
RAG技術の新たな展開:文書間コンテキストの活用とその影響

LangChainチームの@Lance Martinが最近公開したビデオシリーズでは、大規模言語モデル(LLM)とRetrieval Augmented Generation(RAG)技術の進化について詳しく説明されています。このビデオでは、特に多くの文書からコンテキストを必要とする問いに対応するためのRAPTORのアプローチや、長いコンテキスト埋め込み技術、自己反射型RAGやC-RAGなどの新たな応答作成プロセスが取り上げられています。
関連ソース
Lance MartinのX:https://twitter.com/rlancemartin
Lance Martinまとめた資料:https://docs.google.com/presentation/d/1mJUiPBdtf58NfuSEQ7pVSEQ2Oqmek7F1i4gBwR6JDss/edit#slide=id.g26c0cb8dc66_0_0
Lance Martinの解説動画:
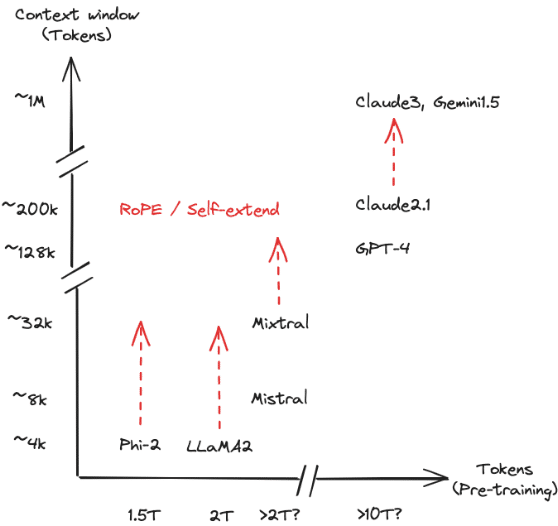
長上文LLMの現状と限界
コンテキストの拡大と影響:LLMの上下文窓が100万トークンを超えると、モデルの自己完結性が向上します。しかし、複雑な情報検索や事実確認では依然として外部データの参照が必要です。
多針索引分析法の導入:具体的な例として、多針索引分析は、特定の情報に対して高速かつ正確にアクセスするための方法として注目されています。
RAPTORの活用
多文書コンテキストの利点:RAPTORは複数の文書から情報を取得することで、より広範囲のコンテキストに基づいた回答を生成することが可能です。Lance Martinによると、このアプローチは特に複雑な問いに対して有効です。
実践事例:Jerry Liuの提案により、文書を横断するRAPTORの適用が試みられ、成功したと報告されています。
長いコンテキストの組み込み
Monarch Mixer(M2):Jon Saad-Falcon, Dan Fu, Simran Aroraによる研究で、32,000トークンまでの長いコンテキストの埋め込みが可能になりました。これにより、文書ごとのインデックス作成が向上し、より精確な情報検索が実現します。
自己反射型RAGとC-RAG
応答の検証と構築の流れ:従来の一回きりのRAGから、回答がチェックされ、反復的に構築される「フロー」への移行が見られます。自己反射型RAGとC-RAGは、この新たなアプローチを体現する優れた例です。
技術的詳細:これらの技術は、生成された回答が文書に基づいて正確であるかどうかを確認するための後処理推論を含むように設計されています。

技術的課題と展望
レイテンシの低減:技術の進歩により、処理遅延が減少しており、これが複雑なRAGフローの実現を可能にしています。特に、Groq Inc.などの企業による革新が寄与しています。
最後に
Lance Martinが提示するRAG技術の進化は、複数の文書から情報を抽出し、それに基づいて回答を生成することで、大規模言語モデルの能力を格段に向上させています。特にRAPTORの実装は、広範な文書にわたる複雑な問いに対して、より広いコンテキストでの正確な回答生成を可能にしており、LangChainの技術を通じて具体的な実例が示されています。また、Monarch Mixer(M2)のような長いコンテキスト埋め込み技術は、より精確な文書ベースのインデックス作成を可能にし、情報検索の精度を向上させています。これらの技術は、自己反射型RAGやC-RAGといった新しい形のRAGアプローチにより、生成された回答の質をリアルタイムで評価し、必要に応じて自己修正を行うことが可能です。この進歩により、大言語モデルはただ情報を再現するだけでなく、より深い理解と精度を持って情報を提供できるようになり、実世界の応用においてさらに有効なツールとなりつつあります。
この記事が気に入ったらサポートをしてみませんか?