DP-600 (Fabric Analytics Engineer: Associate) 試験対策

資格概要
AIスキルチャレンジ:Fabric Analytics Engineer
1. エンドツーエンドの分析の概要
Fabricを構成するワークロード
・全てのワークロードがOneLakeに接続している
・Fabric=ADLS+ PowerBI
・Azure SynapseAnalysis、Azure DataFactory、Azure Databriks、Azure MachineLearningの機能が搭載されている
・Synapse Data Engineering: 大規模なデータ変換のための Spark プラットフォームを使用したデータ エンジニアリング。
・Synapse Data Warehouse: 業界をリードする SQL パフォーマンスとスケーリングを備えたデータ ウェアハウスで、データの使用をサポートします。
・Synapse Data Science: スケーラブルな環境でのモデル トレーニングと実行追跡のための Azure Machine Learning と Spark を使用したデータ サイエンス。
・Synapse Real-Time Analytics: 大量のデータをリアルタイムでクエリおよび分析するためのリアルタイム分析。
・Data Factory: データを移動および変換するため Power Query と Azure Data Factory のスケールを組み合わせたデータ統合。
・Power BI: データを意思決定に変換するためのビジネス インテリジェンス。


OneLake
・ALDS(Azure Data Lake Storage)上に構築されている
・Delta、Parquet、CSV、JSON などの任意のストレージ形式でデータを格納できる(既定の形式はDeltaParquet)
Fabric管理ポータル
Fabricにおけるデータ資産保護
Purview(データ資産の保護とコンプライアンス)と統合されているため、Purviewの秘密度ラベルを使ってデータ保護されている
DirectLakeモード
Fabricの有効化
Fabricはテナント単位(組織全体)または容量単位(特定のユーザグループ)レベル
Fabricを有効にするために必要なアクセス許可
・Fabric管理者(旧PowerBI管理者)
・PowerPlatform管理者
・Microsoft365管理者
ライセンスの種類
Fabricワークスペース
すべてのFabricアイテム(レイクハウス、ノートブック、パイプラインなど)は OneLake に格納され、Fabricワークスペースを介してアクセスされる
2. レイクハウス
レイクハウスの概要
2種のデータストア
・データレイク:柔軟でスケーラブルな分散ファイルストレージ
・データウェアハウス:SQLによる分析が可能なRDB
の特徴を組み合わせたもの

Fabricにおけるレイクハウスの実装
・ビッグデータ処理や機械学習のためにApacheSparkとSQLを使用している
・高可用性とDRを備えている
・スキーマオンリード形式:定義済みスキーマを使用するのではなく、スキーマは自分で必要に応じて定義して使う
・DeltaLake形式のテーブルにより、トランザクションのACIDが確保されている
データインジェストの自動化
DataFactory
・データフロー(Gen2):PowerQueryを使って設定
・データパイプライン:データフローやSparkを組み合わせた複雑なデータ変換プロセスを実装できる
Lakehouseの作成
①DataEngineeringワークロードから、Lakehouseを新規作成する
②レイクハウスが作成され、2個の項目が紐づく
・セマンティックモデル(既定)
・SQL分析エンドポイント
③レイクハウスの編集モードは2種
・レイクハウス:フォルダ形式
・SQL分析エンドポイント:SQL形式


ショートカット
・データを外部ストレージ(他のクラウドサービスプロバイダなど)に格納したまま、レイクハウスに統合できる技術
・レイクハウス内のフォルダとして扱えるようになる
・外部ストレージに対するアクセス許可と資格情報は、OneLakeで管理される
・ショートカットが使えない(使えるデータソースコネクタがない)場合は、レイクハウスに直接データを取り込むことになる
直接データ取り込み
・ローカルファイルのアップロード
・データフロー(Gen2):PowerQueryOnlineを使う
・データパイプライン
・ノートブック
レイクハウスに対するアクセス許可
・ワークスペース全体に対してアクセス権を定義できるが、レイクハウス単体に対してもアクセス権を定義できる
・さらに、SQL分析エンドポイント経由でFabric外からアクセスさせることも可能
・ユーザがSSMS(SQL Server Management Studio)などで分析することもできる
レイクハウスに対する検索と変換
ApacheSpark
・ノートブック:対話型コーディングUI
・Sparkジョブ定義:スクリプトでスケジュールを記述
SQL分析エンドポイント
・Transact-SQLを実行可能
データフロー(Gen2)
・取り込みだけでなく変換も可能
データパイプライン
・Sparkジョブやデータフローを組み合わせられる
レイクハウス上のデータを分析・視覚化
データは「セマンティックモデル」と呼ばれるリレーショナルモデルで格納されている
PowerBIのデータソースとしてセマンティックモデルを使用できる
演習 - Microsoft Fabric Lakehouse でデータを作成して取り込む
まとめ
3. Spark
ビッグデータ処理に使われる分散処理コンピューティングリソース
レイクハウスからデータを取り込み、処理して、分析するために使う
Azureにおいて、Azure HDInsight、Azure Databricks、Azure Synapse Analytics、Microsoft Fabric など、複数のプラットフォーム実装で利用できる
Sparkの設定
ワークスペースの設定→データエンジニアリング/サイエンス→Sparkの設定
Spark コードを実行する
実行する方法
・ノートブックを使う:対話的に実行する
・Sparkジョブを使う:Pythonスクリプトをアップロードする


Spark データフレーム内のデータを操作する
Sparkで使われるデータ構造
・耐障害性分散データセット(RDD)
・データフレーム:PythonのPandasデータフレームに似ている
Spark SQLを使用してデータを操作する
Sparkライブラリでは、データアナリストがPythonではなくSQLでもデータ操作できるように、Spark SQL APIが用意されている
Sparkノートブックでデータを視覚化する
ノートブックでは、クエリ実行結果をグラフとして可視化する機能がある
MatplotlibやSeabornなどのライブラリを使って独自の可視化を作成することも可能
演習 - Apache Spark を使用してデータを分析する
まとめ
Hadoop->HDInsight vs. Spark->Databricks
Apache Hadoop と Apache Spark は、分析用の大量のデータを管理および処理するために使用できるオープンソースフレームワークです。組織は、ビジネスインテリジェンスに役立つリアルタイムのiインサイトを取得するために、データを大規模かつ迅速に処理する必要があります。
・Apache Hadoop を使用すると、複数のコンピューターをクラスター化して、大量のデータセットをより迅速に並行して分析できます。
・Apache Spark は、インメモリキャッシュと最適化されたクエリ実行を使用して、あらゆるサイズのデータに対する高速な分析クエリを実現します。
Spark はデータ処理に人工知能と機械学習 (AI/ML) を使用するため、Spark は Hadoop よりも高度なテクノロジーです。しかし、多くの企業がデータ分析の目標を達成するために Spark と Hadoop を併用しています。
Apache Hadoop
テラバイト(TB)の1,000倍のペタバイトレベルのデータを複数のストレージに保存し、複数のコンピュータに分散させて並行処理を行い、ビッグデータ処理の基盤を構築します。言語はJavaが使われ、処理を記述するだけでデータの分配や結果の統合などを自動処理することが可能です。
Hadoop Distributed File System (HDFS)という独自の分散ファイルシステムを利用することが特徴です。このファイルシステムでは、データをブロック単位に分割して複数のノードに保存し、データが破損しても復元可能な信頼性を備えています。
HadoopのPaaS
・AWS:Amazon EMR
・Azure:Azure HDInsight
・GCP: Google Cloud Dataproc
・HDInsight:Hadoopがベース
・Databricks:Sparkがベース
4. DeltaLakeテーブル
Fabricレイクハウスのテーブルは、DeltaLakeストレージ形式(Sparkでよく使われる)になっている
RDBと同様にSQLベースで操作できるため、DeltaLakeAPIを直接操作することは不要
Delta Lake メタストア アーキテクチャについての理解と、より特殊ないくつかの Delta テーブル操作に慣れ親しんでおくとよい
DeltaLakeとは
Delta Lake は、Spark ベースのデータ レイク処理にリレーショナル データベースのセマンティクスを追加する、オープンソースのストレージ レイヤーです。
Microsoft Fabric Lakehouse のテーブルは Delta テーブルです。これは、レイクハウスのユーザー インターフェイスのテーブルに、三角形の Delta (▴) アイコンで示されます。
Deltaテーブルの構成要素
・Parquet形式のデータファイル
・JSON形式のトランザクションファイル(_delta_Log)


DeltaLakeを使うことにより以下がサポートされる
・RDBと同様のCRUD操作
・トランザクション(テーブル操作処理)のACID特性
・データのバージョン管理と復元(タイムトラベル)
・静的データだけでなくストリーミングデータも格納可能
Deltaテーブルの作成方法
①既存ファイルから差分テーブル(データファイルとテーブルスキーマ定義の両方)を作成する
・マネージドテーブル:テーブルを削除すると、元ファイルも削除される
・外部テーブル:テーブルを削除しても、元ファイルは削除されない
②テーブルスキーマ定義のみを新規作成する(データファイルは保存しない)
・DeltaTableBuilder APIを使う
・SparkSQLを使う
③テーブルスキーマ定義を作成せずにデータファイルのみ保存する(上書き用)
Deltaテーブルの操作方法
①SparkSQLライブラリを使う:他言語(PySparkやScala)にSQLステートメントを埋め込む
②DeltaLakeAPIを使用する
ストリーミングデータを使用する(Spark Structured Streaming)
多くのデータ分析シナリオでは、準リアルタイムで処理する必要がある "ストリーミング" データを使用します。 たとえば、モノのインターネット (IoT) デバイスによって生成された読み取り値をキャプチャし、それらが発生したときにテーブルに格納する必要がある場合があります。
一般的なストリーム処理ソリューションでは、"ソース" から絶えずデータのストリームを読み取り、必要に応じてそれを処理して特定のフィールドを選択したり、値を集計およびグループ化したり、データを操作したり、または結果を "シンク" に書き込んだりします。
Deltaテーブルは以下のいずれかに使える
・ストリーミングソース(入力元):Deltaテーブルからデータを読み込む
・ストリーミングシンク(出力先、宛先):Deltaテーブルにデータを書き込む
たとえば、IoT デバイスからリアルタイム データのストリームをキャプチャし、ストリームをシンクとしてのデルタ テーブルに直接書き込めば、テーブルにクエリを実行して最新のストリーミング データを表示できます。
または、デルタをストリーミング ソースとして読み取ると、テーブルに追加された新しいデータを絶えずレポートできます。
デルタ テーブルをストリーミング ソースとして使用する
インターネット販売注文の詳細を格納します。 新しいデータが追加されると、デルタ テーブル フォルダーからデータを読み取るストリームが作成されます。
デルタ テーブルをストリーミング シンクとして使用する
フォルダー内の JSON ファイルからデータのストリームが読み取られます。 各ファイルの JSON データには、IoT デバイスの状態が {"device":"Dev1","status":"ok"} という形式で含まれます。フォルダーにファイルが追加されるたびに、ストリームに新しいデータが追加されます。 入力ストリームは境界のないデータフレームであり、デルタ テーブルのフォルダーの場所にデルタ形式で書き込まれます。
演習 - Apache Spark でデルタ テーブルを使用する
5. データパイプライン
FabricのDataFactoryワークロードでは、パイプラインを作成できる
パイプラインの役割は、複数のデータ関連プロセスの調整と管理を指し、それらが確実に連携して望ましい結果を得られるようにすること(データオーケストレーション)
データのインポート(import) vs. データのインジェスト(ingest)
・インポート:必要に応じて、一度に大量に(一括で)、手作業で
・インジェスト:継続的に、一定量ずつ、自動化された処理で(パイプラインなど)
パイプラインとは
・ETLプロセスを自動化する
・運用データストア(レイクハウスなど)からの抽出
・変換
・分析データストアへの読み込み
・データインジェスト(読み込み)と変換のタスクを調整する
・パイプラインの実行方法
・オンデマンド実行
・スケジューラ実行
パイプラインキャンバス
ローコードツール


アクティビティ:実行可能なタスク、実行結果(成功/失敗)を出力する
・データ変換アクティビティ
・データのコピー:データソースからコピー
・データフロー:データを変換(※「6. データフロー(Gen2)」で解説)
・メタデータの取得
・ノートブック:Sparkノートブックを実行
・ストアドプロシージャ:SQLクエリを実行
・データの削除
・制御フローアクティビティ
・ループ
・条件付き分岐
パラメータを使用すると、パイプラインの柔軟性が向上する
パイプラインテンプレートの利用

パイプラインの監視


演習 - パイプラインを使用してデータを取り込む
まとめ
6. データフロー(Gen2)
PowerQueryOnlineを使ってデータのインジェストと変換をローコードで作成する
データフローを作成することで、変換処理を再利用可能にする
データフロー Gen2 を使用すると、さまざまなソースからデータを抽出し、幅広い変換操作を使用して変換し、変換先に読み込むことができます。 Power Query Online を使用して、これらのタスクをビジュアル インターフェイスで実行することもできます。
データフローの使い方
ETLプロセス(抽出→変換→読み込み)に使う
①データフローを作成して、データパイプライン上に追加する
②レイクハウスなどにデータを読み込む
ELTプロセス(抽出→読み込み→変換)に使う
①データパイプラインを使ってあらかじめレイクハウスにデータを読み込む
②レイクハウスにデータフローを接続し、変換を行う
データフローの利点と制限事項
利点
・標準の日付ディメンション テーブルなど、一貫性のあるデータを使用してデータを拡張します。
・セルフサービス ユーザーがデータ ウェアハウスのサブセットに個別にアクセスできるようにします。
・データフローを使用してパフォーマンスを最適化します。データを 1 回抽出すると再利用できるため、低速なソースのデータ更新時間が短縮されます。
・データフローを大規模なアナリスト グループにのみ公開することで、データ ソースの複雑さを簡素化します。
・ユーザーがデータをクリーンおよび変換してから宛先に読み込むようにすることで、データの一貫性と品質を確保します。
・さまざまなソースからデータを取り込むローコード インターフェイスを提供することで、データ統合を簡素化します。
制限事項
・データ ウェアハウスを置き換えることはできません。
・行レベルのセキュリティがサポートされません。
・ファブリック容量ワークスペースが必要です。
データフローの作り方
DataFactoryワークロードのPowerQueryOnlineで作成できる
ダイヤグラムビューで視覚的に確認できる
M言語でスクリプトを記載することもできる

データフローをデータパイプラインに組み込む

演習 - Microsoft Fabric でデータフロー Gen2 を作成して使用する
まとめ
7. ノートブック
・データフロー:小規模なセマンティック モデルや単純な変換に最適
・ノートブック:大規模なセマンティック モデルや複雑な変換に最適
ノートブックによるデータインジェストの利点
・処理を自動化できる
・処理が高速:データフローはUIで処理を組めるが、大規模で複雑になると速度が落ちる
・複雑な変換ができる:データパイプラインだけではコピーぐらいしかできない
Fabricノートブックで使用できる言語
・Python(PySpark):既定
・HTML
・Scala(SparkScala)
・SparkSQL
・R(SparkR)

レイクハウスへのインジェスト処理の流れ
・外部ソースに接続する
・代替認証を構成する
・レイクハウスに書き込む
・Sparkを使うためには以下のいずれかの形式で格納する
・Parquetファイル
・Deltaテーブル
・書き込みを最適化してインジェスト速度を改善する
レイクハウスにデータが取り込まれた後の処理
・生データ(未加工データ)は、Medallionアーキテクチャにおけるブロンズレイヤに相当する
・データのユーザによりどこまで前処理が必要かは異なる
・データサイエンティスト:未加工のままを好む
・データアナリスト(PowerBIユーザなど):データクレンジングやモデリングが済んだ段階を好む
演習 - Spark と Microsoft Fabric ノートブックを使用してデータを取り込む
Azure Blob Storage
↓Fabricノートブック
レイクハウス
まとめ
変換とモデリングのステップに進む前に、変換する場所と、ユーザーがデータを操作する方法を検討してください。
8. Medallionアーキテクチャ
メダリオンアーキテクチャ(マルチホップアーキテクチャ)とは
・レイクハウスを使ったデータ分析のデファクトスタンダードな考え方
・レイクハウス上のデータをうまく整理するために推奨される設計パターン
・データガバナンスにおけるデータ活用面でのベストプラクティス
Medallionアーキテクチャの3層
・ブロンズ:生、未加工
・シルバー:クレンジング済み、検証済み
・ゴールド:キュレーション済み(付加価値を付けた)、業務に使いやすく加工された
※各レイヤ間の変換は、データ(データオーケストレーションのためのツール)を使うとよい




ハイブリッド型で運用するに当たって、特に重要になるのがデータガバナンスです。データを統合して、SSOT(Single Source Of Truth、信頼すべき唯一の情報源)を実現すること自体もデータガバナンスの一部ですが、それだけでは十分ではありません。データは使われてこそ価値を生むので、ユーザーが必要とするデータをただちに探し出せなければ意味がないのです。
意味のあるデータガバナンスを実現するためには、データガバナンスに最適なデータ管理手法「メダリオン・アーキテクチャ」を知っておくとよいでしょう。
メダリオン・アーキテクチャーとは?
メダリオン・アーキテクチャーとは、従来生データ(raw data)と加工済みデータの2層で捉えていたデータ管理を、Bronze・Silver・Goldの3層で捉え直して管理する手法です。Bronzeは生データ、Silverはクレンジング済みのデータ、Goldはそのまま分析に使えるデータマート的なデータに該当します。
ユーザーは、普段はGoldを使用してデータから知見を得ますが、新たな知見を得たい場合にはSilverに遡ってそこからGoldを作成することができます。それでも不足の場合には、IT部門にリクエストして、BronzeからSilverを作成してもらいます。
データを鮮明度に従って3階層に分けて、役割や責任を明確に分担することでデータガバナンスに好影響を与えることができるわけです。
Fabricにおけるメダリオンアーキテクチャの実装方法
ブロンズへのデータの取り込み
ブロンズ レイヤーにどのようにデータを取り込むかを決定します。 これは、パイプライン、データフロー、またはノートブックを使用して行うことができます。
データの変換とシルバーへの読み込み
シルバー レイヤー内でどのようにデータを変換するかを決定します。 これは、データフロー、またはノートブックを使用して行うことができます。 シルバー レベルでの変換は、データ モデリングではなく、データの品質と一貫性に重点を置いたものとする必要があります。
ゴールド レイヤーの生成
複数のゴールド レイヤーをどのように生成するか、それに何を含めるか、およびそれをどのように使用するかを決定します。
・ゴールド レイヤーは、ディメンション モデルを使用してレポート用にデータをモデル化する場所です。 ここでは、リレーションシップを確立し、メジャーを定義し、効果的なレポートに不可欠なその他のすべての要素を組み込みます。
・異なる対象者やドメイン用に複数のゴールド レイヤーを持つことができます。 たとえば、財務チーム用に 1 つのゴールド レイヤーを持ち、営業チーム用には別のゴールド レイヤーを持つ場合があります。 また、機械学習用に最適化されたデータ サイエンティスト用のゴールド レイヤーを持つ場合もあります。
・ニーズによっては、データ ウェアハウスをゴールド レイヤーとして使用する場合もあります。 詳細については、「Microsoft Fabric でのデータ ウェアハウスの利用の開始」を参照してください。
・Fabric では、データフローまたはノートブックを使用してデータを変換してから、それをレイクハウスのゴールド Delta テーブルへと読み込むことができます。 その後、SQL 分析エンドポイントを使用してその Delta テーブルに接続し、SQL を使用してレポート用にデータをモデル化できます。 または、Power BI を使用してゴールド レイヤーの SQL 分析エンドポイントに接続し、データをレポート用にモデル化することもできます。
ダウンストリーム使用の有効化
データのダウンストリーム使用をどのように有効にするかを決定します。 これは、ワークスペースまたはアイテムのアクセス許可を使用するか、SQL 分析エンドポイントに接続することで行うことができます。
レイクハウス上のデータに対する探索
探索方法(読み取り専用)
・T-SQL
・SQL分析エンドポイント
・PowerBIセマンティックモデルのDirectLakeモード(主にゴールドレイヤに対して)
※レイクハウス内のデータを変更するには、データフロー、ノートブック、またはパイプラインを使用できます。


さまざまなニーズに合わせて medallion レイヤーを調整する
medallion レイヤーをさまざまなニーズに合わせて調整することで、特定のユース ケース用にデータ処理とアクセスを最適化できます。 これらのレイヤーをカスタマイズすることにより、各レイヤーの構造と構成をさまざまなユーザー グループの要件に合わせることができるようになり、多様な利害関係者に対するパフォーマンス、使いやすさ、データ関連性が向上します。
多様な対象ユーザーやドメインに合わせて調整された複数のゴールド レイヤーを作成することで、柔軟性に優れた medallion アーキテクチャを実現できます。 財務、営業、データ サイエンス – それぞれが最適化されたゴールド レイヤーを活用して、特定の分析要件に対応できます。
一部のアプリケーション、サードパーティ製ツール、システムでは、特定のデータ形式が必要になります。 medallion アーキテクチャを利用して、クレンジングされ、適切に書式設定されたデータを生成できます。
レイクハウスの管理
レイクハウスのセキュリティ
2種類のアクセス制御
・ワークスペースのアクセス許可
・アイテム レベルのアクセス許可
セキュリティとアクセスに関する考慮事項
各レイヤーでアクセスを必要とするユーザーを定義し、承認された担当者のみが機密データを操作できるようにします。
ゴールド レイヤー アクセス制御
ゴールド レイヤーへのアクセスを読み取り専用の目的に制限し、最小限のアクセス許可の重要性を強調します。
シルバー レイヤーの使用
柔軟性とセキュリティのバランスを取りつつ、シルバー レイヤー上に構築することをユーザーに許可するかどうかを決定します。
ブロンズ レイヤー アクセス制御
ブロンズ レイヤーへのアクセスを読み取り専用の目的に制限し、最小限のアクセス許可の重要性を強調します。
レイクハウスのCI/CD(継続的なインテグレーション/デプロイ)
実装すべき機能の例
・データ品質チェック
・バージョン管理:
・自動デプロイ
・監視
・スケーラビリティ
・DR
・コンプライアンス
演習 - medallion アーキテクチャを使用して Fabric レイクハウスを整理する
レイクハウスにメダリオンアーキテクチャを構築する
①ワークスペースの作成
②レイクハウスの作成
③CSVファイルをアップロードしてブロンズレイヤを作成
④ノートブック(シルバーレイヤ作成用)により変換してシルバーレイヤを作成
⑤SQLエンドポイントを使ってシルバーレイヤのデータを探索
⑥ノートブック(ゴールドレイヤ作成用)によりスタースキーマ化してゴールドレイヤを作成
⑦ゴールドレイヤからセマンティックモデルを作成
まとめ
レイクハウスのさまざまなレイヤーを別々のワークスペースに格納すると、セキュリティが強化され、コスト効率が最適化されます。
9. DWHの概要
・分析用途で使うデータストア(一般的には、クエリ上での結合数を減らすために非正規化されている)
・RDB製品(SQLをサポートしている)で実装する
DWHの構築プロセス
・データ インジェスト - ソース システムからデータ ウェアハウスへデータを移動します。
・データ ストレージ - 分析用に最適化された形式でデータを格納します。
・データ処理 - 分析ツールで使用できる形式にデータを変換します。
・データ分析と配信 - データを分析して分析情報を取得し、それらの分析情報をビジネスに提供します。
データ エンジニアは、レイクハウスのデータの上にリレーショナル レイヤーを構築します。
そこで、アナリストは T-SQL と Power BI を使用してデータを探索できます。
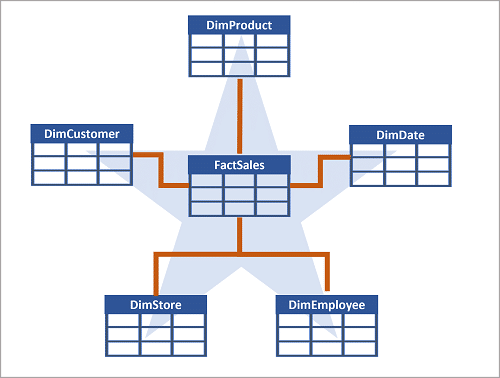
モデリング
・ファクトテーブル(トランザクションテーブル)
・ディメンションテーブル(マスタテーブル)
ディメンション テーブルには、属性列に加えて、テーブル内の各行を一意に識別する一意のキー列が含まれています。 実際、ディメンション テーブルには通常、次の 2 つのキー列が含まれています。
データウェアハウス内の代理キーと代替キーは異なる目的に対応するため、両方が必要です。
代理キー(Alternate Key)
ディメンション テーブルの各行の一意の識別子です。 多くの場合、新しい行がテーブルに挿入されるときに、データベース管理システムによって自動的に生成される整数値です。
代理キーはデータウェアハウスに固有であり、データの一貫性と精度を維持するのに役立ちます。
代替キー(Surrogate Key)
多くの場合、トランザクション ソース システム内のエンティティの特定のインスタンスを識別するナチュラル キーまたビジネス キーです (製品コードや顧客 ID など)。
代替キーはソースシステムに固有であり、データ ウェアハウスとソース システムの間の追跡可能性を維持するのに役立ちます。
特殊な種類のディメンション テーブル
特殊な種類のディメンションでは、追加のコンテキストが提供され、より包括的なデータ分析が可能になります。
"時間ディメンション" は、イベントが発生した期間に関する情報を提供します。 データ アナリストは、この表を使用して複数の時間間隔でデータを集計できます。 たとえば、時間ディメンションには、販売注文が行われた年、四半期、月、日の列が含まれる場合があります。
"スロー チェンジ ディメンション" は、時間の経過に伴うディメンション属性の変更 (顧客の住所や製品の価格の変更など) を追跡するディメンション テーブルです。 時間の経過に伴うデータの変更をユーザーが分析して理解できるため、データ ウェアハウスではこのテーブルが重要です。 スロー チェンジ ディメンションにより、データは最新かつ正確に保たれ、これはビジネス上の適切な意思決定を行う上で不可欠です。
スタースキーマ/スノーフレークスキーマ
基本はスタースキーマで、
・正規化を維持したい(例:DimSupplier、DimCategory)
・1つのマスタを複数マスタから参照したい(例:DimGeography)
場合は、スノーフレークスキーマを使う

FabricにおけるDWHの作成方法
Fabricでは、「レイクハウス」の上にリレーショナルレイヤを構築することで、「ウェアハウス」を作成できる
「ウェアハウス」が作成できたら、SQLクライアント(SSMSなど)を接続して、T-SQLでテーブルを作成できる
・データパイプライン
・データフロー
・データベース間クエリ
・COPY INTOコマンド

DWHテーブルへのデータ読み込み
レイクハウスからウェアハウステーブルにデータを読み込む時には、ステージングテーブルと呼ばれる一時テーブルを介して変換することが一般的
データ読み込みは、一定間隔で実行されるバッチプロセスで実行されることが一般的
①読み込み対象の新しいデータをデータ レイクに取り込み、必要に応じて、読み込み前のクレンジングまたは変換を適用します。
②データをリレーショナル データ ウェアハウス内のファイルからステージング テーブルに読み込みます。
③ステージング テーブルのディメンション データからディメンション テーブルを読み込み、必要に応じて、既存の行を更新するか新しい行を挿入して、代理キー値を生成します。
④ステージング テーブルのファクト データからファクト テーブルを読み込み、関連するディメンションの適切な代理キーを参照します。
⑤インデックスとテーブル分散統計を更新して、読み込み後の最適化を実行します。
DHWに対するクエリ発行
2つの方法
・SQLクエリエディタ
・ビジュアルクエリエディタ:Power Query オンライン ダイアグラム ビューと同じような感覚で使える


テーブル間リレーションシップの定義




DWHのセキュリティ
・ウェアハウスとそのデータへのアクセスを制御するロールベースのアクセス制御 (RBAC)。
・ウェアハウスとクライアント アプリケーション間の通信をセキュリティで保護するための SSL 暗号化。
・転送中および保存中のデータを保護するための Azure Storage Service Encryption。
・ウェアハウス アクティビティを監視し、データへのアクセスを監査する Azure Monitor と Azure Log Analytics。
・ユーザー アカウントにセキュリティ レイヤーをさらに追加する多要素認証 (MFA)。
・ユーザー ID とウェアハウスへのアクセスを管理するための Microsoft Entra ID の統合。
アクセス制御の単位
・ワークスペース
・アイテム:アイテムのアクセス許可は、ウェアハウス内のデータへのアクセスに関連し、テーブル内の特定の列には関係しません。
クエリの監視
動的管理ビュー(DMV)にSQLで問い合わせることにより、接続、セッション、要求の状態を監視して、ライブ SQL クエリ ライフサイクルの分析情報を表示できます。 DMV を使用すると、アクティブなクエリの数などの詳細を取得し、長期間実行されていて、終了する必要があるクエリを特定できます。
現在、Fabric で使用できる DMV は 3 つあります。
・sys.dm_exec_connections:ウェアハウスとエンジンの間に確立された各コネクションに関する情報が返されます。
・sys.dm_exec_sessions:項目とエンジンの間で認証された各セッションに関する情報が返されます。
・sys.dm_exec_requests:セッション内のアクティブな各リクエストに関する情報が返されます。
演習 - DWHでデータを分析する
Microsoft Fabric では、DWHが大規模な分析用のリレーショナル データベースを提供します。
レイクハウスで定義されたテーブルのデフォルトのSQL エンドポイント(読み取り専用)とは異なり、DWHは完全な SQL セマンティクス(データを挿入、更新、削除できる)を提供します。
まとめ
略
10. データウェアハウスへのデータ読み込み
Microsoft Fabric のデータ ウェアハウスは、データの管理と分析を容易にする豊富な機能セットを提供する Synapse Analytics によって強化されています。 高度なクエリ処理機能が含まれており、エンタープライズ データ ウェアハウスなどの完全なトランザクション T-SQL 機能をサポートします。
Microsoft Fabric では、ウェアハウスにデータを読み込むさまざまな方法を選択できます。 高品質な変換または処理されたデータが 1 つのリポジトリに統合されることを保証するこのステップは、基盤となるものです。
また、データ読み込みの効率は、分析の適時性と正確性に直接影響するため、リアルタイムの意思決定プロセスに不可欠なものです。 データ ウェアハウス プロジェクトを成功させるには、堅牢なデータ読み込み戦略の設計と実装に時間とリソースを費やすことが不可欠です。
インジェスト(取り込み) vs. ロード(読み込み)
・インジェスト:各データソースから中央リポジトリに生データを移動すること
・ロード:分析やレポートのために使う最終的なストレージに読み込むこと
ステージングオブジェクト
テーブル、ストアド プロシージャ、関数など、読み込み操作に関係する補助オブジェクトを作成して使用することが必要な場合があります。 これらの補助オブジェクトは、一般に、ステージングと呼ばれます。 ステージング オブジェクトは、ストレージと変換のための一時的な領域として機能します。 それらは、データ ウェアハウスとリソースを共有したり、独自のストレージ領域に存在したりできます。
ステージングは抽象化レイヤーとして機能し、データ ウェアハウス内の最終的なテーブルへの読み込み操作を簡単で容易にします。
また、ステージング領域は、負荷のかかる操作がデータ ウェアハウスのパフォーマンスに及ぼす影響を最小限に抑えるのに役立つバッファーも提供します。 これは、データ読み込みプロセスの間もデータ ウェアハウスの動作と応答が維持される必要のある環境において重要なことです。
データ読み込み方式
・完全な読み込み:所要時間は長いが、実装は簡単
・増分読み込み:所要時間は短いが、実装が複雑
SCD(Slowly Changes Dimensions))
緩やかに変化するディメンションは時間と共に変化しますが、その変化は遅く、予測できません。 たとえば、小売ビジネスの顧客の住所などです。 顧客が引っ越すと、住所が変わります。 古い住所を新しい住所で上書きすると、履歴は失われます。 しかし、過去の売上データを分析したい場合は、各売上の時点で顧客が住んでいた場所を知ることが必要になる場合があります。 そのようなときこそ SCD の出番です。
データ ウェアハウスの緩やかに変化するディメンションにはいくつかの種類があり、最もよく使われるのはタイプ 1 とタイプ 2 です。
・タイプ 0 SCD:ディメンション属性は変更されません。
・タイプ 1 SCD:既存のデータを上書きし、履歴を保持しません。
・タイプ 2 SCD:変更があると新しいレコードを追加し、特定の自然キーについての完全な履歴を保持します。
・タイプ 3 SCD:履歴は新しい列として追加されます。
・タイプ 4 SCD:新しいディメンションが追加されます。
・タイプ 5 SCD:大きなディメンションの特定の属性が時間と共に変化するものの、ディメンションのサイズが大きいためタイプ 2 を使用できない場合。
・タイプ 6 SCD:タイプ 2 とタイプ 3 の組み合わせ。
タイプ 2 SCD では、同じ要素の新しいバージョンがデータ ウェアハウスに取り込まれると、古いバージョンは期限切れと見なされて、新しいバージョンがアクティブになります。

ウェアハウスへのデータ読み込み(データパイプライン)




ウェアハウスへのデータ読み込み(T-SQL)
COPYステートメント
REJECTED_ROW_LOCATION
他のウェアハウスやレイクハウスなど、ワークスペース内のさまざまなデータ資産からデータを読み込むことができます。
データ資産を参照するには、3 部構成の名前付けを確実に使用して、これらのワークスペース資産上のテーブルからデータを結合します。 それから、CREATE TABLE AS SELECT (CTAS) および INSERT...SELECT を使用して、そのデータをウェアハウス内に読み込むことができます。

ウェアハウスへのデータ読み込み(データフローGen2)
データフローを使って、レイクハウスまたはウェアハウスにデータを取り込んだり、Power BI レポート用のデータセットを定義したりできます。
[データ同期先の追加] 機能を使うと、ETL ロジックと同期先ストレージを分離できます。 この分離により、コードがすっきりして保守しやすくなり、ETL プロセスとストレージ構成を相互に影響を与えることなく簡単に変更できるようになります。


データをDWHに読み込む場合にFabricで使用できるインジェスト方法
①COPY (Transact-SQL) ステートメント
②データ パイプライン
③データフロー
④クロスウェアハウス
演習: Microsoft Fabric のウェアハウスにデータを読み込む
Microsoft Fabric では、DWHが大規模な分析用のリレーショナル データベースを提供します。
レイクハウスで定義されたテーブルのデフォルトのSQL エンドポイント(読み取り専用)とは異なり、DWHは完全な SQL セマンティクス(データを挿入、更新、削除できる)を提供します。
①ワークスペースを作成する
②レイクハウス(読み込み元)を作成し、CSVファイルをアップロードする
③CSVファイルをテーブルにロードする
④ウェアハウス(読み込み先)を作成する
⑤ウェアハウスにファクト/ディメンション/ビューを作成する
⑥レイクハウスのSQLエンドポイント(読み取り専用)にアクセスし、T-SQLストアドプロシージャによってウェアハウスにロードする
まとめ
データを読み込むための万能のソリューションはありません。 最適なアプローチは、ビジネス要件の詳細、および解決しようと試みている課題に応じて異なります。
データ ウェアハウス内にデータを読み込む場合は、いくつかの考慮事項に留意する必要があります。
・負荷ボリュームと頻度:データ ボリュームと読み込み頻度を評価して、パフォーマンスを最適化します。
・ガバナンス:OneLake 内に格納されるすべてのデータは、既定で管理されます。
・データ マッピング:ソースからステージング、ウェアハウスへのマッピングを管理します。
・依存関係:ディメンションを読み込むためのデータ モデル内の依存関係について理解します。
・スクリプトの設計:列名、フィルター規則、値のマッピング、データベース インデックス作成を考慮して、効率的なインポート スクリプトを設計します
11. PowerBIパフォーマンス最適化
Power BI レポートを作成したところ、レポートがゆっくり実行されます。 問題の原因はどのような方法で特定しますか。 レポートが遅い原因としては、"ソース" の問題、"データ モデル" の構造、レポート ページの "ビジュアル"、"環境" などが考えられます。
このモジュールにおいてパフォーマンスを最適化することは、実行効率が上がるよう、"データ モデル" の変更を意味します。 このモジュールで説明するツールは、トラブルシューティングとデータ モデルの改善に役立ち、最終的にはユーザー エクスペリエンスが改善されます。
理想的には、開発ライフサイクルの各段階 (ソリューションの開発、試験、運用、最適化) を進む際にパフォーマンスを評価するべきです。
パフォーマンスアナライザ
PowerBのアーキテクチャレベル
①データソース
②データモデル
③視覚化:ダッシュボード、PowerBIレポート、PowerBIページ分割レポート
④環境:容量、ゲートウェイ(オンプレミス接続用)、ネットワーク、など
パフォーマンスアナライザは、以下を最適化するのに役立つ
②データモデル
③視覚化:レポートビジュアル
パフォーマンスアナライザの機能
・レポートキャンバス
・データシェイプエンジン(DSE)
・データモデルエンジン(AS)
パフォーマンスアナライザの使い方
⓪キャッシュをクリアする(メモリにキャッシュが残っていると処理が省略されるため)
①記録を開始
②レポート上でアクションを実行する
③アクション実行時からレンダリング完了時までのログが記録される


ログに経過時間が書き込まれるタスク例
・DAXクエリ:ビジュアルから送信されてから、結果が返ってくるまで
・パラメータの評価:ビジュアル内のフィールドパラメータを評価完了するまで
・ビジュアルのレンダリング:Web画像の取得にかかる時間など
・クエリの準備、他ビジュアルの処理完了までの待機、バックグラウンド処理の完了待ち、など
DAX Studioによる深掘り分析
パフォーマンスアナライザからの出力データをDAXStudioにインポートし、分析を深掘りすることができる
DAX Studio を使用して、パフォーマンス アナライザーからクエリをコピーすることで、クエリをより詳細に調べることができます。 DAX Studio でクエリを分析した後、ご自分の知識と経験から、パフォーマンスに問題がある箇所を特定することができます。
期間が長い DAX クエリの場合、メジャーが十分に作成されていないか、データ モデルで問題が発生している可能性があります。 問題は、モデル内のリレーションシップ、列、またはメタデータによって発生する可能性があります。または、[自動の日付/時刻] オプションの状態であることも考えられます。
[エクスポート] ボタンを選択してパフォーマンス アナライザーの結果を保存することもできます。これにより、結果を含む .json ファイルが作成されます。 .json ファイル内の各イベントには、タイムスタンプ、相関関係情報、および操作に関するその他のメタデータが含まれています。
VertiPaqエンジン
・PowerBI内部では、VertiPaqエンジンが、データソースへのアクセスを高速化している
・VertiPaqエンジンは、データソースのコンテンツを読み取り、内部的な列データ構造(Verti列データ構造)に変換し、各列をエンコーディングして圧縮する。さらに、列ごとにディクショナリとインデックスを作成する。最後に、リレーションシップと計算用にデータ構造が作成され、計算列の圧縮が行われる。
DAXクエリは、VertiPaqの2個のエンジンにより処理されている
・数式エンジン(FE):要求の処理、ストレージエンジンへのデータの要求、必要な計算の実行
・ストレージエンジン(FE):数式エンジンから要求されたデータの取得
DAX Studioとは
・オープンソースツール
・以下の用途に使える
・データモデルの内容を確認する
・DAXクエリの記述を最適化する

③数式エンジン
④ストレージエンジン
DAX Studio を使用してクエリを最適化する方法を理解するためのシナリオについて説明しましょう。
6 つのメジャーを視覚化するマトリックスが含まれるレポートがあります。 CEO から「このレポートは、ビジュアルのレンダリングに時間がかかるため、使い物にならない」と伝えられました。
①まず、Power BI Desktop のパフォーマンス アナライザーを使用して調査を開始し、レンダリングに時間がかかることを確かめました。
②次に、問題の原因について詳細情報を取得するために、クエリをコピーして DAX Studio で確認します。 DAX Studio で、キャッシュをクリア し (1)、サーバー タイミングをオンにして (2)、クエリを実行します (3)。
統計情報には、左上から右下に向かって、クエリの実行にかかった時間 (ミリ秒) とストレージ エンジン (SE) の CPU が要した時間が表示されます。 この場合、数式エンジン (FE) で 73.5% の時間がかかり、SE で残りの 26.5% の時間がかかりました。 34 個の SE クエリと 21 回のキャッシュ ヒットがありました。

クエリ実行にかかった総時間数:98ms=72ms(FEが要した時間)+26ms(SEが要した時間)
SEは34回クエリを発行し、うち21回はキャッシュヒットした

クエリ実行にかかった総時間数:35ms
VertiPaq Analyzerによるメモリ使用量の監視
DAX Studio で VertiPaq Analyzer を使用すると、カーディナリティが高い列 (自動の日付/時刻や浮動小数点 10 進データ型など) を簡単に特定して取り除く、何にも使用されない列を特定して削除することができます。

DAX Studio でメトリックを表示することで、問題をすぐに見つけて修正できます。 この場合、問題は、カーディナリティが高い列であることがわかります。 次に、Power BI に戻ってこの問題を修正し、メトリックを更新すると、変更がモデルに与える影響をすぐに確認できます。
たとえば、次の図のモデルには、データベース メモリの 99.6% を消費するテーブルが含まれていることに気付きます。 このテーブルをドリルインすると、終了日と開始日の 2 つの列で最も多くのメモリを使っていることがわかります。
Power BI Desktop に戻ってこれら 2 つの列を確認すると、それらが [日付/時刻] 列であることがわかります。 [日付/時刻] 列は、日付と時刻の可能なすべての組み合わせのために本質的にカーディナリティが高くなります。


データモデリングにベストプラクティスを活用する
Power BI でデータ モデルを設計およびビルドする際に、データ モデリングのベスト プラクティスを確実に実装するにはどうすれば良いでしょうか。 そのためのツールがあります。 表形式エディターのベスト プラクティス アナライザー (BPA) は、Power BI または Analysis Services モデルの表形式モデルの開発中に使用できます。
表形式エディタ
・オープンソースツール
BPA(ベストプラクティスアナライザ)
・データモデリングに有用なルール集:命名規則なども含む
・ルールは自組織用にカスタマイズして管理可能
・既存のCI/CDプロセスに組み込み、ベストプラクティスに従わない場合にビルドエラーや警告を出すことも可能



演習: ツールを使用して Power BI のパフォーマンスを最適化する
12. PowerBIデプロイパイプライン
デプロイ パイプラインを使用すると、エンドユーザが Power BI コンテンツを使用する前に、コンテンツ作成者が Power BI サービス内でテストできます。
これにより、作成者は生産性を向上し、コンテンツの更新をより迅速に提供し(CI/CD)、手動での作業とミスを減らすことができます。 このツールは、開発、テスト、運用という 3 つのステージからなるパイプラインとして設計されています。
コンテンツライフサイクルにおける3ステージ(開発・テスト・運用)
PowerBIにおけるコンテンツ
・レポート
・ページ分割されたレポート
・ダッシュボード
・セマンティックモデル
・データフロー
開発ステージ – 開発ワークスペースのコンテンツを設計、レビュー、変更します。
・新しいコンテンツについて他の作成者と連携する
・最小限のセマンティック モデルを使用します。 テストとレビューの準備ができたら、コンテンツをテスト ステージにデプロイします。
テストステージ – この運用前ワークスペースでコンテンツが正確であることをテストし、確認します。
・テスト担当者およびレビュー担当者とコンテンツを共有する
・大量のデータがあるテストを読み込んで実行する
・アプリをテストして、エンド ユーザー向けにどのように表示されるかを確認する。 配布の準備ができたら、そのコンテンツを運用ステージにデプロイします。
運用ステージ – このワークスペースのコンテンツはテスト済みで、ユーザーに提供する準備ができています。ユーザーは、これらをアプリで使用したり、運用ワークスペースにアクセスして使用することができます。
・コンテンツの最終バージョンを組織内のビジネス ユーザーと共有する
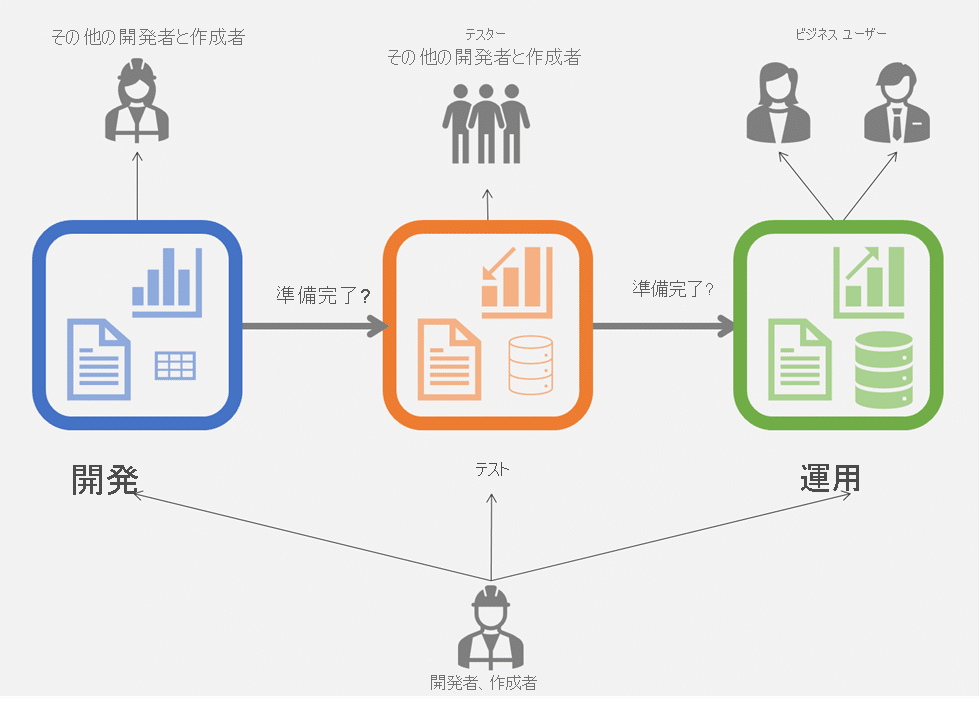
上のグラフィックについては、いくつかの重要な項目があります。
コンテンツ (ワークスペース) は、上記の各ステージで異なる場合があります。 次に例を示します。
・この例では、データ ソースのサイズ (テーブルとデータ アイコン) が、運用に近づくにつれて増えていきます。 ただし、開発ステージとテスト ステージの間で、テストに対応できるようにセマンティック モデルを小さくできる可能性はあります。
・レポート (グラフ アイコン) は各ステージで変更されます。
他の作成者や開発者は、各ステージで個別に作業できます。
パイプラインは、[デプロイ] ボタンが初めてクリックされたときに作成された 3 つのワークスペースから構築されるか、各ステージに異なるワークスペースを割り当てることによって構築されます。
・その結果、3 つのワークスペースはそれぞれ独立したワークスペースとなります。これはスタンドアロンのワークスペースであり、ワークスペースの任意の側面 (アクセス許可、コンテンツなど) から管理できます。
・ソース ステージをターゲット ステージにデプロイすると、選択したソースのコンテンツ (特定のセマンティック モデル、レポート、またはすべての項目) によって、ターゲット ワークスペース (ステージ) 上の同等のコンテンツがオーバーライドされます。
デプロイパイプラインツール
・デプロイパイプラインツールを使うためには、Premium容量ライセンスが必要
・デプロイパイプラインには、ワークスペースを割り当てて使う
・ステージに割り当てたワークスペースのコンテンツは、次のステージに割り当てたワークスペースに「デプロイ(展開)」できる
・デプロイにより、コンテンツ間の接続を維持したままコピーされる
・ステージ上のコンテンツを一度にすべてデプロイすることもできるし、一部のみをデプロイ(選択的デプロイ)することもできる
・ただし、依存関係があるコンテンツの一部のみを選択的デプロイすると、壊れる可能性あり(「関連項目の選択」で確認する)
・一般的には、開発ステージで開発が済んだらテストステージへ、テストステージでテストが済んだら運用ステージへ、デプロイを進めていく





インジケータは2タイプ(差異あり/差異なし)

ステージ間で使用するデータベースやクエリを変更する
デプロイ パイプラインで作業する場合、ステージ間で構成が異なる場合があります。 たとえば、テストと運用のステージでデータベース全体にクエリを実行する一方で、各ステージに異なるデータベースや異なるクエリ パラメーターを設定したり、開発ステージでデータベースのサンプル データのクエリを実行したりできます。
デプロイ ルールを構成すると、パイプライン ステージ間でコンテンツをデプロイするときに、コンテンツの変更を許可できます。 たとえば、運用ステージのデータセットが運用データベースを指すようにしたい場合は、セマンティック モデルのルールを定義できます。 このルールは、適切なセマンティック モデルの下、運用ステージで定義されます。 このルールが定義された場合、テスト環境から運用環境にデプロイされたコンテンツは、デプロイ ルールで定義されている値を継承することになります。これは、このルールが変更されずに有効である限り、常に適用されます。
アクセス権限の分離
たとえば、ワークスペースのアクセス許可を持たない、パイプライン アクセス権を持つユーザーは、パイプラインを表示したり、他のユーザーと共有したりできます。 ただし、このユーザーは、パイプラインまたはワークスペース ページでワークスペースのコンテンツを表示することはできず、配置を実行できません。
パイプライン レベルとワークスペース レベルの両方 (異なるステージ) でアクセス許可を管理すれば、ユーザーごとに異なるアクセス許可で作業を行うことができます。
デプロイ プロセスの管理では、全員が同じアクセス許可を持つとミスが発生しやすくなります。これは、大規模なアプリケーションで複数の共同作成者が作業する場合には特に顕著です。アクセス許可を適切に管理すれば、誰が何を実行できるのかを効率的かつ厳密に制御できます。
13. Fabricの管理
SaaSとしての管理
Fabric 管理者は、Fabric の
・アーキテクチャ
・セキュリティ機能
・ガバナンス機能
・分析機能
・展開とライセンス供与のためのさまざまなオプション
をしっかり理解している必要があります。
また、Fabric 管理者ポータルとその他の管理ツールに精通している必要があり、組織のニーズを満たすよう、Fabric 環境を構成し、管理できなければなりません。
Fabric 管理者は、事業目標に合わせて Fabric が展開され、使用され、組織の方針や基準に準拠するよう、ビジネス ユーザー、データ アナリスト、その他の IT プロフェッショナルと緊密に連携します。

仮装はOneLake
テナント
通常、1つの組織が持つFabricインスタンス(テナント)は1つ(EntraIDと連携している)
テナントには1つのOneLakeが紐づいている(OneLake階層構造のルートが「テナント」に対応する)
容量
1つのテナントには複数の容量を関連付けできる
ドメイン
ワークスペースを論理的にグループ化したもの
通常は組織の業務別にドメイン分けされる
例:販売用、マーケティング用、財務用
ワークスペース
アイテムをまとめる単位
ユーザのアクセス権の範囲として使える
例:販売ワークスペースには、実際の販売組織に所属するユーザが割り当てられていて、DWHの作成、ノートブックの実行、セマンティックモデルの作成、レポートの作成などが行える
アイテム(コンテンツ)
Fabricの構成要素
例:DWH、データパイプライン、セマンティックモデル、ダッシュボード、など
管理者の種類
・Microsoft365管理者
・PowerPlatform管理者
・Fabric管理者:従来のPowerBI管理者の役割を果たす
管理用ツール
・Fabric管理ポータル:従来はPowerBI管理ポータルだったもの
・Microsoft 365 管理センター:https://admin.cloud.microsoft/
・Microsoft Purview コンプライアンスポータル:https://compliance.microsoft.com/
・MicrosoftEntra管理センター:https://entra.microsoft.com/
・PowerShell コマンドレット
・管理 API および SDK
管理者の役割
セキュリティとアクセスの制御
Fabric 管理の最も重要な側面の 1 つは、承認されたユーザーのみが機密データにアクセスできるように、セキュリティとアクセス制御を管理することです。 ロールベースのアクセス制御 (RBAC) を使って、コンテンツを表示および編集できるユーザーを定義したり、オンプレミスのデータ ソースに安全に接続するためのデータ ゲートウェイを設定したり、Microsoft Entra ID を使ってユーザー アクセスを管理したりできます。
データ ガバナンス
効果的な Fabric 管理を行うには、データ ガバナンスの原則をしっかりと理解する必要があります。 テナント内の受信接続と送信接続をセキュリティで保護する方法、および使用状況とパフォーマンスのメトリックを監視する方法を把握しておく必要があります。 また、データ ガバナンス ポリシーを適用して、承認されたユーザーのみがテナント内のデータにアクセスできるようにする方法も理解しておく必要があります。
カスタマイズと構成
Fabric 管理には、組織のニーズに合わせてプラットフォームをカスタマイズおよび構成することも含まれます。 これには、テナントをセキュリティで保護するためのプライベート リンクの構成、データ分類ポリシーの定義、レポートとダッシュボードの外観の調整などが含まれます。
監視と最適化
Fabric 管理者は、プラットフォームのパフォーマンスと使用状況を監視し、リソースを最適化し、問題のトラブルシューティングを行う方法を把握しておく必要があります。 これには、監視とアラート設定の構成、クエリのパフォーマンスの最適化、容量とスケーリングの管理、データ更新と接続に関する問題のトラブルシューティングなどが含まれます。
Fabric 管理ポータル

PowerShell コマンドレット
PowerShellで実行できる簡単なコマンド(コマンドレット、cmdlets)のうち、Fabric管理用に使えるものもある
たとえば、Fabric のコマンドレットを使用して、グループの体系的な作成と管理、データ ソースとゲートウェイの構成、および使用状況とパフォーマンスの監視を行うことができます。 これらのコマンドレットを使用して、Fabric 管理 API および SDK を管理することもできます。
管理 API および SDK
たとえば、API と SDK を使用して、グループの作成と管理、データ ソースとゲートウェイの構成、および使用状況とパフォーマンスの監視を行うことができます。 API と SDK を使用して、Fabric 管理 API および SDK を管理することもできます。
これらの要求は、Postman など、OAuth 2.0 認証をサポートする任意の HTTP クライアント ライブラリを使用して行うことができます。また、PowerShell スクリプトを使用してプロセスを自動化することもできます。 詳細については、「Microsoft Power BI REST API」を参照してください。
管理監視ワークスペース

Fabric のセキュリティ管理
Fabric 環境内でユーザーに割り当てられるアクセスと機能のレベルは、ライセンスによって制御されます。 管理者は、ユーザーにライセンスを付与することで、各自の役割を効果的に実行するために必要なデータと分析にアクセスできるようにする一方で、機密データへのアクセスを制限したり、データ保護の法律や規制に確実に準拠させることができます。
管理者は、ライセンスを管理して、必要なユーザーにのみライセンスが効率的に割り当てられるようにすることで、コストを監視および制御できます。 これは、不要な出費を防ぎ、リソースが組織によって効率よく利用されるようにするのに役立ちます。
ライセンスの割り当てと管理のための適切な手順を設けると、データと分析へのアクセスを制御し、規制に確実に準拠し、コストを最適化するのに役立ちます。
Fabric に関するライセンスの管理は、Microsoft 365 管理センターで処理されます。 ライセンスの管理について詳しくは、ユーザーへのライセンスの割り当てに関する記事をご覧ください。
Fabricのデータガバナンス
コンテンツの保証
コンテンツの保証は、特定の Fabric アイテムを組織全体で信頼され、使用を承認されているものとして "昇格" 、さらに "認定" することで、データ資産に対する信頼を確立するのに役立つ、重要なガバナンス機能です。
・昇格:必要なアクセス許可が与えられているワークスペース メンバーなら誰でも実行できます。
・認定:管理者がテナントで有効にする必要があります。そして、指定された認定者だけが是認できます。

機密データのスキャン
"メタデータ スキャン" を使って、組織の Fabric アイテムのすべてのメタデータ(秘密度ラベルなど)のカタログ化とレポートを有効にすると、データのガバナンスが容易になります。 "スキャナー API" は、Fabric アイテムで機密データをスキャンできる Admin REST API のセットです。 スキャナー API を使って、データ ウェアハウス、データ パイプライン、セマンティック モデル、レポート、ダッシュボードで、機密データをスキャンします。 スキャナー API を使うと、構造化データと非構造化データの両方をスキャンできます。
データ系列の追跡
"データ系列" は、Fabric を通過するデータのフローを追跡する機能です。 データ系列を使うと、データの送信元、変換方法、送信先を確認できます。 これは、Fabric で使用できるデータとその使用方法を理解するのに役立ちます。
完
補足
ワークロードとは
ワークロード =
「リソースと、ビジネス価値をもたらすコード…の集まり」
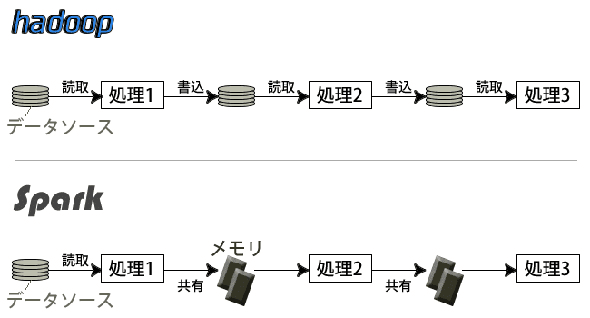
Sparkとは
・オープンソースの分散処理システム
・ビッグデータの分析に使える
・Hadoopの進化版(ストレージではなくメモリ上で処理できるようになった)

Apache SparkをAzure上で使いたい場合の選択肢
・Azure Synapse
・Azure HDInsight
・Azure Databricks
DataBriksとは

Databricks は データの取り込み (ETL)、分析、AI (生成AI)、機械学習 (Machine Learning)、BI (Business Intelligence) 、データ ガバナンス などの機能が統合された分析基盤サービス (レイクハウス プラットホーム) になります。
そして、Azure Databricks は、Azure 基盤に最適化され、Azure サービスと簡易に連携可能な フルマネージドの Databricks サービスとなります。
Azure DatabricksとAzure HDInsightの違い
Azureのエンタープライズ向けの分散処理サービスにはAzure HDInsightもあります。分散処理で混同しやすいのですが違いを端的に述べてしまうと、Azure DatabricksがDatabricksとの連携であるのに対して、Azure HDInsightはApache Hadoopのディストリビューションであるということです。
①モデルを素早く構築してデプロイできる「AML」
②コラボレーション対応のSparkベースで、高速で使いやすい「Databricks」
③分析情報を得るまでの時間を大幅に短縮できる「Synapse」
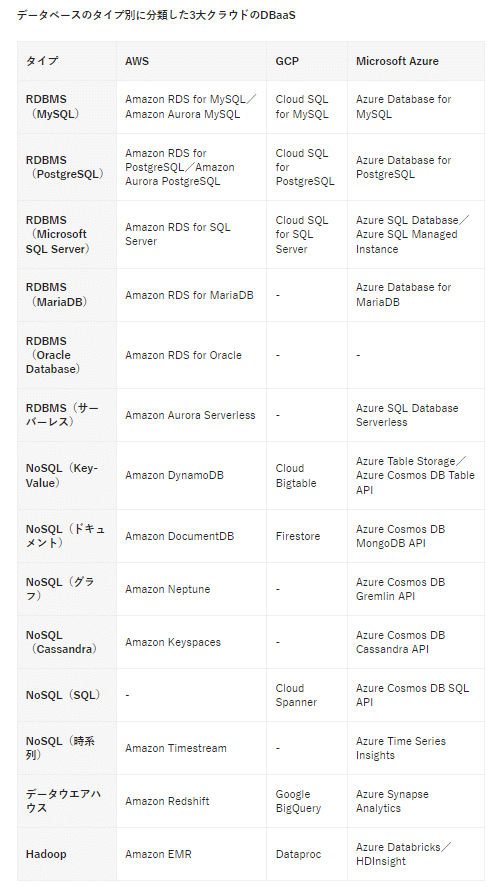
DBaaS
Team Data Science Process (TDSP)
リアルタイムストリーム処理
Azureサービス
動画
この記事が気に入ったらサポートをしてみませんか?