
Stable Diffusion 3 論文公開 - SD3、UNetやめるってよ

いろいろあって個人ブログで書きます。
Stability AI 公式より入電。
本日、Stable Diffusion 3を支える基礎技術について掘り下げた研究論文を発表します。
Stable Diffusion 3は、DALL-E 3、Midjourney v6、Ideogram v1といった最先端のテキスト画像生成システムよりも、人間の嗜好評価に基づくタイポグラフィとプロンプトの順守において優れています。
私たちの新しいマルチモーダル拡散変換器(MMDiT)アーキテクチャは、画像と言語表現に別々の重みセットを使用し、SD3の旧バージョンと比較して、テキスト理解とスペリング機能を向上させています。
(1/3) Stable Diffusion 3 を支える基礎技術について掘り下げた研究論文を発表します。
— Stability AI Japan (@StabilityAI_JP) March 5, 2024
こちらの画像のプロンプト
A beautiful painting of flowing colors and styles forming the words “The SD3 research paper is here!”, the background is speckled with drops and splashes of paint. pic.twitter.com/pQukPHetLI
重要なポイント
本日、Stable Diffusion 3を支える基礎技術について掘り下げた研究論文を発表。Stable Diffusion 3は、DALL-E 3、Midjourney v6、Ideogram v1といった最先端のテキスト画像生成システムよりも、タイポグラフィやプロンプトの忠実性において優れている。
Multimodal Diffusion Transformer(MMDiT)アーキテクチャは、画像表現と言語表現に別々の重みセットを使用することで、以前のバージョンのSD3と比較して、テキスト理解とスペリング機能が向上しています。
Stable Diffusion 3の早期プレビューの発表に続き、本日、次期モデルリリースの技術的な詳細をまとめた研究論文を発表します。論文は近日中にarXivで公開される予定です。また、早期プレビューに参加するためのウェイティングリストに登録することをお勧めします。
パフォーマンス
SD3をベースラインとして、視覚的な美しさ、プロンプトの追従性、タイポグラフィの人間による評価に基づいて、競合モデルに対してSD3が勝っている部分の概要を示します。
Stable Diffusion 3の出力画像を、SDXL、SDXL Turbo、Stable Cascade、Playground v2.5、Pixart-αなどのさまざまなオープンモデルや、DALL-E 3、Midjourney v6、Ideogram v1などのクローズドソースシステムと比較し、人間のフィードバックに基づいてパフォーマンスを評価しました。これらのテストでは、人間の評価者が各モデルの出力例を提供され、モデルの出力が与えられたプロンプトのコンテキストにどれだけ忠実に従っているか(「プロンプトの追従性」)、プロンプトに基づいてテキストがどれだけうまくレンダリングされているか(「タイポグラフィ」)、どの画像がより美的品質が高いか(「視覚的審美性」)に基づいて、最良の結果を選択するよう求められました。
テストの結果、Stable Diffusion 3は、上記のすべての分野において、現在の最先端のテキスト画像生成システムと同等か、それを上回ることがわかりました。
消費者向けハードウェアを使用した初期の最適化されていない推論テストでは、8Bのパラメータを持つ最大のSD3モデルがRTX 4090の24GB VRAMに収まり、50サンプリングステップを使用した場合、解像度1024x1024の画像を生成するのに34秒かかります。さらに、最初のリリースでは、800mから8Bパラメータモデルまで、Stable Diffusion 3の複数のバリエーションが用意され、ハードウェアの障害をさらに排除します。
アーキテクチャの詳細
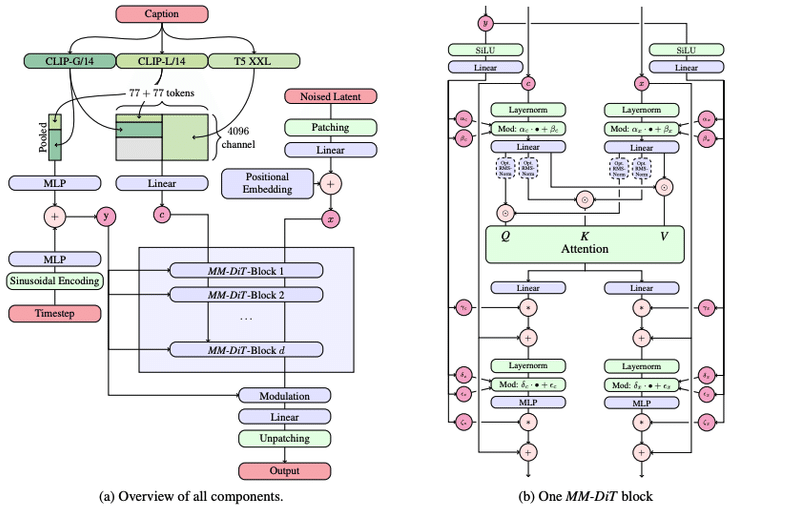
テキストから画像への生成では、モデルはテキストと画像の両方のモダリティを考慮しなければなりません。このため、この新しいアーキテクチャを、複数のモダリティを処理できることにちなんでMMDiTと呼んでいます。Stable Diffusionの以前のバージョンと同様に、適切なテキストと画像表現を導き出すために、事前に訓練されたモデルを使用します。
具体的には、3つの異なるテキスト埋め込みモデル(2つのCLIPモデルとT5)を使用してテキスト表現をエンコードし、改良された自動エンコードモデルを使用して画像トークンをエンコードする。
修正マルチモーダル拡散変換器のブロックの概念的視覚化: MMDiT
SD3アーキテクチャは拡散変換器(「DiT」、Peebles & Xie、2023)をベースにしている。テキストと画像の埋め込みは概念的に全く異なるため、2つのモダリティに対して2つの別々の重みセットを使用する。上図に示すように、これは各モダリティに対して2つの独立した変換器を持つことに等しいが、注目操作のために2つのモダリティのシーケンスを結合することで、両方の表現が独自の空間で動作しながらも、もう一方の表現を考慮に入れることができる。
我々の新しいMMDiTアーキテクチャは、UViT(Hoogeboom et al, 2023)やDiT(Peebles & Xie, 2023)のような確立されたテキストから画像へのバックボーンを、トレーニングの過程で視覚的忠実度とテキストの整列を測定する際に凌駕する。
このアプローチを使用することで、画像とテキストのトークン間で情報が流れるようになり、生成される出力内の全体的な理解度とタイポグラフィが向上する。このアーキテクチャーは、我々の論文で議論しているように、ビデオなどの複数のモダリティーにも簡単に拡張可能である。
Stable Diffusion 3の改良されたプロンプトフォローのおかげで、SD3モデルは、画像自体のスタイルに高い柔軟性を保ちながら、様々な異なる主題や品質に焦点を当てた画像を作成する能力を持っています。
リウェイティングによる整流フローの改善
Stable Diffusion 3はRectified Flow (RF)定式化(Liu et al., 2022; Albergo & Vanden-Eijnden,2022; Lipman et al., 2023)を採用しており、学習中、データとノイズは直線的な軌跡で接続される。この結果、より直線的な推論経路が得られ、より少ないステップでサンプリングが可能となる。さらに、新しい軌道サンプリングスケジュールを学習プロセスに導入する。このスケジュールは軌跡の中間部分をより重視する。我々は、LDM、EDM、ADMなどの他の60の拡散軌道に対して、複数のデータセット、測定基準、サンプラー設定を用いて、我々のアプローチを比較テストした。その結果、従来のRF定式化は、少ないステップのサンプリング領域では性能の向上を示すが、ステップ数が増えるにつれて相対的な性能は低下することが示された。これに対して、我々の再重み付けRFは一貫して性能が向上している。
整流フロー変換モデルのスケーリング
我々の再重み付け整流化フロー定式化とMMDiTバックボーンを用いたテキストから画像への合成のスケーリング研究を行う。450Mのパラメータを持つ15ブロックから、8Bのパラメータを持つ38ブロックまでのモデルを訓練し、モデルサイズと訓練ステップの両方の関数として、検証ロスの滑らかな減少を観察する(上段)。これがモデル出力の意味のある改善につながるかどうかを検証するため、自動画像アライメントメトリクス(GenEval)と人間の好みスコア(ELO)も評価した(下段)。我々の結果は、これらのメトリクスと検証ロスの間に強い相関があることを示しており、後者がモデル全体のパフォーマンスの強い予測因子であることを示している。さらに、スケーリング傾向には飽和の兆候が見られないことから、今後もモデルの性能を向上させることができると楽観視できる。
柔軟なテキスト・エンコーダ
推論に必要な4.7Bのパラメータを持つT5テキストエンコーダを削除することで、SD3のメモリ要件は、わずかな性能低下で大幅に削減することができる。このテキストエンコーダを削除しても、見た目の美しさ(T5なしの勝率:50%)には影響せず、「パフォーマンス」セクションの上の画像にあるように、テキストの付着率(勝率46%)がわずかに低下するだけです。しかし、下の例で見られるように、T5なしの組版生成ではより大きなパフォーマンスの低下(勝率38%)が観察されるため、SD3の能力をフルに使って文章を生成するには、T5を含めることをお勧めします:
推論のためにT5を削除すると、多くの詳細や大量の書き言葉を含む非常に複雑なプロンプトをレンダリングする場合にのみ、パフォーマンスが大幅に低下します。上の図は、例ごとに3つのランダムなサンプルを示しています。
MMDiT、Rectified Flows、およびStable Diffusion 3を支える研究の詳細については、こちらの研究論文をお読みください。
(2/3) Stable Diffusion 3 は、人間の嗜好評価に基づき、DALL-E 3、Midjourney v6、Ideogram v1… pic.twitter.com/UIObql907h
— Stability AI Japan (@StabilityAI_JP) March 5, 2024
(3/3) 新しいマルチモーダル拡散Transformer(MMDiT)アーキテクチャは、画像と言語表現に別々のウェイトセットを使用し、以前のバージョンのSD3と比較して、テキスト理解とスペリング機能を向上させています。
— Stability AI Japan (@StabilityAI_JP) March 5, 2024
英文ブログ記事全文と論文へのアクセスはこちらから:https://t.co/93jCGfYOIm pic.twitter.com/o8TP0jX4lx
個人的な所感:
全然違うアーキテクチャじゃないか
CLIP、UNetどこいった・・・!
SD3、UNetやめるってよ https://t.co/8bs3lWylSE pic.twitter.com/mqTbT0Xzf2
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) March 5, 2024
これまでのStable Diffusion 1.5, 2.x, SDXL、 SDXL Turboの敵対的拡散蒸留(Adversarial Diffusion Distillation:ADD)なお
UNetに依存している機能拡張がおおく存在したのですが、実際実装を見てみると今後は難しいだろうな、とは思っていました。
結構破壊的な進化をしそうな予感です。
しかも文字、めちゃパリッとしている!どうなってんだ
こういう話、3/13にやりたいです!
この記事が気に入ったらサポートをしてみませんか?