
この儀式の後、Slv1へsshするのは、もうパスワードもパスフェーズも不要になる、はずです。

↑ ssh Slv1 だけでパスワードいらず!☆,,Ծ‸Ծ,,☆
Mst0にマウント可能なディレクトリを作る
マスターノード(Mst0)に、Slvさん達と共有するためのディレクトリを作成します。名前はなんでもいいですが、 spacom なんて名前にしておきましょう。
$ sudo mkdir /spacom
$ sudo chown pi:pi /spacomでおk。
ls で見てみると
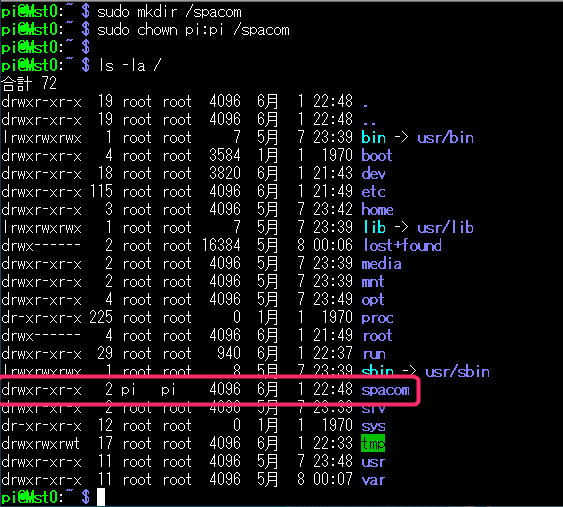
ちゃんとpiユーザのspacomができています。
exportsの設定
$ sudo vi /etc/exports
でexportsファイルを編集します。
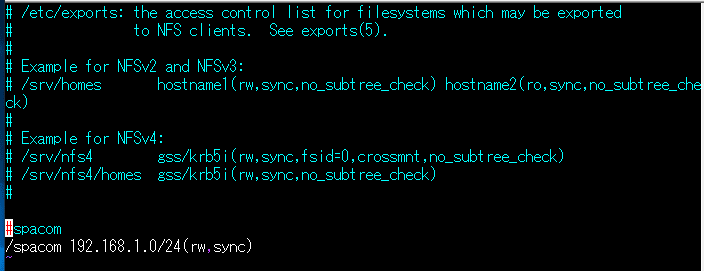
↑こんなのを最後に追加します。
意味としては、 /spacom がエクスポートしたいマスターノードのディレクトリ名で、192.168.1.0/24 は、192.168.1.0~192.168.1.255までのIPアドレスから/spacomディレクトリをマウントできまっせ。という意味ですのです。
書き換えたら
$ sudo service nfs-kernel-server restartでnfs-kernel-serverをリスタートしておきます。
※RasPiを再起動してもコレが有効になるようにrc.localにも追記しておくとよいかんじです。
$ sudo vi /etc/rc.local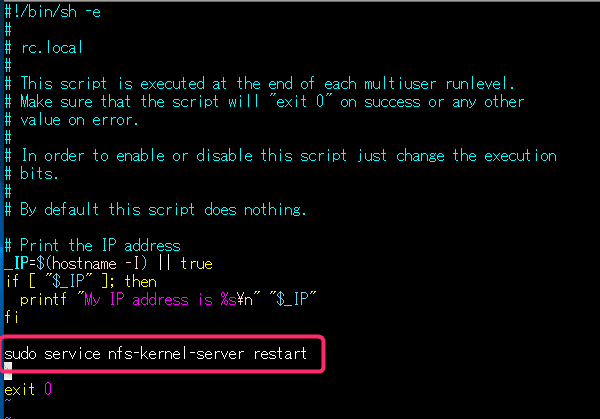
↑赤枠の中を追記。
Slv1からマウントしてみる
$ ssh Slv1でSlv1へ移動。(パスワードいらないはず。らくちん!)
その後、/spacom を Mst0の時と同じように作成して、ユーザ名も変えておきます。

手動マウント
Slv1から、
$ sudo mount Mst0:/spacom /spacomで、Mst0の /spacomがマウントされるはずです。
でも、まだMst0:/spacom のなかには何もないので、
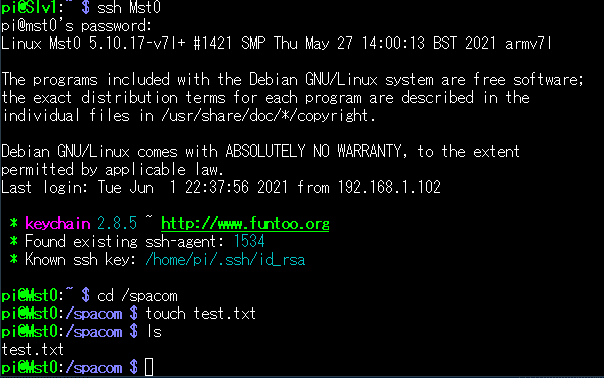
こんなことをしてみます。(Mst0で/spacom に test.txt という何もないファイルをつくってみる)
さてそれを、Slv1上から ls で見てみると・・・?

キタ━━━━(゚∀゚)━━━━!!
ばっちり入ってますね。おk!
リブートしても自動マウントしてくれるように fstab も書き直しておきましょう。
※20210613下記修正
$ sudo vi /etc/fstab
こんなかんじ、一番下に
Mst0:/spacom /spacom nfs noauto,x-systemd.automount,rw,exec 0 0という行をいれます。
※20210613追記:以前 defaults と書いていた部分を noauto,x-systemd.automount に訂正です。こうすると rc.local の修正をしなくても自動マウントできるようになりました。(むしろrc.local の修正↓では自動マウントできない??)
ついでに、rc.localも書き直しておきます。
$ sudo vi /etc/rc.local
![]()

この赤枠の中を追記しておきます。5秒まってfstabにかかれているものを全部マウントしてね。という意味です。(5秒待つのは、先にMst0が無事立ち上がっているようにちょっと待つようにしています。手でスイッチを入れるなら不要です)
ここまで出来たら、この spacom という共有されたディレクトリ上で、MPIなプログラムを実行できるようになります。
MPIプログラムのマルチノード実行
Mst0の共有ディレクトリ(/spacom)へ、プログラムをコピーしておきます。

↑ test.txt が入りっぱなしですけどまあご愛敬w
この状態で、前回にも実行した call-procs を実行してみます。
使い方は、
$ mpiexec -n 4 call-procsこんなかんじでした。-n 4 は4個のプロセスで実行するってことでした。
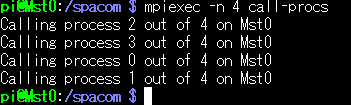
こんなかんじ。まあここまでは前の通り。
じゃあ、-n を 5にしてみる、と?
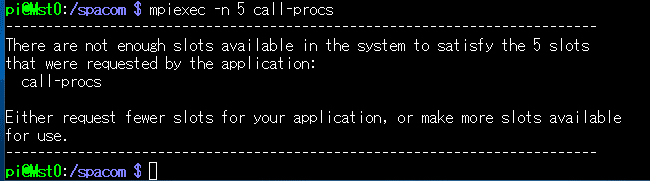
あれれ? 怒られましたね。
これ、実は -n では自ノードで実行できるプロセス数だけしか指定できないようです。他ノード(ここではSlv1)でも実行するにはどうしたら?
めんどうなのでいきなり回答をだしておくと、答えは -H オプションです。
$ mpiexec -H Mst0,Mst0,Mst0,Mst0,Slv1,Slv1,Slv1,Slv1 call-procsじゃん。-H オプションで、使いたいコアを持つホスト名を入れるという寸法。
実行してみましょう。

どん。
指定された8つのコアそれぞれにランダムにプロセスが割り当てられていることが分かりますね。
いいかんじ!
では、いよいよ、
2台のラズパイ=8コアでπ演算実行!
やっちみます。
コマンドは
$ time mpiexec -H Mst0,Mst0,Mst0,Mst0,Slv1,Slv1,Slv1,Slv1 MPI_PIですね。
早速実行!

LANケーブルの刺さっているポートのLEDがいまだかつてなく高速で点滅していてなんか必死にやってる感がありますw
結果きました!
どん!

うおおお! 4コアの時に3分かかっていたのが1分47.918秒!!
倍速とまではいきませんでしたが、かなりスピードアップしていることが分かります。これはワクワクしますねー☆
その他のコア数の結果
ついでなので、今までやっていなかった半端なコア分の結果も測ってみたので張っておきます。
pi@Mst0:/spacom $ time mpiexec -n 2 MPI_PI
#######################################################
Master node name: Mst0
Enter number of segments:
300000
*** Number of processes: 2
Calculated pi = 3.14159265359071149248393339803442358970642089843750
M_PI = 3.14159265358979311599796346854418516159057617187500
Relative Error = 0.00000000000091837648596992949023842811584472656250
real 5m56.411s
user 11m46.939s
sys 0m0.323s
pi@Mst0:/spacom $
pi@Mst0:/spacom $ time mpiexec -n 3 MPI_PI
#######################################################
Master node name: Mst0
Enter number of segments:
300000
*** Number of processes: 3
Calculated pi = 3.14159265359070261069973639678210020065307617187500
M_PI = 3.14159265358979311599796346854418516159057617187500
Relative Error = 0.00000000000090949470177292823791503906250000000000
real 3m58.771s
user 11m50.942s
sys 0m0.348s
pi@Mst0:/spacom $
pi@Mst0:/spacom $ time mpiexec -H Mst0,Mst0,Mst0,Mst0,Slv1 MPI_PI
#######################################################
Master node name: Mst0
Enter number of segments:
300000
*** Number of processes: 5
Calculated pi = 3.14159265359070616341341519728302955627441406250000
M_PI = 3.14159265358979311599796346854418516159057617187500
Relative Error = 0.00000000000091304741545172873884439468383789062500
real 2m32.129s
user 9m37.040s
sys 0m11.765s
pi@Mst0:/spacom $ time mpiexec -H Mst0,Mst0,Mst0,Mst0,Slv1,Slv1 MPI_PI
#######################################################
Master node name: Mst0
Enter number of segments:
300000
*** Number of processes: 6
Calculated pi = 3.14159265359070616341341519728302955627441406250000
M_PI = 3.14159265358979311599796346854418516159057617187500
Relative Error = 0.00000000000091304741545172873884439468383789062500
real 2m8.360s
user 8m2.340s
sys 0m15.172s
pi@Mst0:/spacom $ time mpiexec -H Mst0,Mst0,Mst0,Mst0,Slv1,Slv1,Slv1 MPI_PI
#######################################################
Master node name: Mst0
Enter number of segments:
300000
*** Number of processes: 7
Calculated pi = 3.14159265359071060430551369790919125080108642578125
M_PI = 3.14159265358979311599796346854418516159057617187500
Relative Error = 0.00000000000091748830755022936500608921051025390625
real 2m0.838s
user 7m23.694s
sys 0m31.565s
pi@Mst0:/spacom $上の方から、2コア、3コア、5,6,7コアとやってみました。
グラフにするとこんなかんじ。
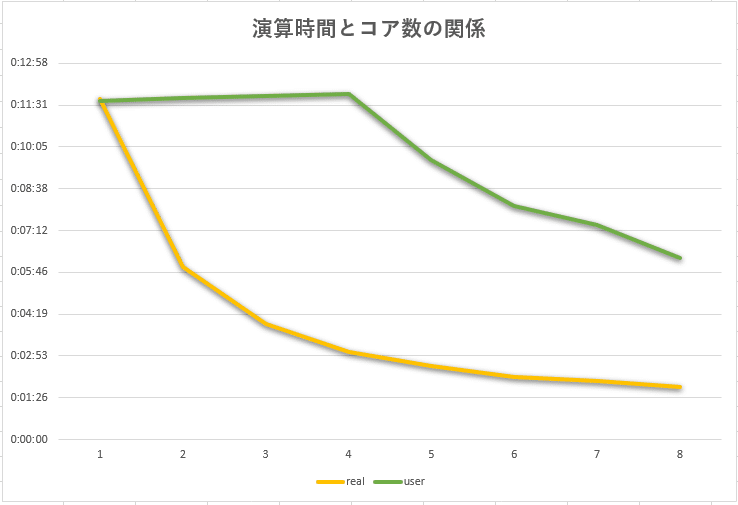
緑のラインはUserCPU動作時間なので、timeコマンドを実行している1台目のRasPi=Mst0のCPU動作時間のようです。(なので、4コアまでは動作時間が増えているけれど、それ以降は減っている)
オレンジのRealが実際に現実にかかっている時間。これで見ると、綺麗な反比例曲線になっていて、ほぼ想定通りの減り方のようです。
とゆーところまでで今日は時間切れ!
まだ用意したRaspberryPi 4台中の2台でしか並列計算させていないので、次こそはさらに増やして4台でやっつけてみようとおもいます!
いんらいんふぉー!(違)
てなことでまた次回につづくッ!
つづきー
よろしければサポートお願いします!いただいたサポートはクリエイターとしての活動費にさせていただきます!感謝!,,Ծ‸Ծ,,