ランダムフォレストについて超ざっくり

ひとまず言葉の正確性などがかなり微妙ですが、とにかくアウトプットをということで。
前回に引き続き機械学習図鑑、という本で学習中。
https://www.shoeisha.co.jp/book/detail/9784798155654
ランダムフォレストはアンサンブル学習
いくつかの学習モジュールの合議でデータの判定を行う。
このように個別の学習モジュールの合議をとるような学習モデルをアンサンブル学習と呼ぶ。
学習モジュールとしては決定木をつかう。
大事なポイント
この決定木の構成方法でアンサンブル学習の性能が決定される。
たとえば、全く同じ結果を出す決定木がたくさんあっても、同じ答えがたくさん得られるだけでたくさんいるメリットがない。合議して答えを出してほしいのに全員賛成。
どうやって決定木のバリエーションをつくるのか?
・ブートストラップ法
学習させるデータのバリエーションをつくる。
・特徴量のランダムな選択
説明変数の一部を決定木の学習に利用しない。
また、特徴を表すデータを特徴量や説明変数といい、答えであるデータを目的変数やラベルといいます。(機械学習図鑑P. 4)
この二つの手法を組み合わせて決定木のバリエーションをつくる。
決定木のつくりかた
学習というのは、特徴量の空間にある要素に対してどのような線引きで分類を行うか、を決めることだと理解している。
決定木は線を引いて空間を二つに分ける、分かれた空間にまた線を、引いて分ける、というやり方で木構造をつくる。
判定したいデータを与えると根を出発点として、分割基準の線を判定条件として葉を辿って判定結果を得ることができる。
この線をどこに引くかを決めるのに不純度と呼ばれるばらつきの指標を利用する。
不純度というのは空間内に含まれる目的変数のバラバラ具合。
簡単に言えば不純度が高いとうまく分類できていない、低いとうまく分類できている、というように捉えることができる。
不純度の計算にはジニ係数が、よく用いられる。
1ステップの、空間分割でなるべく不純度が低くなるように線をきめる。
機械学習図鑑のサンプルコードを、変えて試してみる
# ランダムフォレストのサンプル
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# いつものグラフプロット用ライブラリ
import matplotlib.pyplot as plt
# データ読み込み
data = load_wine()
# 何回か出てきたテストデータ取得関数
# 今回の場合はロードしたワインデータから取得している。
# 入力系列、目的変数いわゆる結果、サンプリングしてくる割合
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
# 入力系列としては7次元ある。
#print(X_test)
# ランダムフォレストモデルの生成。
model = RandomForestClassifier(n_estimators=10,
max_depth=1)
model.fit(X_train, y_train) # 学習
y_pred = model.predict(X_test)
print(accuracy_score(y_pred, y_test)) # 評価
# 誤判別の要素を違う色で
result = []
for i in range(y_test.size):
result.append(1 if y_test[i] == y_pred[i] else 0)
# print(result)
# 7次元の学習結果の可視化は難しいと思うけどどうしたら良いんだろう。
# とりあえず6次元を別々にみてみる。
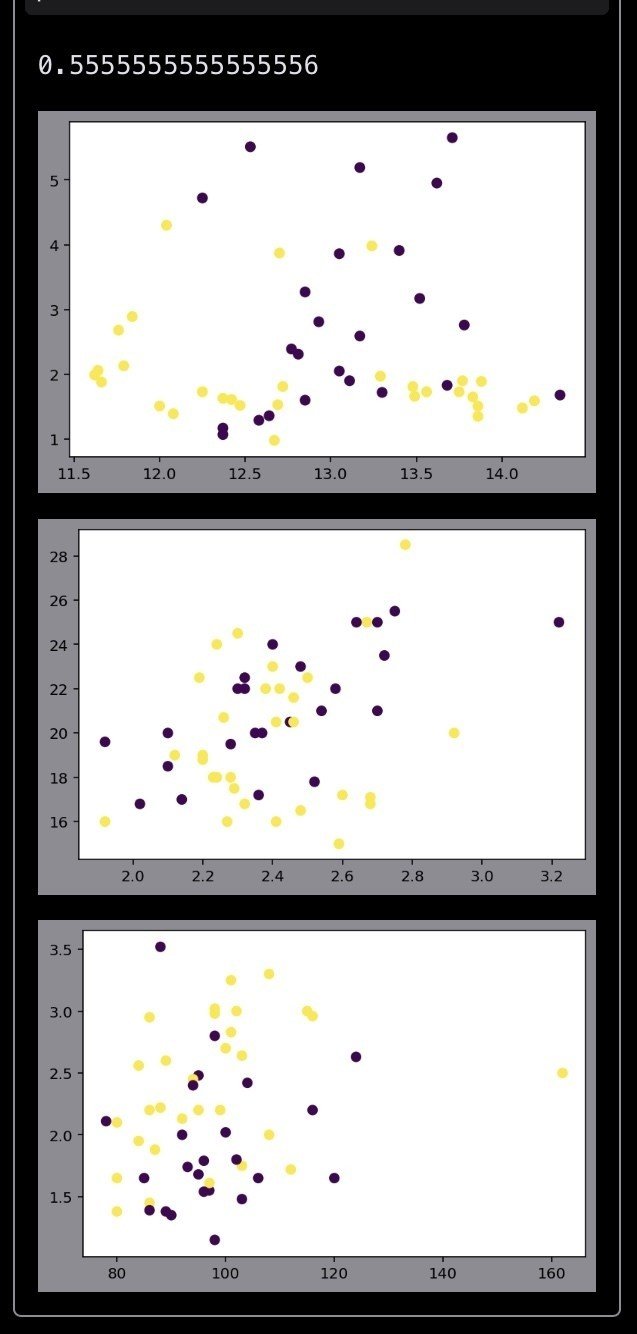
plt.scatter(X_test[:, 0], X_test[:, 1], c=result)
plt.show()
plt.scatter(X_test[:, 2], X_test[:, 3], c=result)
plt.show()
plt.scatter(X_test[:, 4], X_test[:, 5], c=result)
plt.show()コンストラクト時のパラメータについて少しメモ。
n_estimatorsは決定木の数。
max_depthは決定木の深さ。1だと根から1段だけ葉が繋がってるような木をイメージしてるけどあってるかな。
criterionは不純度の計算方法。
基本ドキュメントからの情報です。
n_estimators=1, max_depth=1で試す。
2分割だけできる木を一つ、なので、まぁ結果としてはこんなものかなぁと。
n_estimators=10, max_depth=1で試す。

決定木を10こにするだけで精度向上。(決定気のバリエーションをうまく作ってくれるようになっている、ということだとは思うけれど。)
参考
https://qiita.com/mshinoda88/items/8bfe0b540b35437296bd
機械学習図鑑 翔泳社
この記事が気に入ったらサポートをしてみませんか?