
マルチモーダルAI革命:LlamaIndexによるRAG活用法

マルチモーダルAIの進化は、特に情報処理の分野で目覚ましいものがあります。最近の注目は、LlamaIndexによるマルチモーダルRAG(Retrieval-Augmented Generation)の迅速な導入です。これは、テキストと画像を組み合わせた知識獲得と生成を可能にします。この記事では、@clusteredbytesのツイートを基に、LlamaIndexを使用したマルチモーダルRAGの初心者向けガイドを紹介します。
マルチモーダルRAGの基本
画像に対する質問の開始: OpenAIMultiModalはOpenAIの最新のビジョンモデルをラップし、画像についての質問を可能にします。
画像ドキュメントの変換: LlamaIndexは画像ドキュメントをマルチモーダルLLMに適合する形式に変換する論理を処理します。
制限と解決策
画像数の制限: テキストベースのRAGと同様に、処理できる画像の数には制限があります。
関連画像の選定: クエリに関連する画像の選定は、ベクトル埋め込みを使用して行います。
マルチモーダルインデックスの作成
MultiModalVectorStoreIndex: 画像ノードには「clip」、テキストノードには「ada」を使用して埋め込みを行い、ベクトルストアに保存します。
マルチモーダルインデックスの作成: クエリに関連する画像とテキストノードをインデックスから取得するためのプロセスを設定します。
Multi-Modal AI is rapidly taking over 🔥🚀
— Rohan (@clusteredbytes) November 23, 2023
It’s truly amazing how fast @llama_index incorporated a robust pipeline for multi-modal RAG capabilities.
Here’s a beginners-friendly guide to get started with multi-modal RAG using LlamaIndex 👇🧵 pic.twitter.com/8Hjk702quk
クエリベースのノード取得
MultiModalVectorIndexRetrieverの作成: このリトリバーは、クエリをembed_modelとimage_embed_modelを使用して埋め込みます。
まとめ:マルチモーダルRAGパイプラインの図解
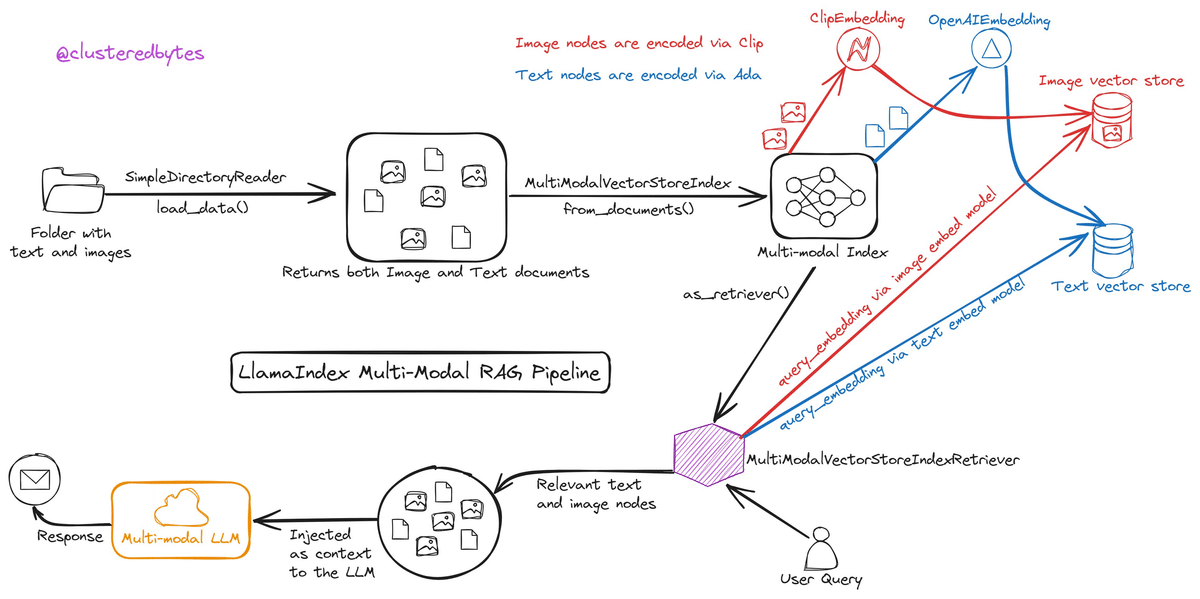
SimpleDirectoryReader: このツールは、テキストファイルと画像が保存されたフォルダからデータを読み取り、システムに供給します。
MultiModalVectorStoreIndex: 読み取られたデータは、画像は「clip」、テキストは「ada」のアルゴリズムを使用してエンコードされ、マルチモーダルインデックスに変換されます。
ベクトルストア: ここで生成された画像とテキストのベクトルは、それぞれ専用のストアに保存され、検索可能な形式になります。
クエリ処理: ユーザーからのクエリは、専用のモデルを使ってエンコードされ、関連するデータの検索に使用されます。
MultiModalVectorStoreIndexRetriever: エンコードされたクエリを利用して、関連するテキストと画像ノードをインデックスから取得します。
マルチモーダルLLM: 最後に、取得したノードはマルチモーダル言語生成モデルに注入され、ユーザーの質問に対する適切な応答が生成されます。
最後に
LlamaIndexを用いたマルチモーダルRAGの導入は、AIとデータ処理の分野で新たな可能性を開きます。画像とテキストの両方を扱うこのアプローチは、より複雑で多面的なデータ解析を可能にし、AIの応用範囲を広げています。初心者でも簡単に取り組めるこのガイドは、マルチモーダルAIの理解と活用の一歩となるでしょう。
この記事が気に入ったらサポートをしてみませんか?