#消費者物価指数 #e-Stat #Python #GoogleColab #ChatGPT

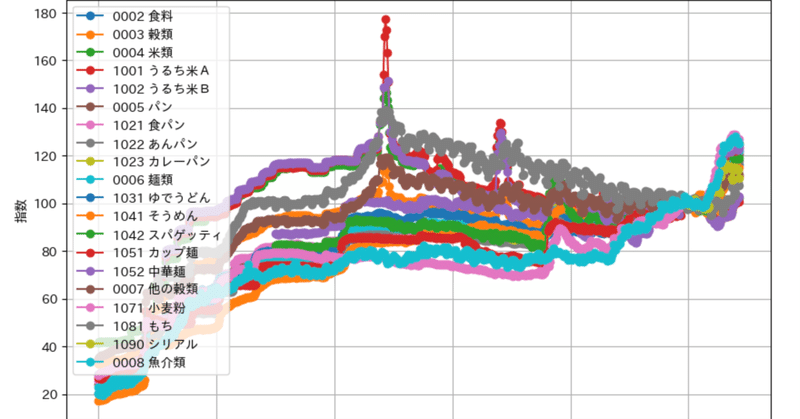
品目ごとに推移グラフ
消費者物価指数を品目ごとに調べたい。
ChatGPTに聞きながらPythonのコードを作成しました。
基準品目の番号をカンマで区切って選択してください: 3,6上記のように番号を指定するとグラフを作成できます。
データの取得にはe-StatのAPIを使っています。

この機能をGPTsに実装したい(できるかなあ?)。
そのPythonコード
# matplotlibの文字化け対策
!pip install japanize-matplotlib
import japanize_matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# eStatのAPIをたたくURL
csv_url = 'http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?cdTab=1&cdArea=00000&cdTimeFrom=1970000101&appId=<アプリID>&lang=J&statsDataId=0003427113§ionHeaderFlg=2&replaceSpChars=0'
# CSVデータをURLから読み込む
data = pd.read_csv(csv_url)
# データの前処理
# dropnaを使用して、NaN値を含む行を削除
data['value'] = pd.to_numeric(data['value'], errors='coerce')
data['時間軸(年・月)'] = pd.to_datetime(data['時間軸(年・月)'], format='%Y年%m月', errors='coerce')
data.dropna(subset=['value', '時間軸(年・月)'], inplace=True)
# ユーザーに選択肢を提示
unique_items = data['2020年基準品目'].unique()
print("選択可能な基準品目:")
for i, item in enumerate(unique_items):
print(f"{i}: {item}")
# 選択された基準品目に基づいてデータをフィルタリング
selected_indices = input("基準品目の番号をカンマで区切って選択してください: ")
selected_indices = [int(x) for x in selected_indices.split(',')]
selected_items = [unique_items[i] for i in selected_indices]
# グラフを描画
plt.figure(figsize=(10, 6))
# filtered_data.set_index('時間軸(年・月)', inplace=True) は、pandas データフレーム filtered_data のインデックスを 時間軸(年・月) 列に設定するための処理
for item in selected_items:
filtered_data = data[data['2020年基準品目'] == item]
filtered_data.set_index('時間軸(年・月)', inplace=True)
plt.plot(filtered_data.index, filtered_data['value'], marker='o', label=item)
plt.title('指数の推移')
plt.xlabel('年月')
plt.ylabel('指数')
plt.legend()
plt.grid(True)
plt.show()この記事が気に入ったらサポートをしてみませんか?