
ComfyUI - 初手の初手

852話さんにこんな素敵な動画を作っていただきました。
AI画像生成と人間のコラボで
— Dr.(Shirai)Hakase (@o_ob) September 9, 2023
みっくみくなアイドルになれました#AI美少女にしていいよ https://t.co/ZbqGN99x8F pic.twitter.com/Y5GN22jDbY
最近StableDiffusion界隈で気になっていたのですが、Automatic1111からComfyUIというノードベースのGUI操作環境がなかなか良さそうです。
色々細かいSDXLによる生成もこんな感じのノードベースで扱えちゃう。

852話さんが生成してくれたAnimateDiffによる動画も興味あるんですが、Automatic1111とのノードの違いなんかの解説も出てきて、これは使わねばという気持ちになってきました。
インストール
Windows 用(NVIDIA GPUもしくはCPUのみでも)のポータブルスタンドアロンビルドがリリースページにあります。
ダウンロードへの直接リンク Direct link to download
ComfyUI_windows_portable_nvidia_cu118_or_cpu.7z
→1.42GBありました。
ダウンロードを解答するには7-Zipが必要。
解凍して、README_VERY_IMPORTANT.txtを開く。

実行する方法
NVIDIA gpuをお持ちの場合:run_nvidia_gpu.bat
低速CPUモードで実行するには:run_cpu.bat
もしUIで赤いエラーが出たら、モデル/チェックポイントがあることを確認してください: ComfyUImodelscheckpoints
diffusion 1.5の安定版は、https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.ckpt からダウンロードできます。
アップデートの推奨方法
ComfyUIのコードをアップデートするには: updateupdate_comfyui.bat
Python依存のComfyUIをアップデートするには、Python依存に問題がある場合のみ実行してください。
updateupdate_comfyui_and_python_dependencies.bat
comfyuiと別のUIの間でモデルを共有するために実行します:
ComfyUIディレクトリにextra_model_paths.yaml.exampleというファイルがあります。
このファイルをextra_model_paths.yamlにリネームし、お好みのテキストエディタで編集してください。
run_nvidia_gpu.bat をダブルクリックする

スルスルっと実行されて、ブラウザが立ち上がってこんな画面になりました。Pythonもダウンロードしたパッケージに組み込まれているみたいです。

さっそく生成してみよう…と思って「Queue Prompt」を押してみたけど

そうです、モデルのチェックポイントファイルをダウンロードしていませんでした。
こちらのURLからStableDiffusionV1.5を入手して、
https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.ckpt
このディレクトリに保存しましょう
ComfyUI_windows_portable\ComfyUI\models\checkpoints\v1-5-pruned-emaonly.ckpt
ダウンロードが終わったら、もう一度「Queue Prompt」を押してみましょう。コマンドラインにキューが走り…
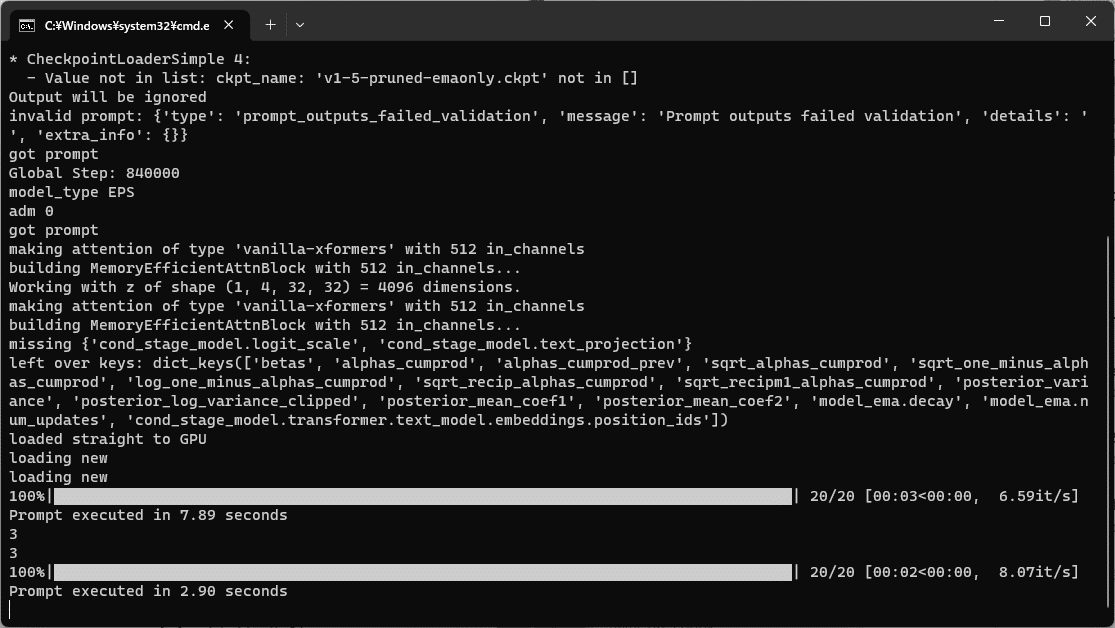

右の方に画像が生成されています!

[Save]ボタンを押すとワークフローを保存できます。
この json ファイルは [Load]機能で読み込むものなので、どこに保存されていても大丈夫なようです。私はマイドキュメントに「ComfyUI」フォルダを作って保存しておくことにしました。
肝心の画像ファイルは
「ComfyUI_windows_portable\ComfyUI\output」に保存されています。
プロンプトを唱えてみる
いわゆるText2Image(テキストからの画像生成)のプロンプトは「CLIP Text Encode (Prompt)」にあるようです。
beautiful scenery nature glass bottle landscape, , purple galaxy bottle,
この辺を自分で構造を理解しながら使える…私がComfyUIを使うどう気になった一つの理由でもあります。

ちょっとプロンプトにいたずらして、
miku in a beautiful scenery nature glass bottle landscape, purple galaxy bottle,
にしてみました。
ついでに「Extra Options」をチェック☑して、「Batch Count」を10にしてみました。

10画像連続で生成されました!

StableDiffusionによるText2Imageの解説がこんなに簡単に!
せっかくなので全体をわかりやすく解説してみました。

左上にあるのがモデルです。「Load Checkpoint」でダウンロードしてきたSD v1.5 pruned-emaonlyをロードしています。

このモデルはCLIPとVAEを必要とするようです。
CLIPは画像と文字の位置関係を司るモデルです。ここが2つのノードに分岐して、正プロンプトとなるテキスト入力と、ネガティブプロンプトとなるテキスト入力を渡します(どちらも同じCLIPモジュール)。CLIPの出力はCONDITIONINGとして、次のノード「KSampler」のそれぞれ「Positive」と「Negative」に入ります。

このサンプラーは冒頭のチェックポイントのモデルを渡されています。サンプラーの引数は以下の通りでした。
・seed [乱数のシードとなる整数]
・Control_after_generate {randomize,fixed, increment, decrement}
この値は生成されたあとにランダムにするか、加算か減算か、もしくは固定するか、という設定のようです。次のセクションで実験してみます。
・steps {20}
・cfg {8.000}
・sampler_name {euler他各種}
・scheduler {nomal}
・denoise {1.00}
Control_after_generateを実験してみる
例えば、seed=0として、incrementにしてBatchで10枚生成すると、何度やっても同じ結果が10枚生成されるようになります。
seed=10と表示されていますが、実際には0~9が生成されたということなのでしょうか。

seed=100として同じ実験を2回行うと、今度は、seed=110となりました。100~109の10枚が生成されたようです。


こういう実験ができるようになると、再現性が高い画像を作れるようになりますね!
サンプラーの違いを味わう
次にサンプラーを eularからdpm_2_ancestralにしてみました。
先程と同様に10回生成してeularとの違いを比較してみます。

レイアウトは似ていますが、細部は異なります。
お好みはどちらでしょうか。
stepの違いを味わう
次はdpm_2_ancestralのままstepを20から10、そして1にしてみます。

stepとはStableDiffusionの超解像度化+CLIPによる重み付けの繰り返しによって画像のノイズを除去していく過程であることがなんとなく見えてきます。stepが少ないほうがあっという間に生成が終わりますが、魅力的な絵になることは難しいです。
次にstepを{1,5,50,100,200,400}と上げてみます。シードは1づつ増やしています。

stepは大きくなれば大きくなるほど演算時間が伸びますが、実は画質が確実に良くなるというわけではないです。背景のリアリティはある程度、上がっていきますがMikuを指定しているわりにまともにキャラクターイラストとして成立しているものはほとんど現れません。生成画像のサイズやプロンプト、モデル、サンプラーにも依存しますが、だいたい50~100ぐらいのレンジが最大と考えてよいかと思います。



CFGスケールについて学ぶ
cfgと書かれているパラメータはおそらくCFGスケールと理解します。これはStable Diffusionの追加設定の1つで、プロンプトや入力画像に近い画像を生成するために使用されます。CFGスケールの値を大きくすると、プロンプトを無視した出力が減りますが、画像の色彩や構図が崩れる可能性があります。CFGスケールの値を小さくすると、画像がぼやけますが、生成されるAIイラストの自由度が高まります。
Stable DiffusionのCFGスケールのデフォルト値は7で、適正な値は7~10とされています。CFGスケールの値が低すぎたり高すぎたりすると、絵が崩れることがあります。
実験として、cfg=10として、プロンプトを"miku in a space"、step={1,2,4,8,16,32,64}、そして今度は10試行ごとにシードを0~9で固定して生成してみます。

なんとなく画像が錬成されていく様子を見ることができます。
ネガティブプロンプトの影響を見る
次にネガティブプロンプト「text, watermark」の影響を確認します。step=64でネガティブプロンプトありの状態で2回生成し、次にネガティブプロンプトを空白にして、1回生成します。同条件でネガティブプロンプトの影響がなくなった画像を確認できます。

とくにネガティブプロンプトに書かれているような text(文字), watermark(透かし)が入るわけではありませんが、ちょっと面白い絵には出会えました。


続きます!
その後公開されたこちらの記事がやれること色々まとまってます
この記事が気に入ったらサポートをしてみませんか?