
「モノリスからマイクロサービスへ」1章読んでみた

動機
最近発売されたこの本ですが、今携わっているプロジェクトにドンピシャだったので即注文して読むことにしました。
年末大掃除したりとかRTA in Japanを見たりとか真・女神転生Ⅲとかプリコネやっていたりとかしてドタバタしてましたがまとまった時間が取れたのでまず1章を読んでみました。そこで自分なりに印象に残ったところをまとめてみました。
・「独立デプロイ可能性」を必ず意識する
本書から得られるものが1個だけだとしたら
「マイクロサービスには独立デプロイ可能性の概念を確実に取り入れよう」
ということだ。
1つのマイクロサービスへの変更を、他の何かをデプロイすることなく本番環境にリリースする習慣を身に着けよう、そうすればいいことがついてくるはず。
読み始めて一番目に記載されていました。また得られるものが1個のみなら、という観点で述べられているということはそれくらい大事な概念だと推察できます。
そのためにはサービス同士が疎結合である必要があります。その後に論じられているのはこの言葉がベースになっているものが多かったです。
・データベースを共有しない
1つの大きなデータベースに対して色々なサービスからアクセスされるようなモノリシックなデータベースはおすすめされません。
サービスが他のサービスが保持するデータが欲しい場合はそのサービスに必要なデータを要求するようにしないといけません。こうすることで何を隠蔽し何を公開しないといけないのかがはっきりします。
そのサービスが知りたいデータを所有しているデータストレージと共にUI部分やサーバサイド部分をカプセル化することで、ビジネス機能の凝集度が高められ、また結合度が下げられます(凝集度と結合度に関しては後で取り上げています)。
しかしDBを分割することで生まれる問題もあります。その一つが「トランザクション」です。DBを分割することでアトミック性が失われてしまいます。
この辺の対処法に関しては第4章で解説されています。
・マイクロサービスアーキテクチャに合わせて新しい技術を大量に取り入れたいという誘惑に負けない
マイクロサービス化を機に新しい技術をモリモリ入れてみたくなるのもわかるけど、新技術を採用する = コストということを忘れてはなりません。
まず自分が慣れ親しんだ既存の技術を使ってマイクロサービス化する、最初はそれだけでも十分価値がある事です。
そもそもマイクロサービス自体は基本的に技術に依存しません(k8sもDockerもパブリッククラウドもGoもRustも何もかもはマイクロサービスに依存はしない)。
・分割するサイズの粒度
筆者はサイズのことをあまり気にしていないみたいです。それよりも以下の2点を気にしています。
・自分たちはどれくらいのマイクロサービスを扱うことができるか
・マイクロサービスの境界線をどのように定義すれば、マイクロサービスを最大限活かすことができるのだろうか
コードの行だったりサービスの数ベースで話をしても、言語の特徴や事業のコンテキストによってバラバラなので、あまりあてにできません。
Javaで25行のコードが必要なのがClojureでは10行で書けるかもしれないのにコードの行を当てにするのはあまり意味がないです(Clojureが優れていると言いたいわけではなく、言語にはそれぞれ特徴があるというだけです)
それよりも「我々はどれだけの数のマイクロサービスを扱えるのか」「メリットをどれだけ活かせるか」を気にすることが重要とのことでした。
・所有権
開発チームとPOが別々に完全に分かれているような組織ではコミュニケーションコストや認識の齟齬、それを起因とした開発の遅れ等発生してしまい、結果的に機能不全に陥ってしまいます。(この辺の図は結構面白かったですw)
これに代わって、POはデリバリーを担当するチームの一員として働き、デリバリーチームは特定の顧客に向けたサービスを開発していくことを紹介しています。いわゆる「フィーチャーチーム」のようなものを思い浮かべるとわかりやすいかもしれません。
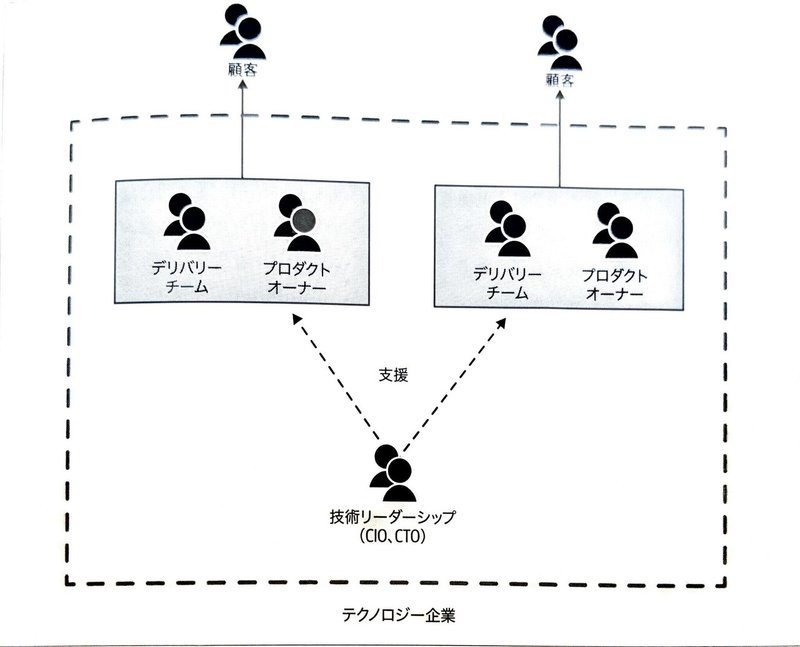
こうすることで各チームが所有するサービスや責務が明確になりやすく、デリバリー衝突が最小限になります。
※デリバリー衝突・・・同じ場所で作業する人が増えることで作業のバッティング、コードのコンフリクト、プッシュやデプロイの時間調整等所有権の境界線が混乱することによって起こる問題
・結合と凝集
マイクロサービスの境界を定義する際にはこの2つのバランスが大事です。
結合・・・あるものに対する変更がどれくらい別のものの変更を必要とするか
凝集・・・関連するコードをどのようにグループ化するか
この辺はLarry Constantineという方が上手く表現しています。
構造は、凝集度が高く、結合度が低い場合に安定する
凝集度が低い、つまりある機能に関連するコードがあちこちにあった場合どうなるかというと、修正箇所を探すコストや直したときの影響範囲を考えないといけなくなります。また、いろんな箇所を修正しなくてはならないので結合度も高くなってしまいます。
モノリスの場合、変更しがちなものをまとめておくのではなく関係ないコードをやクラスを呼んで1つの処理を作成しがちなので凝集度が低くなり、他のモノリスに影響を及ばさないために関係のないサービスもデプロイしなくてはならなくなります(独立デプロイ可能性が全然ありません)。
そのため、この2つの考え方はマイクロサービスアーキテクチャを構成する上でとても大切になってくる考え方です。
なお、結合だけで以下だけ種類があり、それぞれ具体例とともわかりやすく紹介されていました。
・実装結合
・一時的結合
・デプロイ時結合
・ドメイン結合
まとめ
今回以下の5点に注目して書いてみました。
・「独立デプロイ可能性」を必ず意識する
・データベースを共有しない
・分割するサイズの粒度
・所有権
・結合と凝集
1点注意していただきたいのが、大事なのはこの5点だけではないというところです。
本書にはとてもためになる事が事例とともに記載されていたのですが、
書き始めると無限に長くなるのでこの5つにしました(DDDを用いたサービスのモデル化とか)。詳しく知りたい方はぜひ買ってみてください。
この記事が気に入ったらサポートをしてみませんか?