Lec12: 重回帰分析④重回帰分析の解釈と適切な変数の個数

こんばんは!シルバーウィーク真っ只中ですね(とはいってもコロナがありますが)。先週は、説明変数や被説明変数をモデルに応じて様々な形に加工するという事をやりました。対数を取ったり、ダミー変数を使ったり、交差項を使ったり、状況に応じて説明変数を上手く使うことはとても大切です。(交差項はちょっとだけレベルが上がるので、必ずしも卒業論文で使う必要はないと思います。特に学部4年生から計量経済学を学び始めた方は少し間に合わないかもしれません。) それと同時に、相関のある変数同士を説明変数に組み込んだ際に生じる多重共線性の問題も扱いました。多重共線性が生じると、誤差項の仮定自体には影響を与えない一方で、出てくる係数の値が不安定になる(極端な値が出てくる)可能性がありますので、やはり避けなければいけません。こうしたことも、卒論では必ず気を付けなければいけませんので、注意してくださいね。
さて、今日はいよいよ重回帰分析のラスト、重回帰分析の解釈と適切な変数の個数をどうするか、という問題を扱います。今日の内容がマスターできれば、卒業論文に関してはまず問題ないでしょう。では、頑張っていきましょうか。
1.重回帰分析における係数の解釈
復習ですが、次のようなモデルを考えてみましょう。

これは年齢が賃金に与える影響について分析したモデルです。内生性の問題を避けるため、その他性別ダミー、学歴ダミー、職歴を説明変数として組み込んでいます。この時、係数β1、β2、β3、β4はどのように解釈できるのでしょうか。係数を解釈するにあたって、とても重要な概念があります。それは他の条件一定(Ceteris Paribus)と呼ばれるものです。この時、β1の解釈はX1i以外の要素、つまり男か女かは一定であり、学歴も一定、職歴も一定という条件の下で、年齢だけを変化させた場合に賃金はどのように変化するか、という意味になります。現代社会では、女性の社会進出が喫緊の課題となっており、ひょっとすると25歳男性より30歳女性の方が賃金が低いかもしれません。また、高卒の25歳よりも大卒の25歳の方が一般的に賃金が上であることも良く知られた話です。さらに職歴の長さによっても変わってくるでしょう。この時、高卒女性35歳より、大卒男性30歳の方が賃金が高いからと言って、年齢が上がれば賃金も上がるという仮説は成り立たないと結論付けて良いでしょうか。誰が考えてもこれはおかしいのは明らかです。年齢が上がれば賃金も上がるという仮説を示したければ、例えばですが大卒男性職歴10年同じで、年齢だけが違う状況でどのように賃金が変化するかを見なければいけません。これが、他の条件一定(Ceteris Paribus)です。
β2、β3、β4の解釈においても同様です。β2は年齢、学歴、職歴が一緒で性別だけが異なる場合、性別が賃金に与える影響を示すものです。β3は年齢、性別、職歴が同じで学歴だけが異なる場合、学歴がどの程度賃金に影響を与えるのかを示します。β4は年齢、性別、学歴が同じで職歴だけが異なる場合、職歴は賃金にどのような影響を与えるのかを表します。
重回帰分析の係数は、その変数以外の条件が全て同じだった時、その変数だけ変えたときどうなるかを表したものです。実はこの他の条件一定(Ceteris Paribus)という考え方は皆さん小学校~中学校の時に習っているんです! 小学校の時、対照実験というものを学習したのを覚えているでしょうか。

(出典:『ネットだけで点数が上がる中学生のためのサイト』https://exam.fukuumedia.com/kogosei-btb-toi/)
例えば、光合成の実験なんかがまさにその典型例でしょう。オオカナダモが入った2つの試験管を用意して、片方にはアルミニウム箔をつけることで気温等他の条件を全て固定したうえで、光が光合成に与える影響を分析する者でしたよね。
社会科学における因果関係の検証も、この考え方に基づきます。ただし、自然科学と決定的に違うのは、実験が難しいという点です。例えば、アベノミクス第一の矢と呼ばれる量的・質的金融緩和政策を実験室で実験することなんて不可能です。先日、自民党総裁選挙にて高市早苗候補者がインフレ率2%達成するまでPB(基礎的財政収支:プライマリーバランス)黒字化を凍結すると主張し、それに対し麻生太郎財務大臣が『日本のマーケットを実験場にするつもりはない』と否定する一幕がありましたが、PBバランス黒字化凍結という政策も、事前の実験を行うことは不可能です。薬学(例えば新型コロナワクチン)なんかでは、事前に治験と呼ばれる実験を行い、有効性を確かめたうえで政府が認証して使えるようにするという流れを取りますが、社会科学ではこれは出来ません。では、どうすれば良いのか。詳しいことは、後日(数か月はかかるかな?)『実験と準実験、モデリング』というテーマで記事を書きますので、お楽しみに!!
2. 適切な変数の個数の設定
さて、重回帰分析最後にして最大の問題、説明変数の数をどうするか、という話に移りましょう。これまで、内生性の問題を解消するために説明変数の数を増やそうとするのが重回帰分析だ!と繰り返し主張してまいりました。では、具体的に何個説明変数を入れれば良いのでしょうか。また、自分が入れた説明変数は本当に必要なものなのでしょうか。これらの問題を考えていきましょう。
まず、適切な説明変数の個数を調べる方法として、自由度修正済み決定係数の利用が挙げられます。自由度修正済み決定係数はモデルがどれくらいデータに当てはまっているかを見る指標でしたよね。なので、説明変数をいくつか入れてみて、最も自由度修正済み決定係数が高かったモデルを採用するという方法があります。ただこの方法は簡易的であり、期末レポート程度に使用するなら構いませんが、卒業論文となるともうちょっと厳密な方法を使用する必要があります。それが、F検定と呼ばれる検定を使用する方法です。
次のようなモデルを考えてみましょう。

①のモデルは、先ほどと同じように説明変数を4個入れた元のモデルです。このモデルのことを非制限モデル(unrestricted model)と言います。一方で、②は①のモデルからX2iとX3iの2つを除いたモデルです。このモデルを制限モデル(restricted model)と言います。ここで、次のような帰無仮説を立ててみましょう。
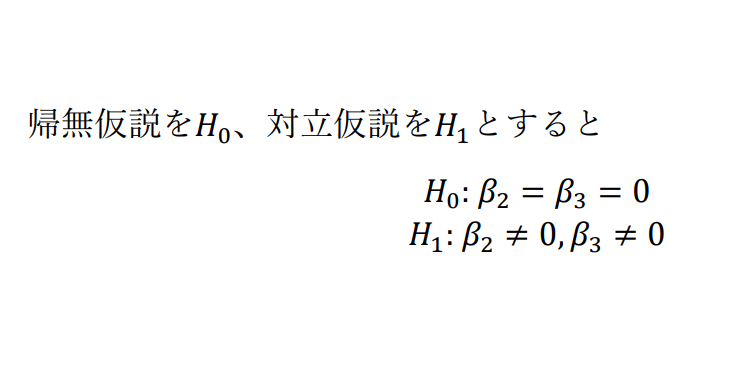
おなじみ、帰無仮説と対立仮説です。帰無仮説にはβ2=β3=0と設定しました。この意味は、説明変数にX2i、X3iを入れても意味はありませんよ、というものです。もし帰無仮説が採択された場合は、非制限モデルではなく制限モデルを採用し、説明変数からX2iならびにX3iを除外することになります。では、帰無仮説を採択/棄却する基準はどうすればよいでしょうか。この時、次のF値と呼ばれる値を導出します。

F値を求めるときに、残差平方和を使っても構いませんが、決定係数を使うほうが計算しやすいでしょう。それぞれ、制限モデルと非制限モデルの決定係数をExcelか何かで求めることで、容易にF値を計算することが出来ます。ここで、分母の(N-k-1)は非制限モデルの自由度で、データ数から(説明変数の数+1)を引いた値になります。分子のqは非制限モデルと制限モデルの自由度の差で、簡単に言えば帰無仮説や対立仮説にある係数の個数です。(今回はβ2とβ3について見ているわけなので、q=2となります。)
F値もt検定と同様に臨界値があります。


求めたF値が臨界値以上であれば、帰無仮説を棄却して対立仮説を採択します。つまり、説明変数に加えた非制限モデルを使ってもOKということになるわけです。臨界値の値については、t検定の時にt分布表があったのと同様に、F検定にもF分布表が存在します。基本的にはテキストの巻末に必ず掲載されているので、そちらを参照して論文を書いてください。(著作権の都合上、この記事には掲載しません。) F分布表にはいくつか種類が存在しますが、このうち分子の自由度と分母の自由度が書かれた5%有意水準のものを使用してください。
3. 最後に
さて、これまで12回にわたって単回帰分析から始まり、重回帰分析とやってまいりました。計量経済学は難しいです。そんな生易しいものではありません。しかし、ポイントを抑えれば必ずマスターできます。そのポイントこそが、これまでさんざん強調してきた誤差項の仮定というものです。回帰モデルが説明変数と被説明変数の因果関係を正しく描写できるようにするために、厳密な仮定を置いて行うわけです。特に誤差項の仮定の中でも4番目の仮定は厄介でしたよね。ある意味、この4番目の仮定をどう克服するかは永遠の課題とも言えそうです。ただ、その4番目の仮定に反する内生性の問題を解決する手法として重回帰分析をマスターしました。これほど強い武器はありません。ここまでの内容が完璧にマスターできていれば、もう卒業論文を書ける水準まで到達しているはずです。しっかり復習して、自分のものとしてみてください。
私のnoteの記事の前半部はこれにて終了になります。卒業論文で回帰分析を使いたい方は、この前半部の内容(Lec0~Lec12)がマスターできていれば十分です。一方で、更に大学院博士前期課程まで行きたい、各大学などが実施している論文コンクールに出場したいと考えている場合は、これでは不十分です。10月から後半部に入ります。主な内容としては固定効果モデル、IV(操作変数法:Instrumental Variable)、DID(階差の階差:Difference-in-Difference)、RDD(回帰不連続デザイン:Regression Discontinuity Design)、Probit 回帰、 Logit回帰、AR(Auto Regression: 自己回帰モデル)、VAR(Vector Auto Regression: ベクトル自己回帰モデル)あたりを扱います。(当方絶賛修士論文執筆中なので、どこまで書けるかわかりませんが...)合わせて、社会科学における因果関係の把握としての実験と準実験の話もしていきます。そしてその話は、何故経済学や政策科学が自然科学と同様の『科学(Science)』としての側面を有しているかという根源的な話にも繋がってきます。相当難しい内容が盛りだくさんですが、後半戦も頑張りますので、みなさんどうかよろしくお願いします!!
この記事が気に入ったらサポートをしてみませんか?