Windows のパソコンとIntelのGPUしか持ってない人がGPUで深層学習するにはどうしたらよいか【MATLABからTensorFlow/Kerasへ移行したい人必見】

matlabのdeep learning toolboxを使って機械学習を始めてみたはいいが、
単一CPUで学習させるとどうしても時間がかかる。
具体的には、Inter(R) Core(TM) i5-10210U CPU @ 1.60GHzにてvgg16モデルを利用したCAEに、240x240x3の24bit bmp画像8枚分を学習させるのに1分弱かかる)
大学の先生に相談したところ、GPUを利用するとかしないと卒論間に合わないんじゃないの?ってことになったので、そのための道筋を考えてみた。
1. GPUとは
CPUとは別の、画像処理に特化した演算装置。深層学習も画像処理も共に行列演算であるから、GPUは深層学習に相性がいいんだそう。
2. 各深層学習向けツールのGPU対応状況
2-1. MATLABおよびMATLABのDeep Learning Toolboxアドオン
(参考: MATLAB 公式ドキュメンテーション)
そもそも大前提として、MATLABでGPUを利用するには、アドオン
「Parallel Computing Toolbox」が必要である。
そして「Parallel Computing Toolbox」はNvidia製のGPUのみをサポートしていて、Intel GPUはサポートしていない。
(ちなみにParallel Computing Toolboxを使うと、いつもはdoubleとかuint8とかの型で表現されるデータが「gpuArray」型となり、この型での演算はGPU上で実行できるようになる。)
(Deep Learning Toolbox使用時は、gpuArray型への変換なしに、適切なGPUが存在するときは自動でGPUが演算に用いられるようになっているんだそうだ。)
2-2. TensorFlow
(参考: 現場で使えるTensorFlow開発入門 Kerasによる深層学習モデル構築手法)
TensorFlowはCPU版とGPU版でパッケージが別個となっている。
こちらも残念ながらNVIDIA製のGPUにか対応していない。
2-3. Intel製GPUを高速化するには―PlaidML
(参考:https://stella-log.hatenablog.com/entry/2019/01/25/183305)
MATLAB, TensorFlowや、(前に言及していないが)RapidMinerといった有名どころの機械学習ツールにおけるGPU対応状況は、どれもNVIDIA製のものに限られていて、逆に言えば非NVIDIA製GPUしかもっていない人は、機械学習をGPU上で実行するためだけに、環境を選びなおさなくてはならない。
TensorFlowやKerasユーザであれば、PlaidMLをKerasのフレームワークとして利用することで、それまでに書いたコードを書き換えることなく、GPU上での学習に切り替えることができるそうだ。
3. 解決策
3-1. 解決策その1―PlaidMLを入れて、Windowsパソコン/Intel GPU上で高速学習を実現する
(参考: https://qiita.com/kekekekenta/items/ba8f13144864d8f4c20a
現場で使えるTensorFlow開発入門 Kerasによる深層学習モデル構築手法)
3-1-1. Anacondaの導入
Anacondaとはpythonで機械学習を行うのに最適な環境を作ってくれるフレームワークである。機械学習で用いるような多数のライブラリを一緒にインストールしてくれるので、ライブラリインストールの手間が省ける。
また「仮想環境」という仕組みのおかげで、複数バージョンのpythonやtensorflowなどを切り替えながら使うこともできるようになることも利点のひとつなんだそうだ。
Anacondaは こちら からダウンロードできる。(パスは通す)
3-1-2. PlaidMLをインストール
Anacondaをパスを通してインストールしたら、コマンドプロンプトからPlaidMLをインストールしよう。
まずは仮想環境を作る必要がある。例えば仮想環境の名前を「31」、pythonのバージョンを「3.5」とする場合、次のようにする。
C:\Users\hoge>conda create -n 31 python=3.5(蛇足だが、pythonのバージョンはこの例の通り3.5としておいた方が無難。3.8だとplaidmlが上手くkerasのバックエンドになってくれなかった。)
(「C:\Users\hoge>」は含めない。「conda」およびその右を入力)
ここで
「'conda' は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていません。」
と怒られてしまったら、残念ながらパスが通っていない。その場合は次のパスを通すよう設定してみてほしい。
C:\Users\(パソコンのユーザ名)\anaconda3
C:\Users\(パソコンのユーザ名)\anaconda3\Library\mingw-w64\bin
C:\Users\(パソコンのユーザ名)\anaconda3\Library\usr\bin
C:\Users\(パソコンのユーザ名)\anaconda3\Library\bin
C:\Users\(パソコンのユーザ名)\anaconda3\Scripts仮想環境31が作られたら、この31を起動する。
C:\Users\hoge>activate 31すると、次のように表示され、括弧内に仮想環境名が表示され、仮想環境が起動し、その内部に入ったことを示してくれる。
(31) C:\Users\hoge>ではいよいよ、この仮想環境内にPlaidMLをインストールしよう。
次のように入力する。
(31) C:\Users\hoge>conda install h5py imageio Pillow opencv
...
(31) C:\Users\hoge>pip install pygame
...
(31) C:\Users\hoge>pip install plaidml-keras
...エラー無く再び「(31) C:\Users\hoge>」が表示されれば、インストールは完了である。
次に、PlaidMLのセットアップを行う。
(31) C:\Users\hoge>plaidml-setupこのコマンドを実行すると、いくつか質問を受けるので答えていく。具体的には次のような感じ。
Default Config Devices:
llvm_cpu.0 : CPU (via LLVM)
Experimental Config Devices:
llvm_cpu.0 : CPU (via LLVM)
opencl_intel_uhd_graphics.0 : Intel(R) Corporation Intel(R) UHD Graphics (OpenCL)
Using experimental devices can cause poor performance, crashes, and other nastiness.よくわからないが、GPU( opencl_intel_uhd_graphics.0 : Intel(R) Corporation Intel(R) UHD Graphics (OpenCL))が「Experimental (Config) Devices」に分類されているので、これを使うために「y」を選択した。
Multiple devices detected (You can override by setting PLAIDML_DEVICE_IDS).
Please choose a default device:
1 : llvm_cpu.0
2 : opencl_intel_uhd_graphics.0
Default device? (1,2)[1]: デフォルトで用いる演算装置。当然2(GPUのほう)を選択した。
Almost done. Multiplying some matrices...
Tile code:
function (B[X,Z], C[Z,Y]) -> (A) { A[x,y : X,Y] = +(B[x,z] * C[z,y]); }
Whew. That worked.
Save settings to C:\Users\osiet\.plaidml? (y,n)[y]:y
Success!たぶん、選択されたGPU上で関数を計算して、ちゃんと動いたよという報告。後は以上の設定を保存したら、設定完了だ。
3-2. 解決策その2―計算サーバ(クラウド)の利用(気が向いたら書きます)
(気が向いたら書きます)
4. Kerasの書き方
(参考: 現場で使えるTensorFlow開発入門 Kerasによる深層学習モデル構築手法 8~9章等
参考: Keras 公式ドキュメンテーション https://keras.io/ja/)
3-1節の方法でも、3-2節の方法でも、どのみちKerasへの移行が必須だ。ということでここではKerasの書き方を解説する。
また4章では仮想環境「31」を例に解説するが、解決策その2を採用する読者の方は、仮想環境を「32」に適宜読み替えてほしい。
4-1. 前提
本稿では、Kerasをpythonで動かす前提で解説している。
また、PlaidMLを利用(して自PCのGPUで学習)する場合、各プログラムの先頭に、次の2行を入れる必要がある。
import plaidml.keras
plaidml.keras.install_backend()4-2. 畳み込みエンコーダ・デコーダを作ってみる
ーーーーーーー
MATLAB Deep Learning Toolboxとの重要な違い:
(1)paddingが'same'と'valid'の2通りしか選べない
'same'は出力サイズが入力サイズ/stride (0.5は繰り『上』げ)と同じになるよう調整する
'valid'は、パディングを行わない。出力サイズは入力サイズ/stride (0.5は繰り『下』げ) + 1となる
つまり、「パディングを調整して、出力をサイズ〇×△に」といった柔軟なことはできない。
(2)活性化関数が畳み込み層の引数で指定される
(3)配列インデックス等、MATLABは1オリジン、Kerasは0オリジン
プログラミング言語の違い。
(4)インデックス情報を受け取る逆プーリング層が用意されていない
MATLABでは、最大プーリング層は「次の層への出力」の他に、「最大逆プーリング層への『インデックス情報』」をも提供する。
このインデックス情報は、「縮小時にどの位置の成分が採用されたか」を表現する。最大逆プーリング層がこの情報を受け取ると、
対応するインデックスには入力層から受け取った成分を、
その他のインデックスには0を
書き込んだものを出力するようだ。
一方Kerasには(自作しない限り)このような層は用意されておらず、単なるアップサンプリング層でこの層を代用しているモデルが大多数である。
ーーーーーーー
次のような畳み込みエンコーダ・デコーダを作ってみよう。
但しカーネルサイズは常に(3,3) (潜在空間直前を除く), 活性化関数はreluとする。
入力: 240x240x3 24bit bmp
3Dモデルを、ある1点を一定距離で見つめる条件下で任意のアングルから撮影した2D画像
エンコーダモデル:
①畳み込み層 (240,240,3)→(240,240,64), ストライド: (1,1), パディング: same
②畳み込み層 (240,240,64)→(120,120,64), ストライド: (2,2), パディング: same
③畳み込み層 (120,120,64)→(120,120,128), ストライド: (1,1),
パディング: same
④畳み込み層 (120,120,128)→(60,60,128), ストライド: (2,2), パディング: same
⑤畳み込み層 (60,60,128)→(60,60,256), ストライド: (1,1), パディング: same
⑥畳み込み層 (60,60,256)→(60,60,256), ストライド: (1,1), パディング: same
⑦畳み込み層 (60,60,256)→(30,30,256), ストライド: (2,2), パディング: same
⑧畳み込み層 (30,30,256)→(30,30,512), ストライド: (1,1), パディング: same
⑨畳み込み層 (30,30,512)→(30,30,512), ストライド: (1,1), パディング: same
⑩畳み込み層 (30,30,512)→(15,15,512), ストライド: (2,2), パディング: same
⑪畳み込み層 (15,15,512)→(15,15,512), ストライド: (1,1), パディング: same
⑫畳み込み層 (15,15,512)→(15,15,512), ストライド: (1,1), パディング: same
⑬畳み込み層 (15,15,512)→(7,7,512), ストライド: (2,2), パディング: same
⑭畳み込み層 (7,7,512)→(7,7,512), ストライド: (1,1), パディング: same
⑮畳み込み層 (7,7,512)→(7,7,512), ストライド: (1,1), パディング: same
⑯畳み込み層 (7,7,512)→(3,3,512), ストライド: (2,2), パディング: valid
⑰畳み込み層 (3,3,512)→(3,3,512), ストライド: (1,1), パディング: same
⑱畳み込み層 (3,3,512)→(3,3,512), ストライド: (1,1), パディング: same
⑲畳み込み層 (3,3,512)→(1,1,512), ストライド: (2,2), パディング: valid
⑳~㉕はカーネルサイズ(1,1)
⑳畳み込み層 (1,1,512)→(1,1,512), ストライド: (1,1), パディング: same
㉑畳み込み層 (1,1,512)→(1,1,512), ストライド: (1,1), パディング: same
㉒畳み込み層 (1,1,512)→(1,1,128), ストライド: (1,1), パディング: same
㉓畳み込み層 (1,1,128)→(1,1,32), ストライド: (1,1), パディング: same
㉔畳み込み層 (1,1,32)→(1,1,8), ストライド: (1,1), パディング: same
㉕畳み込み層 (1,1,8)→(1,1,3), ストライド: (1,1), パディング: same
潜在空間: 1x1x3
デコーダモデル: エンコーダと対称的
出力: 240x240x3 24bit bmp
入力画像の余白をある色で塗りつぶす。
この色はアングル情報(x,y,z軸角度)を360で割って256をかけることで得られるrgb情報によって定まる。
ちなみに、フィルタサイズf、入力サイズi、ストライドsから出力サイズoを求めるには次の計算をするとよい。
o = floor((i-f)/s)+1
4-2-1. モデルをKerasで書く
(plaidvisionのひとつ上/)cae/cae.py
# import plaidml.keras
# plaidml.keras.install_backend()
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import Conv2DTranspose
cae = Sequential();
dicts = \
[\
{"f":64, "k":(3,3), "s":(1,1), "p":"same", "a":"relu", "i":(240,240,3),}, \
{"f":64, "k":(3,3), "s":(2,2), "p":"same", "a":"relu"}, # 120
{"f":128, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":128, "k":(3,3), "s":(2,2), "p":"same", "a":"relu"}, # 60
{"f":256, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":256, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":256, "k":(3,3), "s":(2,2), "p":"same", "a":"relu"}, # 30
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(2,2), "p":"same", "a":"relu"}, # 15
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(2,2), "p":"valid", "a":"relu"}, # 7
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(2,2), "p":"valid", "a":"relu"}, # 3
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(3,3), "s":(2,2), "p":"valid", "a":"relu"}, # 1
{"f":512, "k":(1,1), "s":(1,1), "p":"same", "a":"relu"},
{"f":512, "k":(1,1), "s":(1,1), "p":"same", "a":"relu"},
{"f":128, "k":(1,1), "s":(1,1), "p":"same", "a":"relu"},
{"f":32, "k":(1,1), "s":(1,1), "p":"same", "a":"relu"},
{"f":8, "k":(1,1), "s":(1,1), "p":"same", "a":"relu"},
{"f":3, "k":(1,1), "s":(1,1), "p":"same", "a":"relu", "n":"hidden"}
]
for i in range(len(dicts)):
# エンコーダ
d = dicts[i]
if "i" in d:
cae.add(Conv2D(filters=d["f"], input_shape=d["i"],kernel_size=d["k"],strides=d["s"], padding=d["p"], activation=d["a"], name="enc_"+str(i)))
elif "n" in d:
cae.add(Conv2D(filters=d["f"], kernel_size=d["k"],strides=d["s"], padding=d["p"], activation=d["a"], name=d["n"]))
else:
cae.add(Conv2D(filters=d["f"], kernel_size=d["k"],strides=d["s"], padding=d["p"], activation=d["a"], name="enc_"+str(i)))
for j in range(len(dicts)-1):
# デコーダ
i = len(dicts) - j - 1 -1
d = dicts[i]
cae.add(Conv2DTranspose(filters=d["f"], kernel_size=d["k"],strides=d["s"], padding=d["p"], activation=d["a"], name="dec_"+str(i)))
# 出力層
cae.add(Conv2DTranspose(filters=3, kernel_size=(3,3),strides=(1,1), padding="same", activation="relu", name="out"))
cae.compile(optimizer="adam", loss="mse")
#adamは初期パラメータのまま利用。学習率は0.001
if __name__ == "__main__":
cae.summary() # モデル詳細の表示
このコードを保存したら、実行してみよう
(31) C:\Users\hoge\plaidml\plaidvision>cd ..
(31) C:\Users\hoge\plaidml>cd cae
(31) C:\Users\hoge\plaidml\cae>python cae.pyすると、次のように表示される。
INFO:plaidml:Opening device "opencl_intel_uhd_graphics.0"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
enc_0 (Conv2D) (None, 240, 240, 64) 1792
_________________________________________________________________
enc_1 (Conv2D) (None, 120, 120, 64) 36928
_________________________________________________________________
enc_2 (Conv2D) (None, 120, 120, 128) 73856
_________________________________________________________________
enc_3 (Conv2D) (None, 60, 60, 128) 147584
_________________________________________________________________
enc_4 (Conv2D) (None, 60, 60, 256) 295168
_________________________________________________________________
enc_5 (Conv2D) (None, 60, 60, 256) 590080
_________________________________________________________________
enc_6 (Conv2D) (None, 30, 30, 256) 590080
_________________________________________________________________
enc_7 (Conv2D) (None, 30, 30, 512) 1180160
_________________________________________________________________
enc_8 (Conv2D) (None, 30, 30, 512) 2359808
_________________________________________________________________
enc_9 (Conv2D) (None, 15, 15, 512) 2359808
_________________________________________________________________
enc_10 (Conv2D) (None, 15, 15, 512) 2359808
_________________________________________________________________
enc_11 (Conv2D) (None, 15, 15, 512) 2359808
_________________________________________________________________
enc_12 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
enc_13 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
enc_14 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
enc_15 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
enc_16 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
enc_17 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
enc_18 (Conv2D) (None, 1, 1, 512) 2359808
_________________________________________________________________
enc_19 (Conv2D) (None, 1, 1, 512) 262656
_________________________________________________________________
enc_20 (Conv2D) (None, 1, 1, 512) 262656
_________________________________________________________________
enc_21 (Conv2D) (None, 1, 1, 128) 65664
_________________________________________________________________
enc_22 (Conv2D) (None, 1, 1, 32) 4128
_________________________________________________________________
enc_23 (Conv2D) (None, 1, 1, 8) 264
_________________________________________________________________
hidden (Conv2D) (None, 1, 1, 3) 27
_________________________________________________________________
dec_23 (Conv2DTranspose) (None, 1, 1, 8) 32
_________________________________________________________________
dec_22 (Conv2DTranspose) (None, 1, 1, 32) 288
_________________________________________________________________
dec_21 (Conv2DTranspose) (None, 1, 1, 128) 4224
_________________________________________________________________
dec_20 (Conv2DTranspose) (None, 1, 1, 512) 66048
_________________________________________________________________
dec_19 (Conv2DTranspose) (None, 1, 1, 512) 262656
_________________________________________________________________
dec_18 (Conv2DTranspose) (None, 3, 3, 512) 2359808
_________________________________________________________________
dec_17 (Conv2DTranspose) (None, 3, 3, 512) 2359808
_________________________________________________________________
dec_16 (Conv2DTranspose) (None, 3, 3, 512) 2359808
_________________________________________________________________
dec_15 (Conv2DTranspose) (None, 7, 7, 512) 2359808
_________________________________________________________________
dec_14 (Conv2DTranspose) (None, 7, 7, 512) 2359808
_________________________________________________________________
dec_13 (Conv2DTranspose) (None, 7, 7, 512) 2359808
_________________________________________________________________
dec_12 (Conv2DTranspose) (None, 15, 15, 512) 2359808
_________________________________________________________________
dec_11 (Conv2DTranspose) (None, 15, 15, 512) 2359808
_________________________________________________________________
dec_10 (Conv2DTranspose) (None, 15, 15, 512) 2359808
_________________________________________________________________
dec_9 (Conv2DTranspose) (None, 30, 30, 512) 2359808
_________________________________________________________________
dec_8 (Conv2DTranspose) (None, 30, 30, 512) 2359808
_________________________________________________________________
dec_7 (Conv2DTranspose) (None, 30, 30, 512) 2359808
_________________________________________________________________
dec_6 (Conv2DTranspose) (None, 60, 60, 256) 1179904
_________________________________________________________________
dec_5 (Conv2DTranspose) (None, 60, 60, 256) 590080
_________________________________________________________________
dec_4 (Conv2DTranspose) (None, 60, 60, 256) 590080
_________________________________________________________________
dec_3 (Conv2DTranspose) (None, 120, 120, 128) 295040
_________________________________________________________________
dec_2 (Conv2DTranspose) (None, 120, 120, 128) 147584
_________________________________________________________________
dec_1 (Conv2DTranspose) (None, 240, 240, 64) 73792
_________________________________________________________________
dec_0 (Conv2DTranspose) (None, 240, 240, 64) 36928
_________________________________________________________________
out (Conv2DTranspose) (None, 240, 240, 3) 1731
=================================================================
Total params: 61,035,014
Trainable params: 61,035,014
Non-trainable params: 0
_________________________________________________________________
(31) C:\Users\hoge\plaidml\cae>Output Shapeの0次元目「None」はバッチサイズを表す。現在バッチサイズを決めていないのでNoneとなっている。以降3次元は、順に各層の出力サイズ「縦, 横, チャンネル数」。
4-2-2. 訓練する
Kerasでモデルを訓練するにはいくつか方法がある。
一番シンプルで簡単なのが、モデルのもつ次のようなfitメソッドを使う方法だ。
model.fit\
(
訓練用入力ndarrayテンソル(画像の枚数, 縦, 横, チャンネル数),
訓練用模範応答ndarrayテンソル,
epochs=エポック回数,
batch_size=バッチサイズ(何枚毎に重みを更新するか),
shuffle=True if 画像をシャッフルしたい else False,
validation_data=(検証用入力, 検証用模範応答)
)
# validation_dataは省略可能。今回は省略する(検証を行わない)他にもKerasのImageDataGeneratorや自作のジェネレータを使って学習を行うためのfit_generatorメソッドもあって、このメソッドをうまく定義/利用すれば前処理をその都度リアルタイムに行えるので便利だ。しかも画像を「その都度」渡すことが出来、ディレクトリ内の画像をすべて一度に読み込む必要がなくなる。(MATLABでいうDataStoreのような利便がある)
が、今回はこちらの詳解は省く。
訓練用入力画像をcae/train_input,
訓練用模範応答画像をcae/train_output
のディレクトリにそれぞれ入れたら、次のようなコードをcae/cae_learn.pyとして保存する。
cae/cae_learn.py
# import plaidml.keras
# plaidml.keras.install_backend()
import numpy as np
import os
from PIL import Image
import cae # 先ほど作ったコードだ
import glob
import pickle
bin_file = "learned_cae_model.binaryfile"
if not os.path.exists(bin_file):
input_bmps = glob.glob("./train_input/*.bmp")
output_bmps = glob.glob("./train_output/*.bmp")
train_input = np.zeros([len(input_bmps), 240, 240, 3], dtype='uint8')
train_output = np.zeros([len(input_bmps), 240, 240, 3], dtype='uint8')
for i in range(len(input_bmps)):
train_input[i,:,:,:] = np.array(Image.open(input_bmps[i]))
train_output[i,:,:,:] = np.array(Image.open(output_bmps[i]))
# 訓練用データの読み込み
print("training starts...\n") # 2byte文字は文字化けするようだ
cae.cae.fit\
(
train_input,
train_output,
epochs=100,
batch_size=30,
shuffle=True
)
#訓練
#絶対ダメwith open(bin_file, "wb") as bf:
#絶対ダメ pickle.dump(cae, bf)
cae.cae.save(bin_file)
#保存 2020/10/5 10:00ごろ開始した。Epoch 1/100が表示されてから進捗バーが出るのに20分近くかかった。
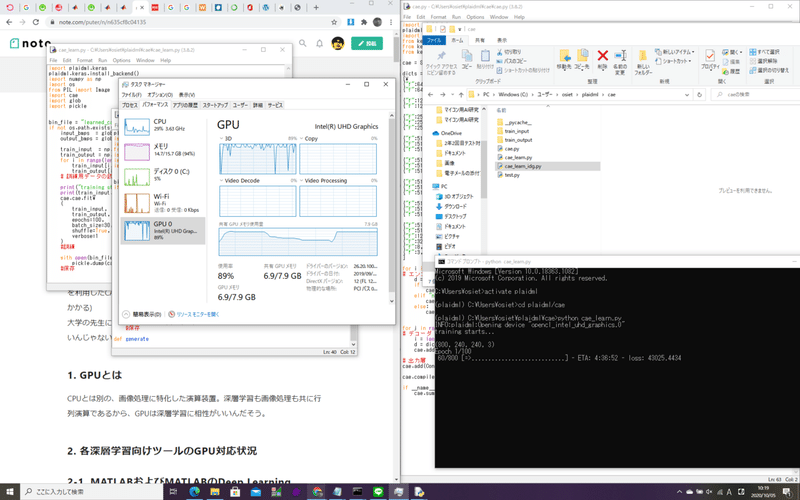
たしかにGPUで学習できていることが分かる。(ETAも最初四時間とか表示されて絶望したが、数分で1時間強まで減少したり。いい意味であまりあてにならない。)
1日と約50分後である2020/10/6 10:46には、次のような進捗となっていた。
Epoch 1/100
800/800 [==============================] - 3414s 4s/step - loss: 2464213814.8532
Epoch 2/100
800/800 [==============================] - 1166s 1s/step - loss: 42635.2038
Epoch 3/100
800/800 [==============================] - 1137s 1s/step - loss: 135147.2605
Epoch 4/100
800/800 [==============================] - 1118s 1s/step - loss: 42617.5467
Epoch 5/100
800/800 [==============================] - 1096s 1s/step - loss: 1487855.9457
Epoch 6/100
800/800 [==============================] - 1123s 1s/step - loss: 42679.0617
Epoch 7/100
800/800 [==============================] - 1126s 1s/step - loss: 42630.0721
Epoch 8/100
800/800 [==============================] - 1126s 1s/step - loss: 42617.5421
Epoch 9/100
800/800 [==============================] - 1125s 1s/step - loss: 42610.0390
Epoch 10/100
800/800 [==============================] - 1122s 1s/step - loss: 42628.4291
Epoch 11/100
800/800 [==============================] - 1134s 1s/step - loss: 42561.5523
Epoch 12/100
800/800 [==============================] - 1166s 1s/step - loss: 42553.2527
Epoch 13/100
800/800 [==============================] - 1162s 1s/step - loss: 42548.9706
Epoch 14/100
800/800 [==============================] - 1208s 2s/step - loss: 42547.7494
Epoch 15/100
800/800 [==============================] - 1141s 1s/step - loss: 42547.6889
Epoch 16/100
800/800 [==============================] - 1170s 1s/step - loss: 42547.6858
Epoch 17/100
800/800 [==============================] - 1125s 1s/step - loss: 42547.6823
Epoch 18/100
800/800 [==============================] - 1140s 1s/step - loss: 42547.6786
Epoch 19/100
800/800 [==============================] - 1124s 1s/step - loss: 42547.6788
Epoch 20/100
800/800 [==============================] - 1180s 1s/step - loss: 42547.6859
Epoch 21/100
800/800 [==============================] - 1175s 1s/step - loss: 42547.6880
Epoch 22/100
800/800 [==============================] - 1130s 1s/step - loss: 42547.6856
Epoch 23/100
800/800 [==============================] - 1183s 1s/step - loss: 42547.6784
Epoch 24/100
800/800 [==============================] - 1176s 1s/step - loss: 42547.6780
Epoch 25/100
800/800 [==============================] - 1172s 1s/step - loss: 42547.6763
Epoch 26/100
800/800 [==============================] - 1134s 1s/step - loss: 42547.6753
Epoch 27/100
800/800 [==============================] - 1126s 1s/step - loss: 42547.6792
Epoch 28/100
800/800 [==============================] - 1143s 1s/step - loss: 42547.6754
Epoch 29/100
800/800 [==============================] - 1137s 1s/step - loss: 42547.6777
Epoch 30/100
800/800 [==============================] - 1130s 1s/step - loss: 42547.6749
Epoch 31/100
800/800 [==============================] - 1148s 1s/step - loss: 42547.6754
Epoch 32/100
800/800 [==============================] - 1143s 1s/step - loss: 42547.6753
Epoch 33/100
800/800 [==============================] - 1134s 1s/step - loss: 42547.6765
Epoch 34/100
800/800 [==============================] - 1161s 1s/step - loss: 42547.6761
Epoch 35/100
800/800 [==============================] - 1140s 1s/step - loss: 42547.6741
Epoch 36/100
800/800 [==============================] - 1190s 1s/step - loss: 42547.6761
Epoch 37/100
800/800 [==============================] - 1143s 1s/step - loss: 42547.6773
Epoch 38/100
800/800 [==============================] - 1142s 1s/step - loss: 42547.6893
Epoch 39/100
800/800 [==============================] - 1144s 1s/step - loss: 42547.6752
Epoch 40/100
800/800 [==============================] - 1142s 1s/step - loss: 42547.6756
Epoch 41/100
800/800 [==============================] - 1135s 1s/step - loss: 42547.6758
Epoch 42/100
800/800 [==============================] - 1148s 1s/step - loss: 42547.6806
Epoch 43/100
800/800 [==============================] - 1177s 1s/step - loss: 42547.6795
Epoch 44/100
800/800 [==============================] - 1145s 1s/step - loss: 42547.6761
Epoch 45/100
800/800 [==============================] - 1130s 1s/step - loss: 42547.6784
Epoch 46/100
800/800 [==============================] - 1145s 1s/step - loss: 42547.6818
Epoch 47/100
800/800 [==============================] - 1151s 1s/step - loss: 42547.6751
Epoch 48/100
800/800 [==============================] - 1170s 1s/step - loss: 42547.6785
Epoch 49/100
800/800 [==============================] - 1125s 1s/step - loss: 42547.6795
Epoch 50/100
800/800 [==============================] - 1135s 1s/step - loss: 42547.6751
Epoch 51/100
800/800 [==============================] - 1136s 1s/step - loss: 42547.6739
Epoch 52/100
800/800 [==============================] - 1155s 1s/step - loss: 42547.6778
Epoch 53/100
800/800 [==============================] - 1149s 1s/step - loss: 42547.6769
Epoch 54/100
800/800 [==============================] - 1136s 1s/step - loss: 42547.6784
Epoch 55/100
800/800 [==============================] - 1130s 1s/step - loss: 42547.6792
Epoch 56/100
800/800 [==============================] - 1148s 1s/step - loss: 42547.6800
Epoch 57/100
800/800 [==============================] - 1150s 1s/step - loss: 42547.6782
Epoch 58/100
800/800 [==============================] - 1151s 1s/step - loss: 42547.6879
Epoch 59/100
800/800 [==============================] - 1147s 1s/step - loss: 42547.6802
Epoch 60/100
800/800 [==============================] - 1133s 1s/step - loss: 42547.6783
Epoch 61/100
800/800 [==============================] - 1139s 1s/step - loss: 42547.6743
Epoch 62/100
800/800 [==============================] - 1234s 2s/step - loss: 42547.6749
Epoch 63/100
800/800 [==============================] - 1285s 2s/step - loss: 42547.6771
Epoch 64/100
800/800 [==============================] - 1209s 2s/step - loss: 42547.6743
Epoch 65/100
800/800 [==============================] - 1191s 1s/step - loss: 42547.6766
Epoch 66/100
800/800 [==============================] - 1248s 2s/step - loss: 42547.6772
Epoch 67/100
800/800 [==============================] - 1197s 1s/step - loss: 42547.6760
Epoch 68/100
800/800 [==============================] - 1204s 2s/step - loss: 42547.6793
Epoch 69/100
800/800 [==============================] - 1236s 2s/step - loss: 42547.6745
Epoch 70/100
800/800 [==============================] - 1272s 2s/step - loss: 42547.6816
Epoch 71/100
800/800 [==============================] - 1284s 2s/step - loss: 42547.6738
Epoch 72/100
800/800 [==============================] - 1303s 2s/step - loss: 42547.6773
Epoch 73/100
800/800 [==============================] - 1204s 2s/step - loss: 42547.6780
Epoch 74/100
800/800 [==============================] - 1261s 2s/step - loss: 42547.6853
Epoch 75/100
720/800 [==========================>...] - ETA: 2:02 - loss: 42585.0067グラフにすると次の通り
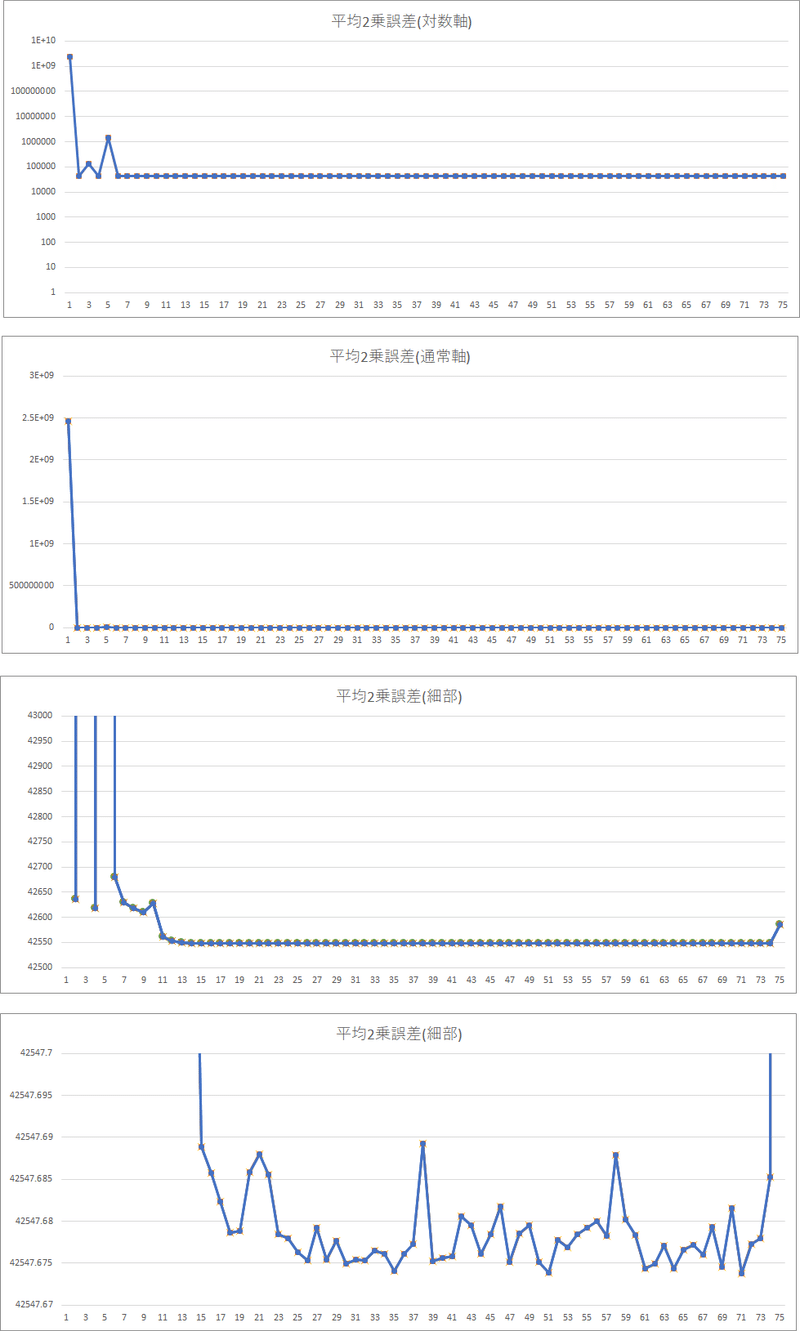
最初数十億だった損失が、42547.67~42547.69の間に収まるよう落ち着いた
(最後75エポック目はエポックが完了していないので微妙に上がっている)
ちなみに、pickleで保存すると、最後の最後でこんなエラーが出て、学習結果を保存できない。
Traceback (most recent call last):
File "cae_learn.py", line 37, in <module>
pickle.dump(cae, bf)
_pickle.PicklingError: Can't pickle <class 'module'>: attribute lookup module on builtins failed
没4-2-1. モデルを返すgenerateCAEModel関数を作るこの記事が気に入ったらサポートをしてみませんか?