Answer for questions at Pretia Tech Talk1

Q1. I have a problem with mono-camera vSLAM relocalization with point cloud maps made with LiDAR SLAM.
Before jumping to the LiDAR-SLAM, let’s have an idea in mind that how LiDAR works. The LiDAR sensor is a ranging system that emits the photons and calculates the time-of-flight of the photons, then it gets the distance of the range. This is how the point clouds cluster is generated, by emitting many photons. Thus, it will be dense point cloud clusters.
In the visual SLAM, the point cloud cluster is generated by processing the image pixel from a camera. The point cloud cluster is computed from many mathematical methods, rather than from an actual sensing system. Also, it only extracts the salient points that are distinguishable from neighboring pixels, and it will sparse points.
With the understanding of LiDAR points and camera feature points, there methods are fundamentally different so it’s not able to work across.
Q2. How does Pretia detect and determine the direction and magnitude of vectors from the camera images?
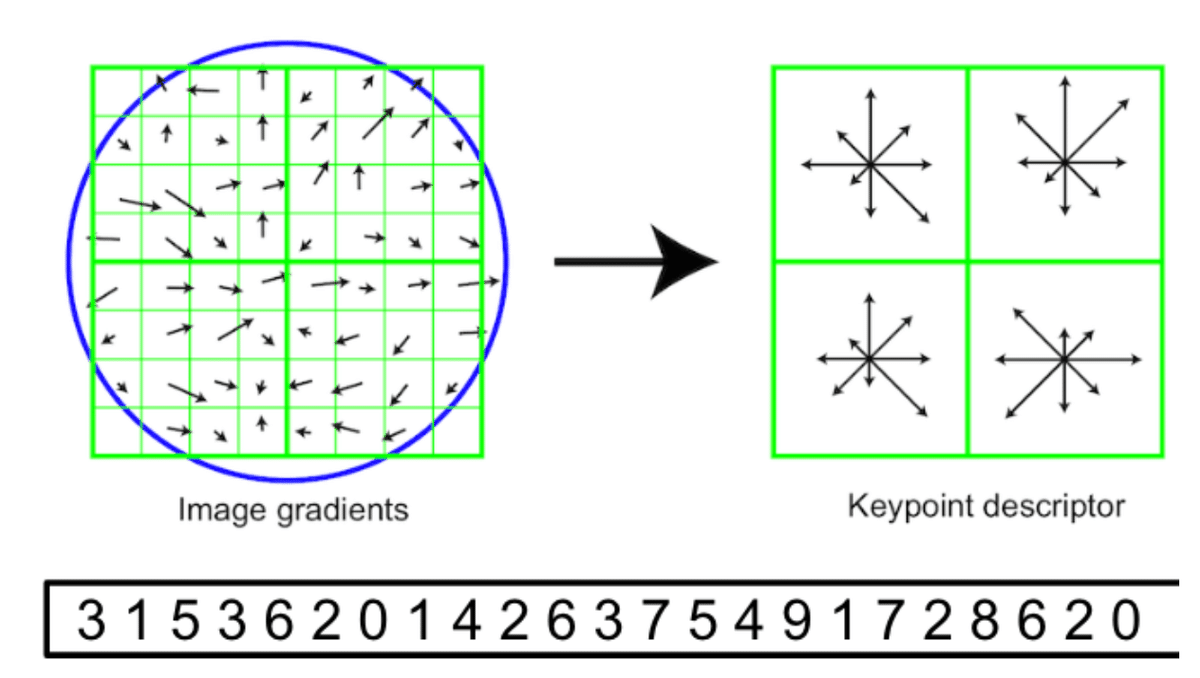
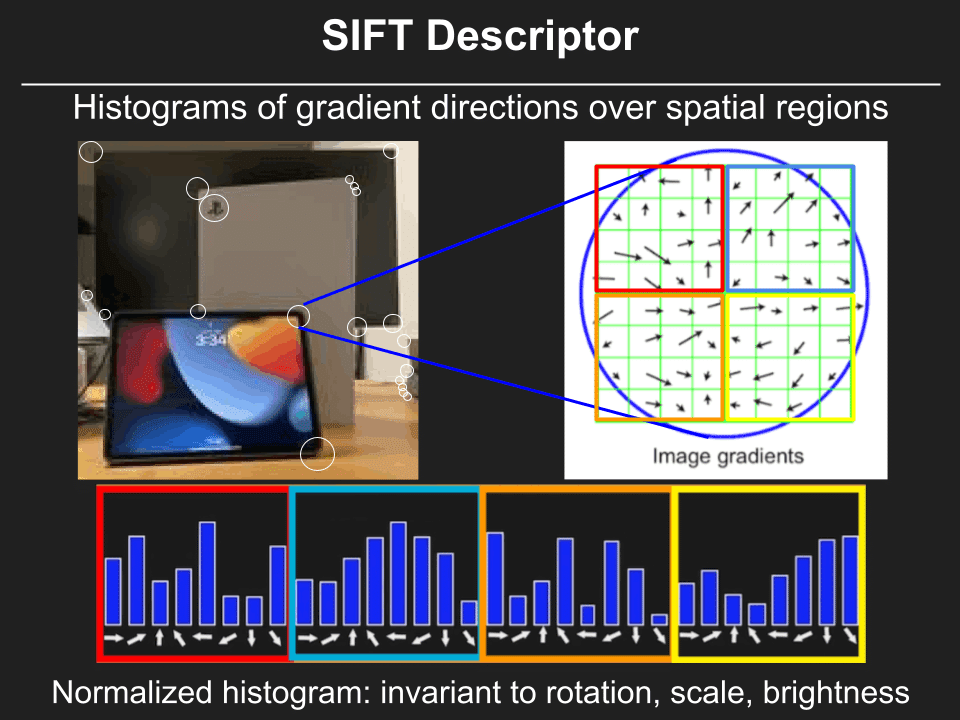
How we create a feature descriptor from image
I guess here, we are taking SIFT as an example for a feature descriptor
Generate the image gradients
Generate the feature descriptors
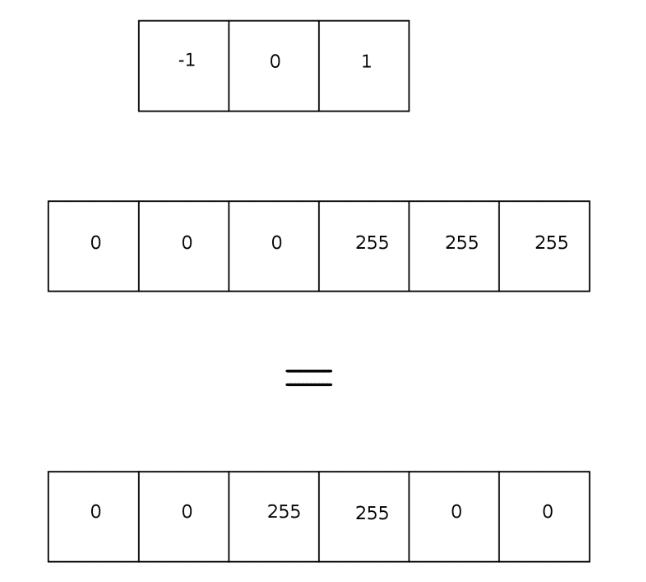
1) The image magnitude and direction are derived from measuring the derivative. The idea to to fin the difference/the most changed pixel in a picture (edge detection). Here is an example of a 1D image array, (0, 0, 0, 255, 255, 255), the pixel value is from 0 ~ 255, and the (-1, 0, 1) is the gradient filter. Then the result will be (0, 0, 255, 255, 0, 0)
The formulas are as follows.
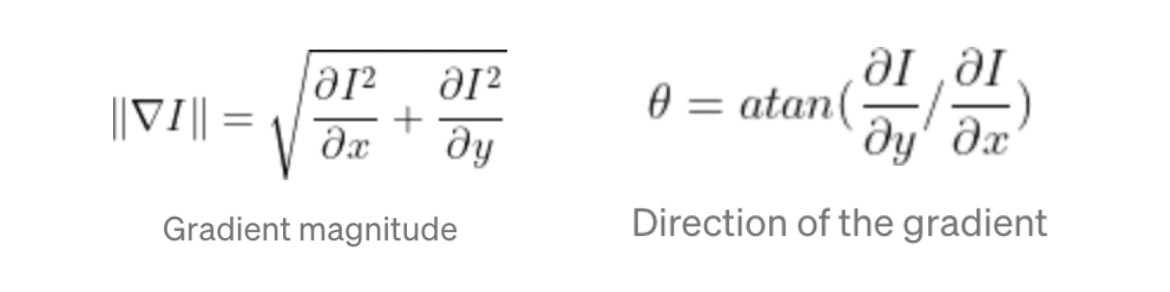
For the illustration, if the original image is like

The x-derivative is like
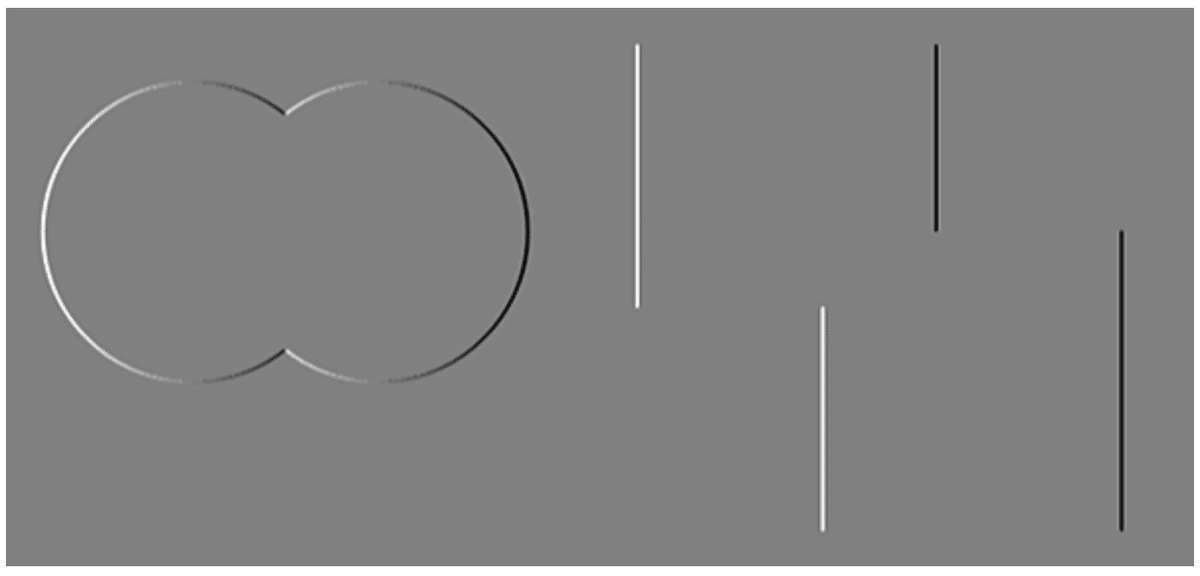
The y-derivative is like
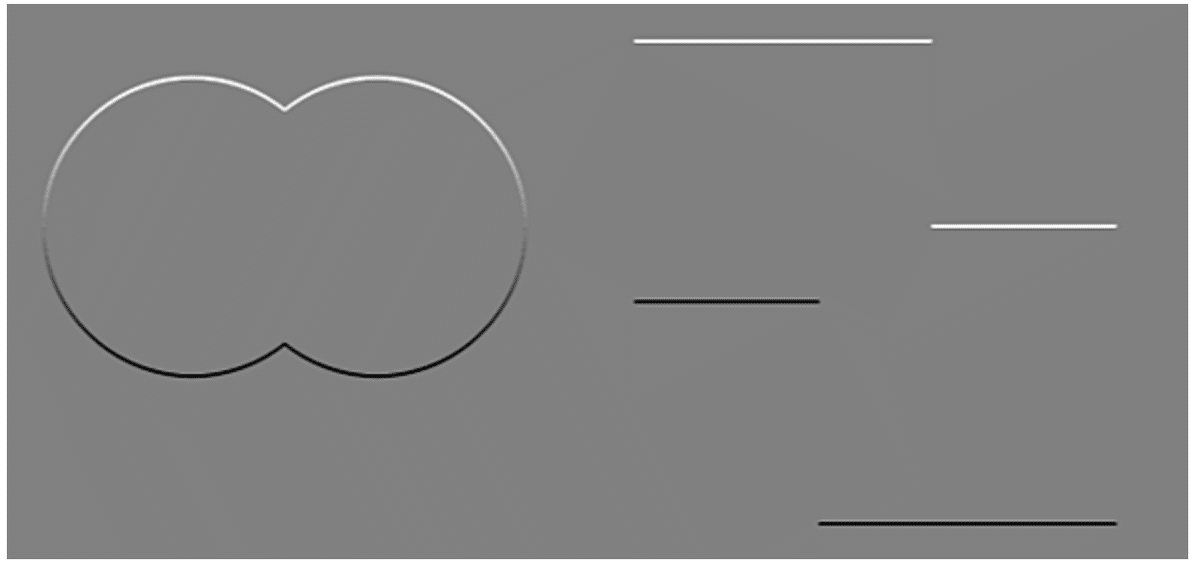
And the direction is like
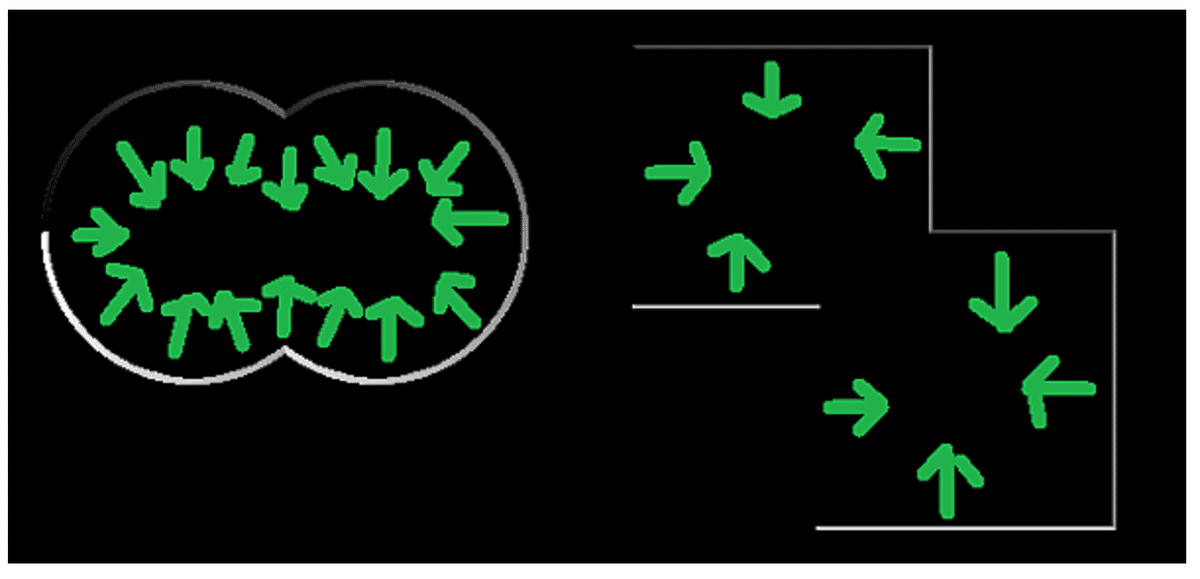
2) We take one quarter of the small image block, and we’re gonna compute the gradient orientation histogram from each quarter. From the different directions and different number of pixels that in each of those directions, then the next quarter, and next one. Then, we simply concatenating this orientation histograms together to create a long histogram. This is something we can directly use as a descriptor signature for matching two SIFT features
Q3. How is the mechanism used to generate texture and mesh at the same time as the point cloud?
This topic is quite open and not our main subject this time, so we don’t give detail explanations here. Still, we will show the idea and possible methods for converting the point cloud points to mesh.
This method is using elementary vector and geometry analysis to generate mesh
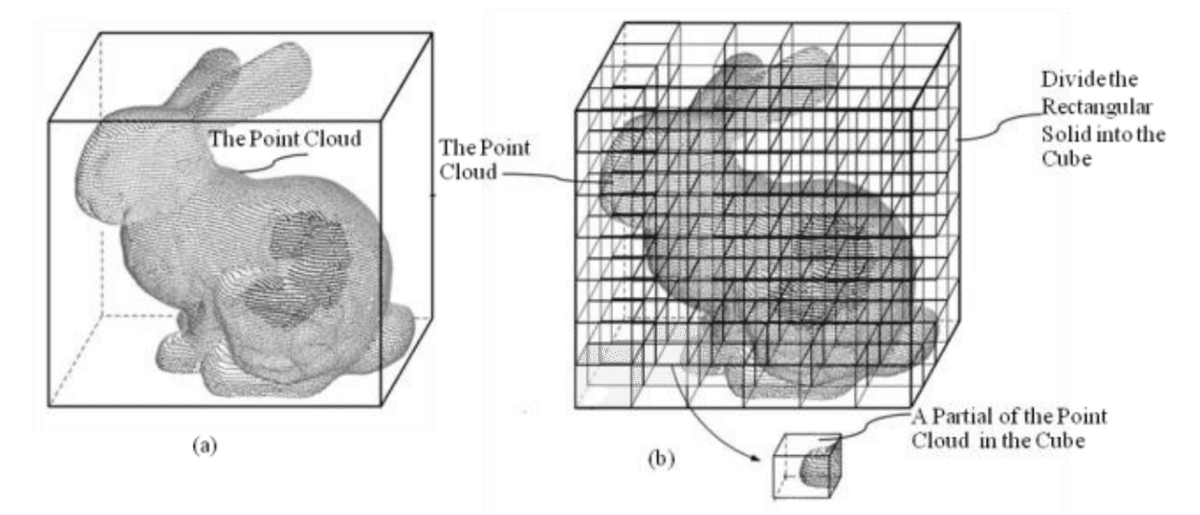
This method is using regression to generate mesh

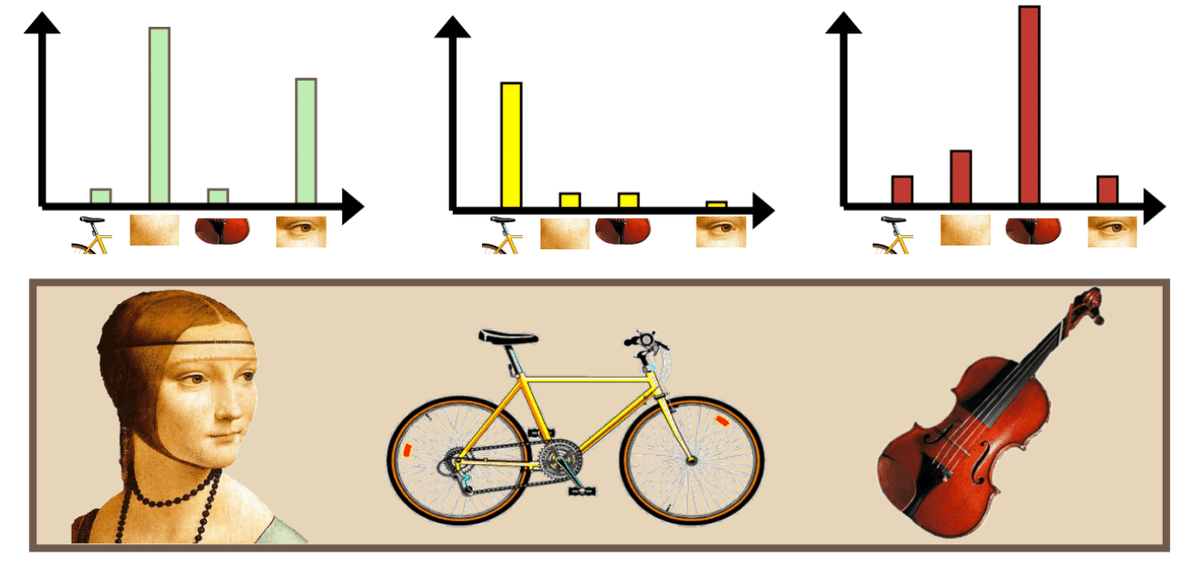
Q4. What are the criteria and mechanism for classifying feature points as visual words?
This is a quite basic computer vision question, we don’t dive into the detail or mathmatic formula, we only use a few of illustrations to show the idea. Hope this will give you an idea. This is representing the idea of the “bag of visual words”

We find the representative feature first, and the bag of visual words actually is a collection of the representative features.

With the representative features, we create a dictionary as metrics for the analysis

When we find a new image, we decompose it into features and compare the frequency of the features distribution.
この記事が気に入ったらサポートをしてみませんか?