
Wikidata:120億以上の事実データを含む開放的な知識ベース

Wikidataは、120億以上の事実データを含む開放的で無料の知識ベースとして、情報の真実性と検証可能性を高める上で重要な役割を果たしています。この構造化されたデータベースは、多言語に対応し、効率的な情報検索とデータ分析を可能にしています。さらに、WikidataはWikiWebQuestionsという高品質の質問応答データセットも含み、言語モデルの性能向上に貢献しています。
Wikidataの能力
広範な知識ベース:120億以上の事実にアクセスできる無料のオープンプラットフォーム。
構造化データの提供:自由形式のテキストではなく、構造化されたデータによる自動化処理とクエリの簡素化。
多言語対応:世界中のユーザーがアクセス可能。
多様な実体と属性:数百万の実体(人物、場所、物など)と属性を含む。
リアルタイム更新:グローバルコミュニティによるメンテナンス。
他のデータベースとの連携:豊富な背景情報と詳細情報へのリンクを提供。
WikiWebQuestionsの特徴
データセットの起源:FreebaseのWebQuestionsから移行し、SPARQLクエリと答えをWikidataに適合させた。
目的:言語モデルの性能評価に使用される高品質の質問応答基準を提供。
特徴:現実世界のデータとSPARQL注釈を含む。
適応性:Freebaseの閉鎖に伴い、より現代的かつ実用的なWikidataに移行。
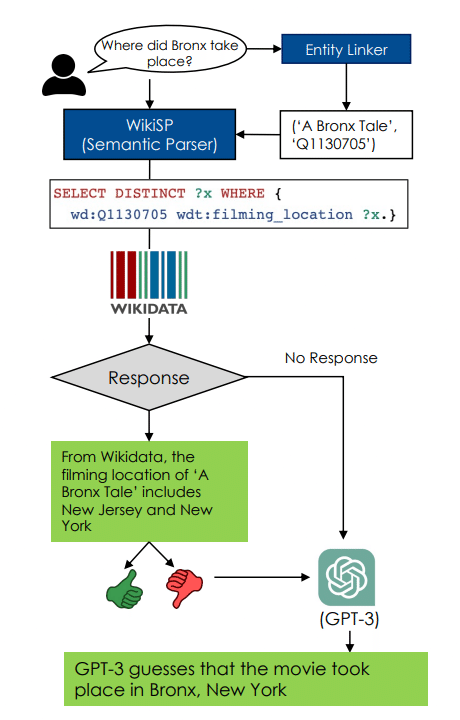
利用シーン
質問応答システムの向上:Wikidataを強力な知識源として使用。
自然言語処理の研究:NLP、特に意味解析と知識ベース質問応答(KBQA)の研究に利用。
AIと機械学習モデルの訓練:豊富なデータでモデルを訓練。
データ分析と知識発見:トレンド分析、相関発見などに使用。
多言語コンテンツ生成:多言語Wikipedia記事などの生成に理想的。
教育と研究:WikidataとWikiWebQuestionsを用いたプロジェクト実施。
WikiSP言語解析器
目的:自然言語クエリの理解と解析を改善し、GPT-3などの大型言語モデルの誤情報を減少させる。
Wikidataの利用:Wikidataを利用して事実に基づいた正確な答えを提供。
言語解析:自然言語クエリをSPARQLクエリに変換。
大量の実体と属性の処理:100M以上の実体と数十万の属性を効率的に処理。
少量サンプルの訓練:少量のマークアップデータで効果的な学習を実現。
実験結果と貢献
精度:WikiWebQuestionsの開発セットとテストセットでそれぞれ76%、65%の正解率を達成。
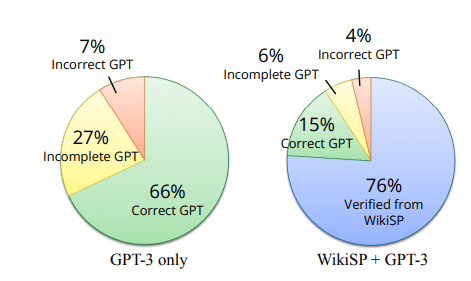
性能比較:既存のQALD-7 Wikidataデータセットに比べて、F1スコアが3.6%向上。
GitHubリンク:GitHub Repository
論文リンク:Research Paper
総括
Wikidataは、その膨大な知識ベースと構造化されたデータを活用することで、言語モデルやAI技術の進歩に重要な貢献をしています。多言語に対応し、リアルタイムで更新されるこのプラットフォームは、教育、研究、AI開発の分野で広く応用されています。WikiWebQuestionsデータセットとWikiSP言語解析器は、特に質問応答システムの性能向上において重要な役割を果たしています。