
Krita-AI-Diffusionを使ったAI線画の作成方法

最初に
この記事の対象
1.Automatic 1111 web-uiやNovel AIなどText to imageの画像生成について一通りの理解や経験がある人(LoRAの使用方法がわかる程度)
2.Photoshopやクリスタなど、お絵かきツールの基本的な概念や操作方法を理解している人
※このドキュメントの内容は2024年7月10日時点での内容なので、今回紹介したソフトやプラグインのバージョンアップやその他環境的な要因の変化によって操作方法や手順その他が変わる可能性があります。
絵が描ける人のためのAIツール
最近とりにく氏作のAI-Assistantなどの登場によって、絵が描ける人向けにその作業を補助するために使うAIツールの流れが生まれつつあります。
これまで「描ける人」にとってのAI画像生成は主に、
1.生成される画像を細かくコントロールできない。
2.アルファチャンネルやレイヤーなどが基礎的な仕組みに組み込まれていないために、Photoshop等のツールとの連携に手間がかかる。
3.その他の理由。
によって普及していませんでした。
しかし最近になって様々なポーズや構図への対応力が高いSDXL用のチェックポイントと、ControlNet(以後CN)で使いやすいモデル(例えば月須和奈々氏のanystyle・anytest)の登場によって1が解決しつつあり、それを足がかりに2の問題についても解決の糸口が見えつつあります。
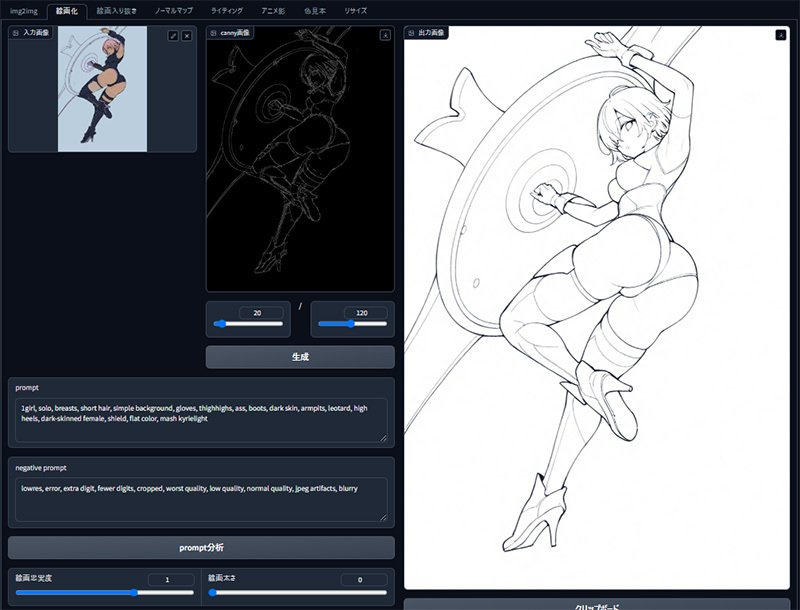
入り抜きについても非常に綺麗にこなしてくれる
しかし今回は上記のアプローチとは別に、既にお絵描きツールとしては一定の評価を得ているフリーソフト「krita」のプラグイン「krita-ai-diffusion」と、おなじみAutomatic1111 web-uiを使ってtext to imageで出力したイラストをもとにAIで線画を仕上げる工程について解説します。
なお今回はAIで生成した画像を基に線画を生成していきますが、手描きのラフ画をベースに線画をAIで仕上げる事も可能です。
Krita-AI-Diffusionについて
Krita-AI-DiffusionはAcly氏によるkrita用のプラグインであり、内部的にはcomfyUIを通じて画像を生成し、その結果をレイヤーに出力する仕組みになっています。
そのため透明度やレイヤー機能(通常、乗算、オーバーレイ…etc)を使用可能で、ブラシなど様々な範囲選択ツールを使用して生成範囲を指定したり、生成した画像を直接レタッチや加工をする事ができるなど非常に便利な仕組みを有しています。photoshopを使ったことがあるならstable diffusionのモデルとLoRAが使える「生成塗りつぶし」機能という理解でOK。(つまり裸とかでガイドライン弾きを食らわない!)
このプラグインは一時期リアルタイム生成のデモで話題になったものですが、今回はそちらの機能ではなく通常の生成で使用します。ちなみにこのプラグインはSD用のプラットフォーム単体として見ても、comfyUIで動いているので非常に軽いのが嬉しいところ。
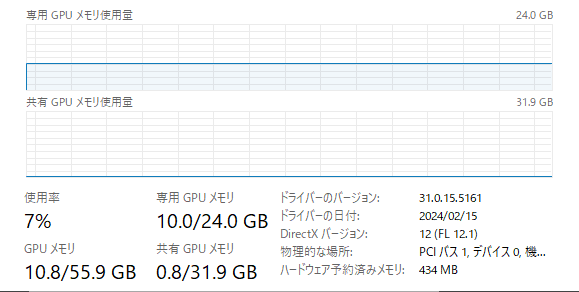
生成終盤のVAE使用時は一時的に12.5GBくらいになる
もっともSDXLモードで動作させるには概ね12GB以上のVRAMを持つミドルハイクラス以上のグラフィックボードが必要で、理想を言えばNVIDIA製の16GBクラスのグラボは欲しいところ(この点は既存のSD web-uiと同様)
なおRadeonやMacでも動作可能と謳ってはいますが、試した事はないので無事動作出来た人がいたら教えて下さい。(特にRadeonでの生成速度)
Kritaのインストールから出力まで
何はともあれまずはKritaをインストールします。
上記から最新のバージョンをダウンロードしましょう。
Kritaのインストールから起動までの方法については特に難しい箇所はないので省略します。好きな場所にインストールしてください。
Krita-AI-Diffusionのインストール
※この箇所はプラグインのバージョンアップに伴い古くなる可能性があるので、その際は公式のドキュメントを参照してください。
続いてKrita-AI-Diffusionを上記のページよりダウンロードします。
これも基本的に最新のバージョンで問題ないですが、この記事の作成では Version 1.19.0 を使用しています。
次にKritaを起動させたら、
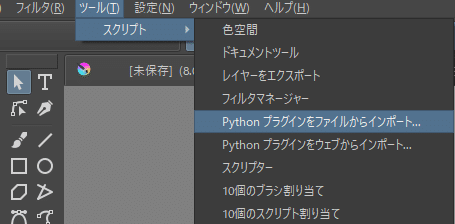
[ツール]→[スクリプト]→[pythonプラグインをファイルからインポート]
を選択し、ダウンロードしたプラグインの.zipファイルを直接指定します。(解凍したファイルは指定できない)
プラグインを有効にしますか?の確認のダイアログは「はい」でOK。プラグインのインストールが完了したら一度kritaを再起動させましょう。
次にプラグインのメニューウィンドウを表示させるために、
[設定]→[ドッキングパネル]→[AI Image Generation]
にチェックを入れます。
これでプラグインそのもののインストールは完了です。
ComfyUI(Stable Diffusion)のセットアップ
これでkrita-ai-diffusionのメインウィンドウが表示されるものの、まだ画像生成に必要なComfyUIとStable Diffusionを動作させる環境がインストールされていないため、ここではそれらのセットアップを行います。
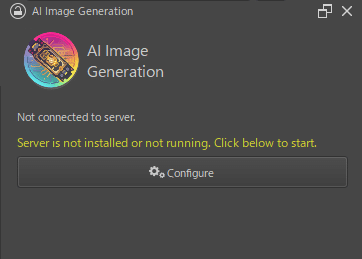
まずは上記の歯車マークの[Configure]をクリック。
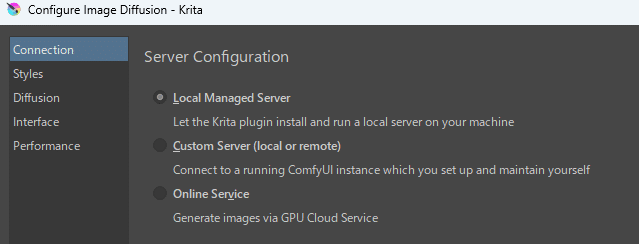
今回はローカル環境で動かすことを前提に解説するので、[Local Managed Server]を選択。
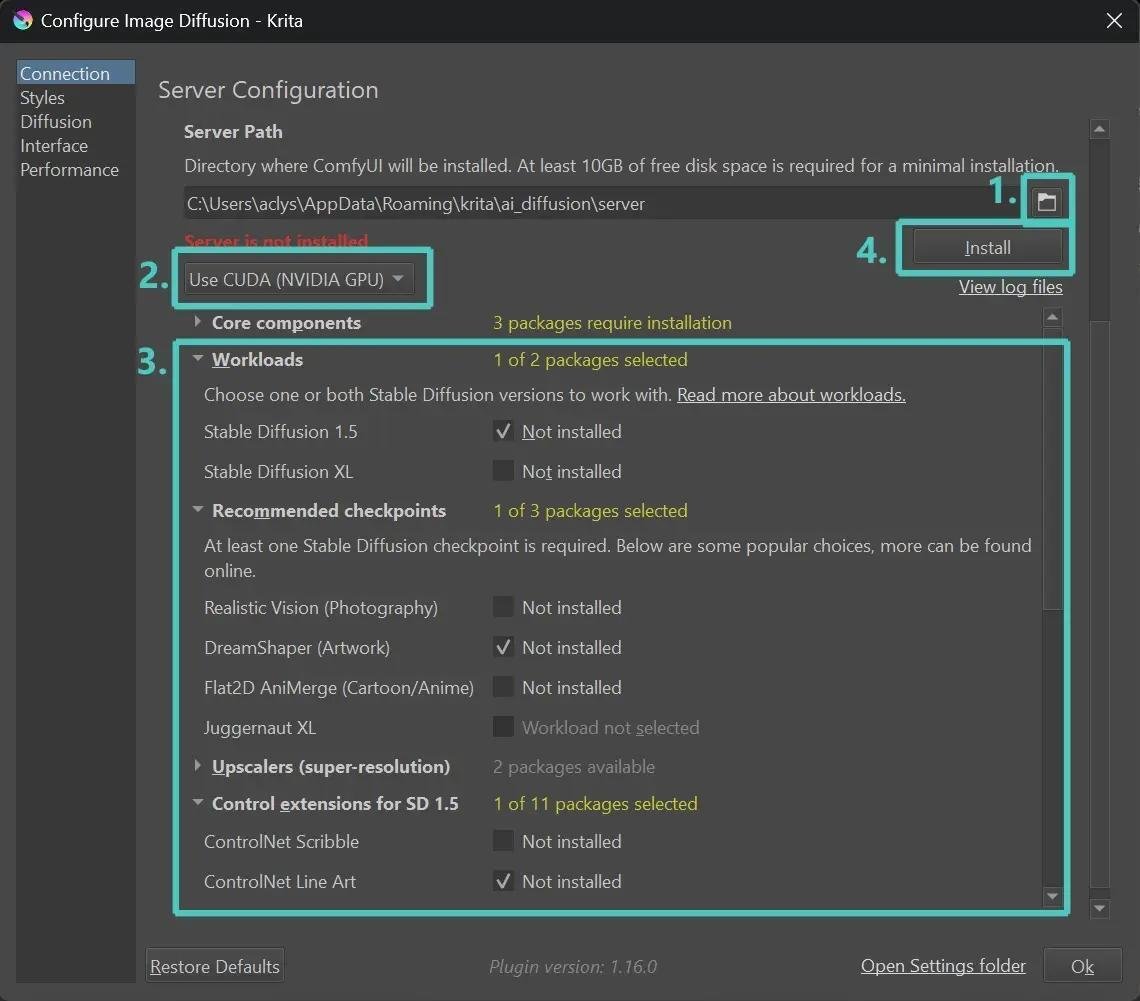
1.ComfyUIをインストールするフォルダを選択
2.Use CUDA(NVIDIA GPU)を選択(NVIDIA以外のグラボの場合はUse Direct MLを選択)
3.インストールするコンポーネントを選択、Stable Diffusion XLの場合はそれぞれSDXL用の[Workloads]と[Control extensions for SD XL]の各項目にチェックを入れる。[Upscalers]も多分入れておいたほうがいいと思います。
[Recommended checkpoints]に関しては予め使うモデルが決まってるのであれば特に必要なし。
4.[Install]をクリック
モデル等のダウンロードとインストールには時間がかかるのでしばらく待ちましょう。
次にStable Diffusion用のモデルおよびLoRAを用意します。
今回ComfyUIをインストールしたフォルダの [models] がモデルを格納したフォルダとなってます。
checkpoints: SD用のチェックポイントを格納するフォルダ(A1111やforgeの"Stable-diffusion"に相当)
loras: 使いたいLoRAを格納するフォルダ(A1111やforgeの"Lora"に相当)
それぞれサブフォルダを作ってモデルを分類する事もできます。
また既に他のweb-uiの環境があってそちらとのモデルの重複させたくない場合は、シンボリックリンクを作成して上記フォルダ名にすることも可能。
(※「シンボリックリンクって何?」って人は普段使いするモデルだけをコピーしておきましょう)
次に今回の線画作成に必要な線画LoRAをダウンロードします。
この系統は色々とあるので一概にどれがいいとは断言できないものの、flat LoRAの制作者でもある月須和・那々氏(https://x.com/nana_tsukisuwa)が作成した"sdxl-lineart_11.safetensors"(https://huggingface.co/2vXpSwA7/iroiro-lora/tree/main/sdxl)や
AI-Assistantでも使用されているとりにく氏(https://x.com/tori29umai)の"sdxl_BWLine.safetensors"(https://huggingface.co/tori29umai/lineart/blob/main/sdxl_BWLine.safetensors)が線画LoRAとして非常に使いやすいようです。
だけどもし自作の線画LoRAや、civitalなどにある気に入ったLoRAがあればそれらを導入しても構いません。
次にstyleファイルを作成。
styleファイルとは使用するモデルやLoRA、基本的なタグ(クオリティタグやモデルごとに推奨されるネガティブプロンプトなど)、デフォルトのサンプラーを指定する設定ファイルで、これを一度設定をしておけば以降はこのスタイルを切り替えるだけで生成に関する設定を切り替える事が可能な仕組みです。
モデルや使用するLoRAのなどを頻繁に切り替える人にはありがたい。
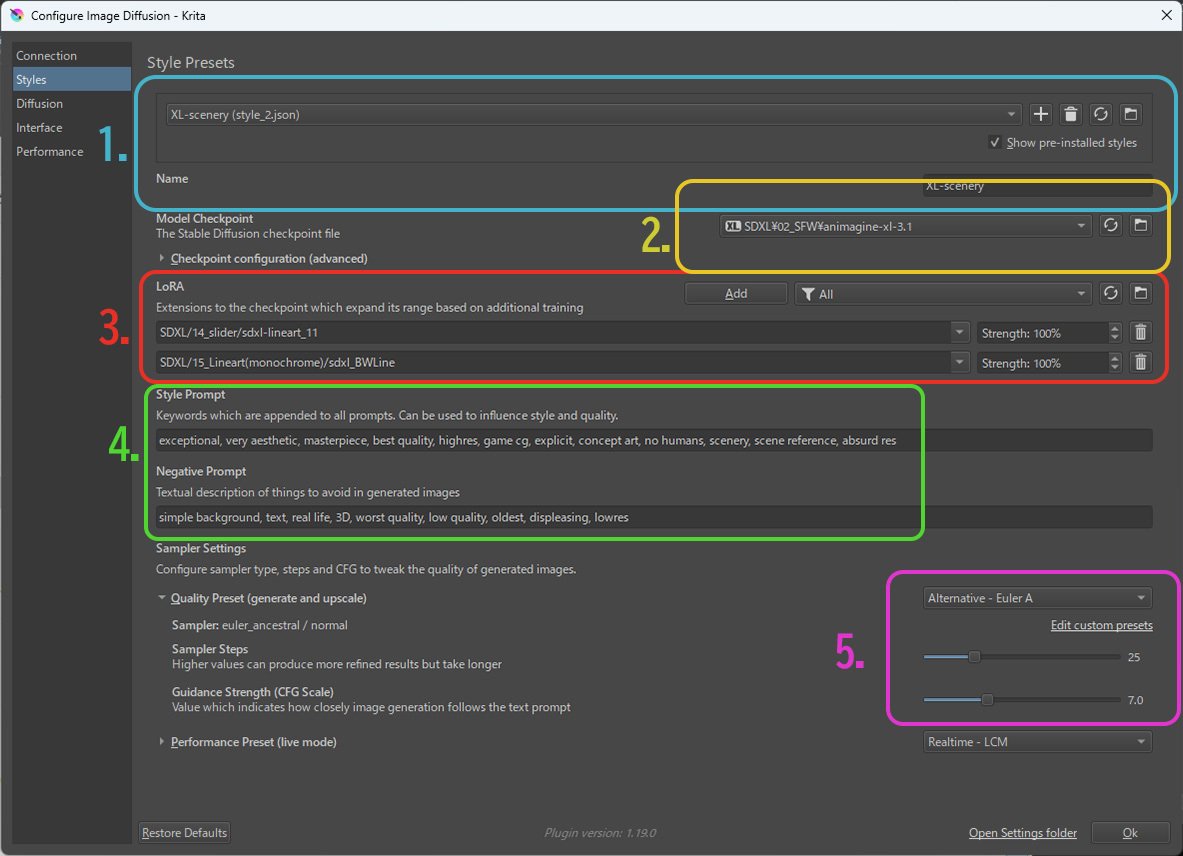
1.[+]ボタンで新たなスタイルを作成、スタイル名はわかりやすいものを入力する(モデルの系列やモデル名、何を生成するかの用途…etc)
2.スタイルで使用するモデルを選択。
ベースモデル、booru語系モデル(Animagine等)、pony系モデル以外にも使いたいモデルがあれば選択が可能(なお2024-07-10現在、SD3.0 mediumにも対応済み)
3.使用するLoRAを登録する。
今回は"sdxl-lineart_11"と"sdxl_BWLine"を登録。
Strengthの値はA1111 web-uiにおける0.0~1.0が0%~100%に対応(つまり0.6の強さで使用する場合は60%)
4.スタイルでテンプレートとして使用するプロンプト・ネガティブプロンプトを記述する。
概ね<クオリティタグ+モデルごとの独自のレーティングタグ>
ただしそれらをどのように記述するべきかはモデルごとに違うので、使用するモデルごとの説明のページを確認のこと。
5.サンプラーの選択
[Quality Preset (generate and upscale)]にサンプラーとその設定を行う。
モデルごとに推奨の設定があればそれを入力。
よくわからなければEular_Aの25steps、CFGは6.0~9.0くらいにしておく。
(※下側の[Performance Preset]はライブモード用なので今回は使用しない)
これで基本的な設定は完了、さっそく出力のテストをしてみましょう。
krita-ai-diffusionの基本的な操作
生成は他のweb-uiと同様にプラグインのウィンドウにおなじみのプロンプトを入力して、それぞれのレイヤーを対象に行います。
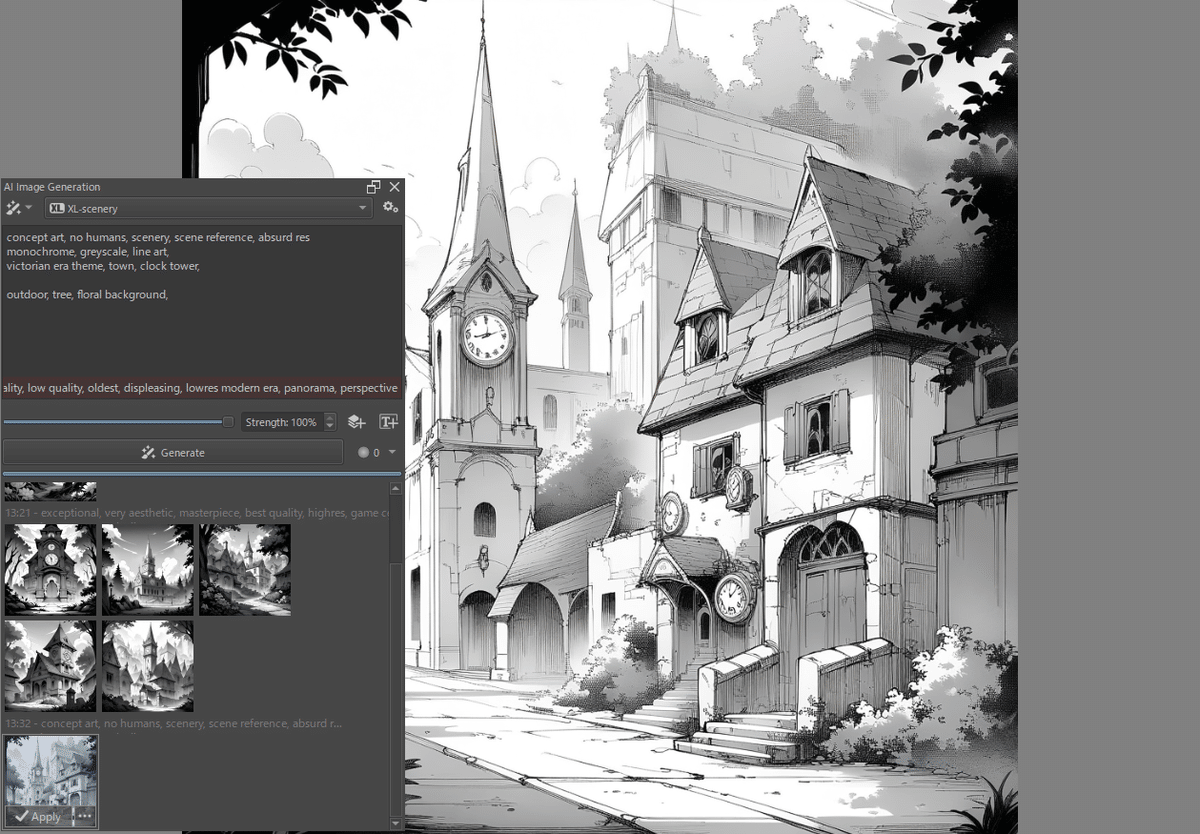
基本的には上の画像のように
プロンプト:スタイルで設定したクオリティタグに続く内容を記述
ネガティブ:同様にスタイルで設定したネガティブプロンプトに続く内容を記述
あとは[Generate]をクリックすると、その結果がサムネイルに表示されるので、何度かガチャを回して気に入ったものを[Apply]で選択。決定されたものが新規レイヤーとして追加されます。
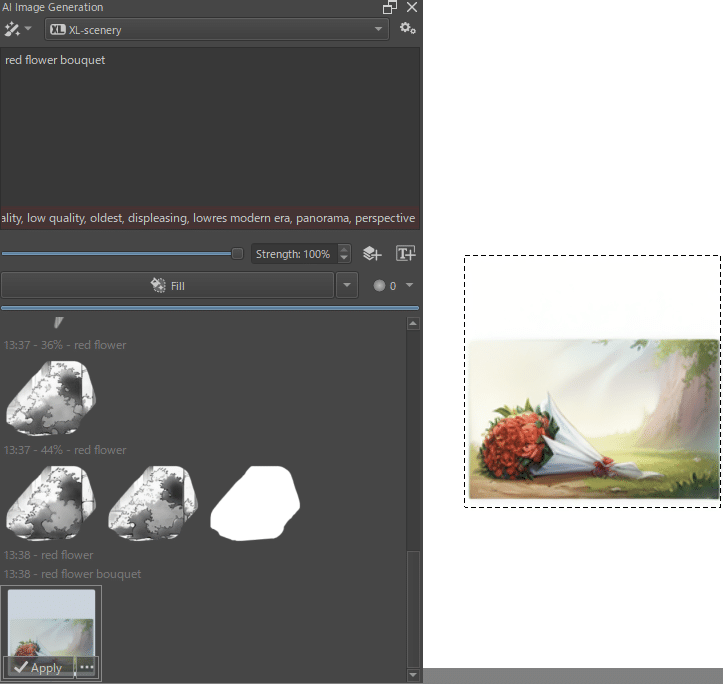
画面全体ではなく範囲を指定して生成する事もできます。

また人力ADetailerとして特定の箇所だけを選択してi2iによりディティールを整え出力しなおす[Refine]という機能もあります。この時だけ特定のLoRAを使用するといった事も勿論可能。

モデルの限界までAIで整えた最後は直接手で修正するといった、AIと人間の強みを合わせた共同作業が同じソフト内で完結できるのがKrita-AI-Diffusionの強みと言えます。
またControlNetのscribleで使用する画像を直接krita内で描いて、それを基に画像を生成するという事もできます。
このあたり逐一別のソフトを立ち上げてエクスプローラーからファイルをドラッグアンドドロップして……とかせずに、単体のソフト内でサッとできる点は結構ありがたい。

今回は[Refine]を使った言うなれば「人力ADetailer」によって、こちらが指定した線画の箇所をAIに逐次ブラッシュアップしてもらう方法で生成を行っていきたいと思います。
AIによる線画化の手順
さて、ここからが本題。
線画化したい画像を用意する
今回はcivitaiで見つけたLoRAで出力した、こちらの笑顔が素敵な某アイドルの画像を線画化してみることにします。

今回はAIで出力した画像を線画化しているものの、既に述べたように手描きでも半ラフくらいの画像なら同じ方法で線画化が可能です。
手順についても特に違いはありません。
プリプロセッサーによって画像を処理する
まずはAUTOMATIC1111等のControlNetが使えるweb-ui(あるいはforge等でも可)で画像の下処理を行います。なお必要なのはプリプロセッサーによる処理だけなので、プロンプト等を用いた画像の出力は不要です。
まずはtxt2imgでもimg2imgでもどちらでもいいので、ControlNetのタブを開いて線画化したい画像をドラッグアンドドロップしましょう。
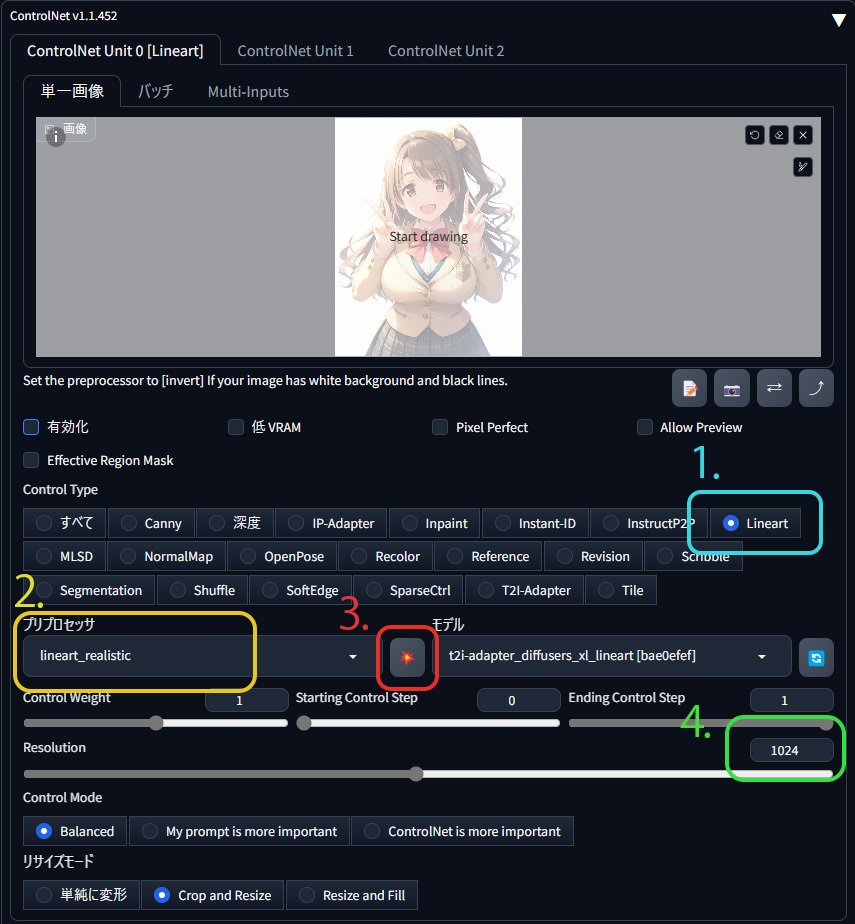
1.Lineartを選択
2.プリプロセッサは任意のものを選択(後述)
3.これをクリックして処理開始
4.デフォルトでは512pxだけども、処理後の画像の解像度に関わる数値なので最低1024pxは欲しい(ただし後述する理由により大きければ大きいほどいいわけではない)
5.最後に処理した画像の白黒を反転
プリプロセッサでやるならinvert系のものを使用、Kritaなら[フィルタ]→[調整]→[色相反転]
適切な下処理済み画像とは?
この線画化前の下処理で最終的に出来上がる線の雰囲気が結構変わってしまうので、まずプリプロセッサごとにどんな結果になるのかを比較したいと思います。
線画化に向いたCN-Lineartの主要なプリプロセッサ4種を用いて1024pxにて処理した結果は以下の通り。

このようにrealisticがまず圧倒的に処理の仕方が綺麗で、髪のハイライトや細かい房までしっかり出力できている上に輪郭もしっかり追えてます。次点でanimeとanime_denoiseの2種は細かいディティールや輪郭が消えている部分などがあるものの主要な線はある程度捉えられてます。一方coarseはこの中では一番ラフに近いタッチになっていて、情報量が多い箇所で不可思議なタッチの形跡が。
こうして並べてみると「見た目がいいし線画化するベースならrealistic一択では?」と思うかもしれませんが、この結果を基にあくまでAI側で線画として整えるのが目的とすると案外そうとも限らなかったりします。
AI(SD)は情報の欠落には強いが、情報の過剰は苦手
例えば画像生成歴がある程度の人なら経験があるとは思いますが、CNの参照用の画像の腕の途中が無かったり、場合によっては頭すらなくても問題なく生成される一方で、i2iの際に腋の下のちょっとした線がお尻とか性器とかに超解釈されたりすることがあります。
どうもAI(SD?)は情報の欠落には割とうまく対応できる一方で、ごく小さな線といった本来無視してもいい情報が(モデルの癖などによって)突然1girlやNSFWな要素に大化けしたりするわけです。

このことから線画に使うベースは先ほどのanime系のプリプロセッサのように輪郭や鼻の線が欠けてるような画像が必ずしもダメというわけではなく、逆に一見精緻に見えても情報量が多い画像は思わぬ事故の原因になったりします。
つまり情報量(線の量)については後の工程のやりやすさ等も考慮して多すぎず・少なすぎずの程々がいいと思います。
ただ線の細い・太いは後で調節するとなると非常に面倒なので、どの程度にするかは予め決めておいたほうがいいでしょう。逆に色の濃い淡いはいくらでも調節できるので基本的に問題はないですが、経験則上ある程度淡い線のほうがAIに処理させたときに良い結果になりやすいです。
なお今回は敢えてlineart-realisticの出力を選択します。
ちなみにどうしてもCNのプリプロセッサを使わないといけないわけではなく、Photoshopやクリスタなどが使えるのであればそれらの輪郭検出系機能を使っても問題ないでしょう。
というか出力だけ見ればむしろこちらのほうがいいかも?ただしそれぞれ「癖」みたいな挙動もあり、特にクリスタのイラスト化は細切れの線が生まれやすいので、同ソフトの[ごみ取り]機能も併せて使う事をオススメします。

(余談)そもそも最初から線画で出力しないの?
これに関しては当初試行錯誤していたものの、むしろ「やらないほうがいい」という結論に…。というのも
・元々カラーの画像を出すことに重点を置いている各モデルに対してプロンプトやLoRAを駆使しても、ベタなどがない「完全な線だけの画像」を出力できるかはケースバイケースだったりガチャを要したりする。
・なら線画を出すことに特化したモデルやLoRAが作ろうとしても、それで必ずしも望んだ絵柄を出せるとは限らない(そうすると更にモデルの調整だの層別だのの沼にハマる事に…)
・そもそもどんなモデルでも「純粋な線画」の学習データが少ない関係で、線画が出力できてもカラーイラストと比べてクオリティが劣るケースが多い。
・(生成AIで出力したものを使うなら)線画のベースとなるカラーの画像があるほうが線画以降の工程で便利だったりする。例えばベースの画像を2値化してベタにするなど様々な使い回しが効く。
・なにより一部のプリプロセッサやPhotoshop等のフィルターが優秀すぎて速度や手間の面からもこれがベスト。

木は悪くないものの、人工物は謎構造が多発
これでも割とチェリーピック気味だったりする
特に背景が絡むと生成AIの出力したものはアイレベルや人工物の構造に難があるので、それなら無理に線画で出力するよりは自分で撮った写真や、権利的に問題のないフリー素材等、あるいは他の背景関係が得意な生成AIが出力したものをベースにしたほうが明らかにかかる手間は少ないでしょう。
あくまで「現時点では」なので今後の技術の発展によってはどうなるかは分かりませんし、あるいは来年の今頃にはイラストの各工程ごとにレイヤー分けしたものを出力してくれるAIが出ているかも?
線の整理
ここからはプリプロセッサが出力した線画の素から、前述したようなAIが誤認しそうな余計な線を減らすために加工をします。
「人間の目から綺麗に見えるか?」はひとまず置いといて、あくまで以後の工程で人間とAI側がスムーズに作業できるかを基準にして…
・スカートのチェック模様、ボタンのディティールといった塗り側で表現する箇所は消す。(本来は目の内側のディティールも消すべきだが、今回は最後まで残しておく)
・明暗の境目に出てしまっている稜線も後の工程で間違った解釈の原因になる可能性があるので消す。
・前後関係の怪しい髪の房や、服のディティールと繋がってしまっている髪などは手で修正する。
・指周りの怪しい箇所や服装でおかしい箇所は予め直しておく(ジャケットの校章の左右と、ボタンの数などが違っていたため)ちなみに髪のリボンはどうも別の制服系コスチュームのものが混ざってしまったものの、可愛いので残しておくことに。
・単にガタついたりジャギが出ているだけの線は、この後にi2iをする段階で修正されるので特に手を入れなくてOK。とにかくAIの解釈に影響を及ぼす構造的な線を整理する。
結果は以下の通り

先程も述べた通り余計な線を生成しないプリプロセッサ等のほうが、この工程や後のi2iにかかる時間が少なく済む事が多いのが悩ましいところ。
ひたすらi2iをしていく
ここからようやく本格的なAIを使った作業に。
まず単に線画を均していくだけといってもプロンプトは必要なので、kritaの[AI Image Generation]ウィンドウでスタイルを選んだ後にプロンプトの欄にキャラクター生成時に使用したプロンプト(クオリティタグは抜き)を記述しておきます。
ただしプロンプトの色に関する語句(例:brown hair, blue eyes等)があるとその部分だけ色がついてしまうことがあるので、そこは削っておきましょう。(もっとも後から画像を白黒化できるので過度に気にする必要はなし)
今回はpony系モデルなのでe621タグを使用、なお手描きのラフなどを加工する場合はその画像を説明するプロンプトを自力で考えるか、あるいはtaggerなどでタグ出ししたものを入力しておきます。
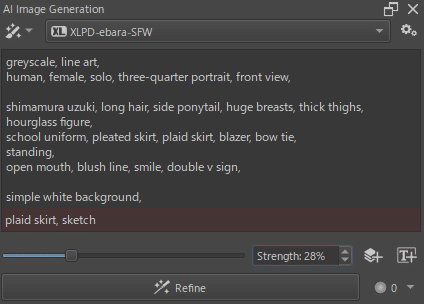
プロンプトについては特定のタグが線画の修正途中で局所的に悪さをする時があるので、その際は該当するタグを一時的に削ってしまうのがいいでしょう。
上の例だと髪飾りに関するタグを意図的に省略、あとplaid skirt(チェック柄のスカート)も不要でした。
また今回生成するのは線画なので、グレースケールの線画である旨の記述もしっかり入れておきます。
参考までに線画に関するタグはこんなものがあります。
booruタグ
lineart, greyscale, monochrome,
e621タグ
line art, greyscale, hatching (art)
(※monochromeは特定の色調でまとめた画像にも当てはまるケースがあり、またe621のblack and whiteは純粋な線画ではなく白と黒ベタだけで描かれた絵のタグになるので注意)
e621・booruタグともにsketchをネガティブに入れたりすることもあります。このあたりは欲しいタッチやLoRAの「癖」に合わせて調節してみてください。
キャラLoRAについては制作者推奨の数値(0.6~0.8)を使用。

lineart_11とsdxl_BWLineについては、おそらくpony用に作られたLoRAではないので通常のt2i生成ではもっと強めにかける必要があるものの、今回は予め白黒になっている画像を変化させていくだけなので0.6程度からお試しで。
ここから生成に移るわけですが、基本的にi2iの要領で既に線を変えていくのでStrengthは20%~40%(0.2~0.4)を目処に[Refine]をかけて元の線を激しく崩さないように整えていきます。
あまりStrengthを上げすぎるとプロンプトの要素を強引にねじ込んできたり、あるいはまったく線を無視した別のものを出力されてしまうので注意。逆に輪郭線が消えてしまった箇所などに無理やり線を足したい場合は強めにかける必要があります。
今回はひとまず24%程度の強度で画面全体を、その後に顔周りだけを再度i2iした結果、以下のような結果になりました。

これだけでも一見スッキリしたように見えるものの、顔周りをアップにすると…。

このように線が比較的滑らかな顔周り(範囲を小さく取ってi2iをした箇所)と、線がガタガタのままになっているそれ以外(画面全体をi2iした箇所)に分かれてしまってます。
これはADetailerの仕組みと同様に、小さい範囲で生成しなおした箇所が綺麗に見える現象なので、これ以降は綺麗にしたい場所は小さく範囲指定して線を生成し均していきます。
その際、間違って線が繋がってしまったりあるいは逆に線が途切れてしまった箇所、あるいは構造的に矛盾が発生してしまった箇所が発生することがあるので、これについては都度ブラシ描くなどして線を繋いだり消したりしてi2iしていきます。
もっとも難しい事は考えずとも小分けに範囲指定して画像全体をi2iをするだけで線は滑らかになっていくし、線を切って繋ぐ際も適当なブラシで描いて[Refine]するだけで自動的に全体の質感に馴染んでくれるので割と単純作業に近いです。

先ほどこのi2i作業を「人力ADetailer」と書いたものの、画像全体を細かく分けてi2iをかけていくという意味においては「人力Tiled Diffusion」(画面全体を細切れ分けて生成することで限られたVRAMで巨大な画像を生成するA1111用テクステンション)と言ったほうがより正確かも?
ともあれ画面全体にi2iをかけつつ細かい手直しを入れるとこのようになりました。

ここから先は手で斜線(ハッチング?)を入れるなり、あるいは線が重なる箇所に墨を入れるなり、各人のこだわりに応じて加筆してください。
でも今回は印象が変わった原因と思しき目元と口元を修正して、とりあえず一区切り。

濃淡の調整と透明化
今回の線画は基本的にグレースケールでの生成で終始行けましたが、モデルやLoRAによってはプロンプトを無視して微妙に色がついてしまったり、i2iをしているうちに線がどんどん淡くなってしまったりするケースがあったりします。
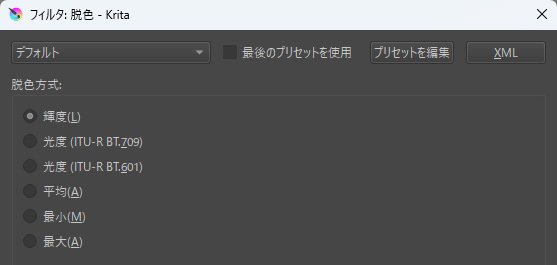
なのでまず濃淡を整えるために画像を白黒化します。
[フィルタ]→[調整]→[脱色]で白黒化。
脱色方法はデフォルトの輝度で問題ないかと。
次に[フィルタ]→[調整]→[レベル補正]で線画の黒部分を濃く(あるいは逆に淡く)する。黒のカーソルを中央に寄せると黒を濃く、白のカーソルを中央に寄せると明るい箇所を白に寄せることができます。
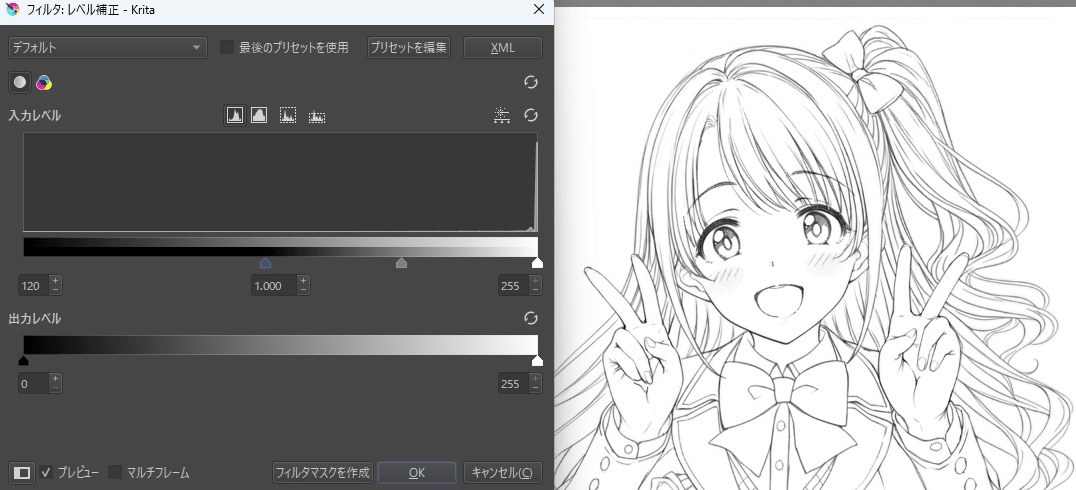
微妙なグレーを残さないために白側のカーソルも動かしたほうがいいかも
最後に透明化の処理です。
画像の白部分を透明色に抜いて線画レイヤーを下地なしの線画だけにします。(クリスタの「輝度を透明度に変換」に相当する機能)
[フィルタ]→[色]→[色をアルファに]を選択し、対象の色を白の頂点に合わせます。
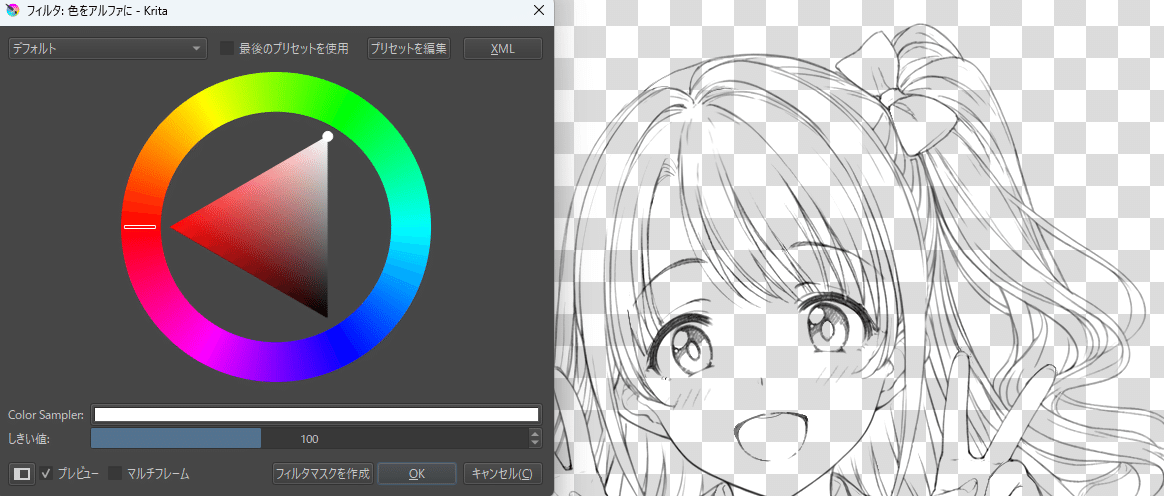
線画だけを抜けたらこれで完成です。
文字にすると長くなってしまうものの、ここまででやった事は
1.プリプロセッサなどで線画化したい画像を下処理(手作業が必要ならば適宜)
2.細かい手直しを入れながら画像全体を細かくi2i
3.濃淡を整えて透明化
これだけです。
今回は髪のディティールが複雑すぎるキャラを選択したり、線が細かいプリプロセッサを使用したために結構時間がかかってしまったものの、必要とする情報量がどの程度かの目処がついていればもっと時間を節約できると思います。
あと留意するポイントとしてはキャラLoRAを使う場合は、その画風によって線画の雰囲気も変わってしまうという点です。これについては「どのLoRA(とモデルの組み合わせ)がどういう線を出すか?」はモノによるとしか言いようがないので、それぞれの好みを探してみてください。(おそらく漫画やアニメのベクトルに寄ったもののほうが滑らかな線画になるかも?)
なお今回の方法は背景でも使えます。
直線が主体の背景なら、線が歪んだりしないDALL-E3などで出力した画像をベースにすれば、線がくっついたり切れたりといった修正には殆ど時間が取られなくて便利です。

所要時間約3分ほど。
冷蔵庫が2つあるとか、レンジフードがあるのにコンロがないとか、エアコンがワンルームには大きすぎる業務用という点は気にしない。
いかにもAIな家具等の怪しい箇所は、他の画像から切り貼りしてしまえばOKというお手軽さも◯。
アップスケールでA4サイズ以降に対応させる
「でも所詮は生成AIの解像度でしょ?」
まぁその通りです。
現状ではまだSDXLの解像度(1024x1024付近)の約104万ピクセルと、印刷に使うA4の解像度(2480x3508)のピクセル数にはおおよそ8.4倍の差があり、

SDXLの解像度ならこれでも結構綺麗に生成できます
A4サイズのキャンパス上でこんな感じで線だけを選択して、総ピクセル数を減らす方法でi2iを行うにしても、8.4倍ものピクセル数があるとそもそも「大きく生成したものを縮小する」という勝ちパターンが殆ど通じません。
そもそもi2iしたものを更にi2iするというのは言うなれば「作業のやり直し」になってしまいますし。
(※なおA4サイズのキャンバスで全体を使って生成しようとすると、メモリ不足で最悪PCがフリーズする事があるのでやめましょう)
アップスケーラーの選択
なので基本的には今回の手順で作成した画像をアップスケールして、A4サイズに適合させることになります。
世の中にはアップスケールの手法や対応しているソフトやたくさんあるものの、線画を綺麗に拡大できるものとなるとある程度絞られてくることになると思います。
とりあえずひとつずつ検証してみましょう。
Photoshopの「スマートシャープ」
Photoshopさえ使用可能ならサクッと使用できるものですが、画質については細部を拡大すると流石にぼやけが目立ち、やや難が残るところ。
もっとも引きで見るなら十分なのでフォトショップが使えてお手軽さを重視するなら選択肢には残ります。

Photoshopの「スマートシャープ」で処理した画像のアップ
見ての通りさすがにぼやけてしまう
Automatic1111で使える各種アップスケーラー
無料で使える点は大きいですが、現状はオススメできない選択肢です。
これについては拡大結果の細部を見てもらえば一目瞭然でしょう。

シャキッとしてるものの拡大すると線がグチャグチャ
そもそも線が完全に別物になってしまっているのが残念。
Tiled Diffusionによるi2i
現状ではこれが一番マシな結果になりました。
具体的には線画をTiled Diffusionによって小分けにしながらi2iで3倍(2688x3456)に拡大する方法です。

若干ぼやけるものの、処理ミスで残ったゴミみたいな線もしっかり残っている
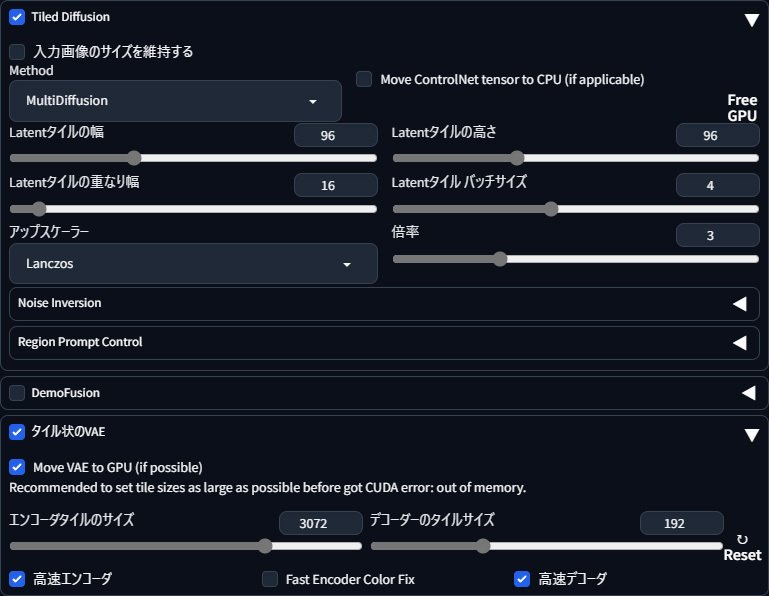
この方法で使ったTiled Diffusionの設定のスクリーンショットも以下に残しておきます。
一応i2iなので一応プロンプトは線画を整えたときに使用したものをそのままに、画像の細部を一切変えずに拡大したいのでdenoiseは0.0~0.1でやっています。
といってもこの分野は全然専門ではないので、もっと良い設定やアップスケールの手法などをご存じの方がいたら、ツッコミ等よろしくお願いします。
アップスケーラーについては外部サービスでも優秀なものがありますし、ComfyUIで複雑なノードを組んで使用する上級者向けのものなどもあるので、今回紹介した方法以外でももっと綺麗に拡大できる方法があればそれらを使用してみるのもいいかと思います。
参考:
以上、随分と泥臭い方法にはなりますが、Krita-AI-Diffusionによって線画を作成する方法でした。
「生成AIを使ってわざわざ面倒な事をしたい」という奇特な人にこの方法が少し役に立ってくれればラッキーくらいに思ってます。
最後に
あと注意というかいわゆる常識というやつですが、この手法を使ってAIで修正した線画を「手描きで描きました!」ってのはやめましょう。(他の人の絵を無断で線画化して「自分が描きました」と発表するのはもってのほか)
そのような行為は速攻でバレる上に、AIに対して異なるスタンスを持ついずれの人々からも袋叩きにされて、貴方が築いてきた社会的信用は地に落ちるでしょう。
この記事を書いている現在、工程の一部にAIを使用したイラストが投稿サイトや同人販売サイトでどのような扱いになるのかは詳しくは知りませんが、まずはその旨を正直に表記・申告し(気になる場合は運営側に相談して)各サイトごとのカテゴライズに従ってください。
以上となります。
今回使用したKrita-AI-Diffusionは非常に柔軟な使い方ができるツールで、今回のような線画だけでなくAIを絡めた色々な活用方法があるので、いずれ余裕ができたらそちらも紹介したいと思います。
この記事が気に入ったらサポートをしてみませんか?