
Fine-tuning: gpt-3.5-turboの活用事例。絵文字分類タスク改善のプロセスと、学びの言語化。

みなさん、Fine-tuning使ってますか!?
一週間ほど前に、OpenAI社からgpt-3.5-turboがFine-tuning可能になったとのアップデートがありましたね。
ニュースを見て凄そうと思いつつ、少し作業のハードルがあったり、プロンプトエンジニアリングで事足りてるから、そんなに使わないかも?🤔と思ってました。
ただ今回、重い腰を上げて、Fine-tuningを試してみたら、想像以上の結果が得られたので、そのプロセスと学びをまとめます!
システムに組み込む際の Prompt Engineering で苦戦している皆さん、Fine-tuningはかなり希望になると思います…!これからはPromptをゴニョゴニョするよりも、Fine-tuningに力を入れていこうと思いました。
ではまとめていきます!
前置きとこれまでの課題
今回は、音声メモ日記アプリ「シャべマル」の絵文字分類タスクにFine-tuningを活用して改善を試みました。「シャべマル」については以下の記事で紹介してます。
簡単にいうと、メモ内容にマッチする絵文字を、ChatGPTなどを駆使して自動的に紐づける機能があります。現在の仕組みとしてはこんな感じです。

前提として、絵文字は商用利用の関係からUnicodeで表現されるものではなく、絵文字の画像データを用いています。なので最終的に画像ファイル名を1つ選択し、それを表示しています。
処理の流れとしては、メモ内容からトピック(単語)をFunction Callingを用いて生成し、それをベクトルに変換。
そして、あらかじめ準備してある「絵文字ラベルのベクトル(1364種類)」と「トピックのベクトル」の類似度を計算して、絵文字ラベルを選定する形をとっています。
Q. なぜ一度トピック生成を挟んでいるのか?🤔
A. 理由は主に2つあります!👋
メモ内容を直接ベクトル変換し、絵文字ベクトルと類似度計算をして、最も内容に近い絵文字を選定するも、失敗。
これはかなり精度が悪かったです…。長文だと様々なテーマが含まれており、関係のない絵文字ばかりが選定されました。
HyDEという手法にもある通り、文書検索をするときなどは、Query(今回はメモ内容)とTarget(絵文字1364種類)の形式を統一する必要がありそうだなと感じています
Function CallingのEnum(列挙型)を用いて、絵文字ベクトル(1364種類)の中から選んでもらう方法は、実用的でない。
1364種類ほどの多クラスになると、生成結果が架空の絵文字ラベルになったり、空文字が出力されたりして、使い物にならなかったです。
また前提情報として絵文字1364種類のラベル名(約8,000token)を毎回伝えるのは、token数が膨大となり、かなりコストが大きくなりました
1~2桁ほどの他クラス分類が、Function Callingの限界なのかなと感じています
というわけで、トピックを一旦挟んで絵文字の類似度検索をしていたのですが、これはこれで品質に限界があったんですね。。

やはり情報が欠落してしまうのが大きいのと、絵文字のバリエーションにも限界があるので、対応する絵文字がない場合「なぜこの絵文字が…?」といったものが選択されてしまいます。具体的にはこんな感じです。

「音楽のプレイリストを作成する」って言っているのに、なんでひな祭り!?🎎
「プログラミングスキル伸ばしたい」のに、なぜ城が…?🏯
「早起き」についてメモしているのに、日が暮れちゃダメでしょ…🌅
などなど(笑)
良い感じの絵文字を選んでくれる場合もあるのですが、正直なところ納得感がないケースが多いです😢
Fine-tuningによるアプローチ
ずっとなんか良い方法ないかなーと頭の隅で考えていたのですが、3日前くらいに「絵文字分類タスク、Fine-tuningで改善できるんじゃないか!?」とふと思ったわけです!

(類似度計算が残っているのは、生成ミスしてもシステム的に必ず絵文字を選択できるようにするため)
つまりgpt-3.5-turboに絵文字ラベルを教えて、直接ラベリングしてもらおうという魂胆です。というわけでFine-tuningのプロセスをお伝えする前に、先に結果をお見せします!


(左:トピック生成する問題ありパターン、右:Fine-tuningでのパターン)
つまり、Fine-tuningで得られた嬉しいことは、
指定されたラベル名のみを出力する形式にできた
ラベル名をある程度記憶し、それを出力してくれた(成功確率: 9割)
メモ内容に合わせてChatGPTが解釈して選定してくれた
※ちなみにFine-tuning後は、プロンプトで絵文字ラベル名について一切教えていません。なのにこの安定具合はすごい👏
※9割の成功確率であっても、最終的に最も類似するものをシステム的に1つ選択するので、絵文字が表示されないということはありません!
ということで、想定を超える結果とポテンシャルを感じさせてくれました!絵文字の精度が上がったメモアプリ「シャべマル」をぜひ試してみてください。
さて、ここからは Fine-tuning のプロセスと、そこから得られた学びや考察をまとめていきます。テクニカルな内容が多めになります。
Fine-tuningのプロセスと学び
基本的なやり方については、以下の記事がかなり分かりやすくまとめられているので参考にしてみてください。
この記事では、今回の絵文字分類タスクにおけるデータセット作成方法と、epoch数ごとの挙動の変化、そのほか上手くいかなかった失敗事例に焦点を当ててまとめていきます。
データセット作成
やりたいこととしては、メモ内容(Input)→絵文字ラベル(Output)です。なので、この教師データを作成する必要があります。以下の手順で行いました!
まずメモのテーマを100個生成(メモ内容にばらつきを持たせるため)
各テーマをベースに、日常生活で記録されるような200文字程度のメモを gpt-3.5-turbo で100個生成
100個のメモを、人力で絵文字ラベリングする💪
地道ですが、ここが結構鍵を握ってる感じがありました。
基本的に、ここで絵文字ラベリングしたものをgpt-3.5-turboは学習する形になります。またラベル名からは拾えない人間の直感的な印象も、このデータセットを通して学習させることができる感じがします!
例えば、
有名人と出会えた → ✨
産まれたてのちっちゃい可愛い動物がいた → 🐣
学習用データセット形式へ変換

先ほど作ったデータセットを、学習用データセットの形式に整えます。形式は普段のAPIコールと似ていて、system, user, assistantメッセージの形式で作られた会話集を複数作るイメージです。
dataset = [
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": memo_1},
{"role": "assistant", "content": emoji_label}
],
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": memo_2},
{"role": "assistant", "content": emoji_label_2}
],
...
]そんなこんなで、作ったデータセットをアップロードします!
# dataをJSONL形式(JSON Lines)でダンプ
jsonl = '\n'.join([json.dumps(item) for item in dataset])
# print(jsonl)
file_response = openai.File.create(
purpose="fine-tune",
file=jsonl
)
print(file_response)# file_response(出力結果)
{
"id": "file-abc123",
"object": "file",
"bytes": 120000,
"created_at": 1677610602,
"filename": "my_file.jsonl",
"purpose": "fine-tune",
"format": "fine-tune-chat",
"status": "uploaded",
"status_details": null
}Fine-tuningジョブを作成
Fine-tuningのジョブ作成は比較的簡単です。こんな感じで作成できます!
#ファインチューニングトレーニングの開始
response = openai.FineTuningJob.create(
training_file="file-xxxxxxxxxxxxxxx",
model='gpt-3.5-turbo-0613',
hyperparameters = { "n_epochs": 9 },
suffix="emoji_cls_0829"
)
print(response)入力するのは、
training_file
- ファイルをアップロードのレスポンスで得られた`id`
model
- ここでは`gpt-3.5-turbo-0613`
hyperparameters
- n_epochsのみ指定可能
- 任意項目。ドキュメントを見ると`n_epochs: auto`も設定できるみたいですね(今知りました。デフォルトはautoかな?)
suffix
- fine-tuning model idの識別を容易にする文字列(任意)
他にもvalidation関連の項目はありますが、絵文字分類タスクは正解のない曖昧なタスクなので難しいなーと思い、省略してます。
今回の試行では、同一ファイル(データセット)を用いて n_epochs を1, 3, 6, 8, 9, 10の合計6回実行しました!パラメータを変えるだけで、様々なモデルが作成できて、Fine-tuningモデルの比較ができる体験はかなり良かったです✨
ジョブを作成したら、出来上がりを待ちます!(メール届きます)
進捗を確認したい場合は、以下のように実行できます(python)
print(openai.FineTuningJob.list(limit=1))
## 出力結果
{
"object": "list",
"data": [
{
"object": "fine_tuning.job",
"id": "ftjob-xxxxxxxxxxxxxxxxxxx",
"model": "gpt-3.5-turbo-0613",
"created_at": 1693269956,
"finished_at": 1693271499,
"fine_tuned_model": "ft:gpt-3.5-turbo-0613:personal:emoji-cls-0829:7sxxxBs",
"organization_id": "org-BtL5yxxxxxxxxxxxxQg",
"result_files": [
"file-Kwcxhxxxxxxxxxxx1KgPo"
],
"status": "succeeded", <- "succeeded"になっていたら成功!
"validation_file": null,
"training_file": "file-2lkkxxxxxxxxxxxxw0q",
"hyperparameters": {
"n_epochs": 9
},
"trained_tokens": 2361186
}
],
"has_more": false
}各Fine-tuningモデルの検証
結果的に、n_epochs={1, 3, 6, 8, 9, 10}の6パターンのモデルが出来上がりました!これらについて、以下の観点から検証していきます。
出力形式は"絵文字ラベル名のみ"になっているか?
メモ内容を理解し、それに合わせた納得感のある絵文字を選定してくれているか?(サービス体験改善に向けた今回の本目的)

まず全体的に、出力結果は絵文字ラベルのような英語の文字列を出力してくれました。出力形式を強制する効果はepoch=6くらいから強く見られた感じがします。
また、epoch数を増やしていくほど、存在する絵文字ラベルを出力をしてくれる精度が高まりました!ただし、epoch=9を上限に、epoch=10からは精度の悪化が見られました。これは謎です…(笑)
あと少し驚いたのが、学習用データセットで教え込んでいない絵文字についても推測して生成しているケースがありました。
本来であればハルシネーションにつながる挙動ですが、ドンピシャで結構当てに来てます。もしかしたら絵文字ラベルデータをすでに学習していたのかも?🤔
# 各epochのFine-tuningモデルをテストした結果
===epoch_1===
存在するカウント: 67
存在しないカウント: 33
各ラベルの出現回数: {'clipboard': 3, 'gear': 4, 'weightlifting': 2, 'suitcase': 1, 'memo': 2, 'mountain': 2, 'cook': 1, 'books': 3, 'woman-cartwheeling': 1, 'running-shirt-with-sash': 1, 'money-with-wings': 1, 'framed-picture': 1, 'camping': 2, 'chart-increasing': 4, 'weight-lifting': 1, 'label-gloves': 1, 'art': 1, 'table-tennis': 1, 'dog': 2, 'herb': 2, 'person-gesturing-ok': 1, 'checkered-flag': 1, 'hugging-face': 1, 'hamburger': 1, 'office': 2, 'coffee': 2, 'pencil': 2, 'star-struck': 1, 'homes': 1, 'fork-and-knife-with-plate': 3, 'recycling-symbol': 1, 'thought-balloon': 1, 'heart-eyes': 2, 'stopwatch': 1, 'sunflower': 1, 'camera': 1, 'deciduous-tree': 1, 'notes': 1, 'man_technologist': 1, 'sleeping-face': 1, 'ツール': 1, 'family': 1, 'woman-in-lotus-position': 1, 'laptop-computer': 1, 'scale': 1, 'video-game': 1, 'runner': 2, 'musical_keyboard': 1, 'calendar': 1, 'musical-note': 1, 'shopping-bags': 1, 'money-bag': 1, 'film-projector': 1, 'shoe': 1, 'envelope-with-arrow': 1, 'rocket': 1, 'gift': 1, 'computer-mouse': 1, 'muscle': 1, 'potable_water': 1, 'bar-chart': 1, 'car': 1, 'sparkles': 3, 'helmet-with-white-cross': 1, 'lotion': 1, 'television': 1, 'party-popper': 1, 'mag-microphone': 1, 'iphone': 1, 'sponge': 1, 'shopping_cart': 1, 'cloud': 1, 'raised-hands': 1, 'card-file-box': 1, 'house': 1}
===epoch_3===
存在するカウント: 83
存在しないカウント: 17
各ラベルの出現回数: {'clipboard': 5, 'memo': 2, 'ウェイトリフティング': 1, 'luggage': 1, 'grinning-face-with-smiling-eyes': 1, 'camping': 2, 'cooking': 1, 'books': 1, 'man-raising-hand': 1, 'sports': 1, 'money-bag': 4, 'framed-picture': 3, 'weight-lifter': 1, 'tennis': 1, 'dog': 2, 'seedling': 1, 'women-holding-hands': 1, 'thought-balloon': 8, 'bar-chart': 3, 'yellow-heart': 1, 'spaghetti': 1, 'man-office-worker': 1, 'mountain': 1, 'coffee': 2, 'card-index': 1, 'film-frames': 2, 'house-with-garden': 2, 'dart': 1, 'cook': 1, 'ハートデコレーション': 1, 'globe-showing-asia-australia': 1, 'carousel-horse': 1, 'hourglass-flowing-sand': 1, 'womans_hat': 1, 'camera': 1, 'deciduous-tree': 1, 'musical-note': 2, 'technologist': 1, 'sunrise-over-mountains': 1, 'keyboard': 1, 'automobile': 3, 'chart-increasing': 1, 'family': 1, 'lotus': 1, 'weight-scale': 1, 'video-game': 1, '人が重量挙げしている絵文字': 1, 'musical-keyboard': 1, 'cookie': 1, 'shopping-bags': 2, 'running-shoe': 1, 'leafy-green': 1, 'e-mail': 1, 'person-lifting-weights': 1, 'milky-way': 1, 'party-popper': 1, 'label=title': 1, 'カフェ': 1, 'muscle': 1, 'potable-water': 1, 'sparkles': 1, '人が自然の中でピクニックをしている絵文字': 1, 'バリヤー': 1, 'lipstick': 1, 'desktop-computer': 1, 'mobile-phone': 1, 'broom': 1, 'fruits': 1, 'trophy': 1, 'cloud-computing': 1, 'person-standing': 1, 'woman-scientist': 1}
===epoch_6===
存在するカウント: 80
存在しないカウント: 20
各ラベルの出現回数: {'clipboard': 7, 'technologist': 2, 'person-lifting-weights': 5, 'luggage': 1, 'heart-with-ribbon': 5, 'hiking-boot': 1, '料理': 2, 'books': 1, 'money-bag': 3, 'hammer-and-pick': 1, 'art': 1, 'camping': 1, 'chart-increasing': 2, 'star-struck': 1, 'framed-picture': 1, 'テニス': 1, 'dog': 2, 'potted-plant': 2, 'label-emojify': 1, 'speaking-head': 1, 'man-office-worker': 1, 'mountain': 1, 'coffee': 2, 'pencil': 1, 'film-frames': 2, 'house-with-garden': 2, 'dart-board': 1, 'artist-palette': 1, 'earth-globe-americas': 1, 'thought-balloon': 4, 'earth-americas': 1, 'hourglass': 1, 'clothing': 1, 'camera': 1, 'headphones': 1, 'sunrise-over-mountains': 1, 'memo': 1, 'automobile': 3, 'bookmark-tabs': 2, 'family': 2, 'lotus-position': 1, 'weight-loss': 1, 'video-game': 1, 'muscle': 2, 'label-healthy-lifestyle': 1, 'musical-note': 2, 'shopping-bags': 3, 'running-shoe': 1, 'leafy-green': 1, 'e-mail': 1, 'milky-way': 1, 'gift': 1, 'label-heart': 1, 'fork-and-knife-with-plate': 1, 'cup-with-straw': 1, 'bar-chart': 2, 'cosmetics': 1, 'computer-mouse': 1, 'newspaper': 1, 'mobile-phone': 1, 'sponge': 1, 'sparkles': 1, 'cloud-with-lightning-and-rain': 1, 'label-heart-decoration': 1}
===epoch_8===
存在するカウント: 87
存在しないカウント: 13
各ラベルの出現回数: {'clipboard': 7, 'technologist': 4, 'person-lifting-weights': 9, 'suitcase': 1, 'ear-with-hearing-aid': 1, 'national-park': 1, 'heart': 2, 'books': 1, 'money-bag': 2, 'hammer-and-pick': 1, 'artistic-palette': 1, 'camping': 3, 'chart-increasing': 3, 'leafy-green': 4, 'star-struck': 1, 'framed-picture': 1, 'tennis': 1, 'dog': 2, 'potted-plant': 2, 'thought-balloon': 5, 'heart-with-ribbon': 1, 'glowing-star': 1, 'spaghetti': 1, 'man-office-worker': 1, 'mountain': 1, 'coffee': 2, 'writing-hand': 1, 'film-frames': 2, 'house-with-garden': 1, 'cooking': 1, 'globe-showing-asia-australia': 2, 'stars': 1, 'hourglass': 1, 'camera': 1, 'musical-note': 1, 'sunrise-over-mountains': 1, 'automobile': 3, 'bookmark-tabs': 1, 'family': 1, 'lotus-position': 1, 'video-game': 1, 'musical-keyboard': 1, 'heart-eyed-cat': 1, 'shopping-bags': 2, 'running-shoe': 1, 'e-mail': 1, 'milky-way': 1, 'gift': 1, 'cup-with-straw': 1, 'glowing-heart': 1, 'bar-chart': 1, 'lipstick': 1, 'computer-video': 1, 'newspaper': 1, 'mobile-phone': 1, 'sponge': 1, 'tomato': 1, 'person-office-worker': 1, 'cloud-computing': 1, 'label': 1, 'headphone': 1, 'houses': 1}
===epoch_9===
存在するカウント: 89
存在しないカウント: 11
各ラベルの出現回数: {'clipboard': 7, 'technologist': 2, 'person-lifting-weights': 5, 'heart-eyed-cat': 1, 'hiking-boot': 1, 'fork-and-knife-with-plate': 1, 'books': 1, 'laptop-computer': 3, 'people-holding-hands': 1, 'money-bag': 2, 'memo': 1, 'art-palette': 1, 'wrapped-gift': 1, 'chart-increasing': 2, 'salad': 2, 'glowing-star': 1, 'framed-picture': 2, 'tennis': 1, 'dog': 2, 'potted-plant': 2, 'woman-lifting-weights': 1, 'speaking-head': 1, 'bar-chart': 4, 'heart-on-fire': 2, 'label': 3, 'spaghetti': 1, 'newspaper': 1, 'mountain': 1, 'coffee': 2, 'film-frames': 2, 'house-with-garden': 1, 'thought-balloon': 4, 'heart-eyes': 2, 'globe-showing-asia-australia': 2, 'woman-in-lotus-position': 2, 'hourglass': 1, 'coat': 1, 'camera': 1, 'musical-note': 2, 'sunrise-over-mountains': 1, 'automobile': 3, 'family': 1, 'construction': 1, 'video-game': 1, 'musical-keyboard': 1, 'shopping': 1, 'running-shoe': 1, 'e-mail': 1, 'milky-way': 1, 'gift': 1, 'heart': 1, 'restaurant': 1, 'cup-with-straw': 1, 'camping': 1, 'person-taking-bath': 1, 'shopping-bags': 1, 'radio': 1, 'mobile-phone': 1, 'soap': 1, 'tomato': 1, 'man-office-worker': 1, 'cloud-with-lightning-and-rain': 1, 'bookmark-tabs': 1, 'houses': 1}
===epoch_10===
存在するカウント: 80
存在しないカウント: 20
各ラベルの出現回数: {'clipboard': 5, 'technologist': 2, 'person-lifting-weights': 8, 'suitcase': 1, 'ear-with-hearing-aid': 1, 'national-park': 1, 'fork-and-knife-with-plate': 4, 'books': 2, 'family': 2, 'money-bag': 3, 'hammer-and-pick': 1, 'desktop-computer': 2, 'camping': 2, 'chart-increasing': 2, 'glowing-star': 2, 'framed-picture': 1, 'tennis': 1, 'dog': 2, 'potted-plant': 2, 'label-clipboard': 1, 'speaking-head': 1, 'heart-with-ribbon': 1, 'label/language': 1, 'spaghetti': 1, 'business': 1, 'mountain': 1, 'coffee': 2, 'memo': 1, 'film-frames': 2, 'house-with-garden': 1, 'career': 1, '旗': 1, 'globe-showing-asia-australia': 1, 'woman-in-steam': 1, 'リーフでは、落ち葉や木の葉っぱをイメージしています。': 1, 'watch': 1, 'wearing-clothes': 1, 'camera': 1, 'musical-note': 2, 'computer': 2, 'sunrise-over-mountains': 1, 'automobile': 3, 'presentation': 1, 'woman-in-lotus-position': 1, 'video-game': 1, 'meeting': 1, 'violin': 1, 'shopping': 3, 'running-shoe': 1, 'leafy-green': 1, 'e-mail': 1, 'milky-way': 1, 'gift': 1, 'laptop-computer': 1, 'cup-with-straw': 1, 'bar-chart': 2, 'glowing-heart': 1, 'cosmetics': 1, 'thought-balloon': 2, 'radio': 1, 'mobile-phone': 1, 'sponge': 1, 'cloud-with-lightning-and-rain': 1, 'label-emphasis': 1, 'houses': 1}
これは一部ですが、全体的に納得感のある絵文字の割合が高いです。かなり良い感じに仕上がりました!
これまでは、メモ内容と絵文字の選定を、Embeddingされたベクトル同士のコサイン類似度によって計算していました。その過程でメモ内容をトピックに変換しており、ここで情報の欠落が起きていたのですが、
Fine-tuningモデルが選定するパターンの場合、メモ内容と絵文字ラベルの紐付けは、gpt-3.5-turboの内部で行われます(約9割が直接的に紐付け。残り1割は類似度計算で補完)。
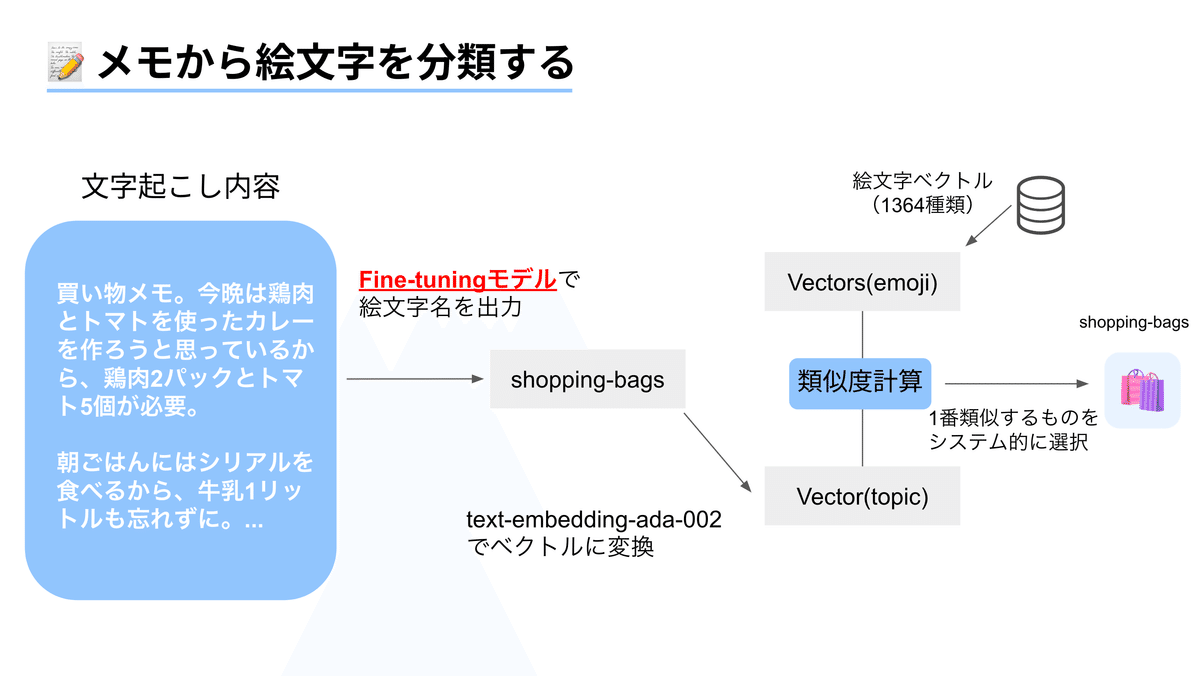
そのため、メモ内容の情報欠落が起きない形で、大部分の絵文字を選定できているため、より納得感のある分類ができているのかなと思っています!
失敗事例
systemメッセージで絵文字ラベルを学習させてみた
Twitter界隈で見る限り、systemメッセージに知識を覚えさせられるという話も見かけたため、そちらもやってみました!
あなたは与えられたメモ内容に対して、最も該当する絵文字ラベル
を分類します。絵文字ラベルは以下の中から選ばれます。
## 絵文字ラベル
{絵文字ラベルのリスト}
ただし1364種類の絵文字ラベル名は、合計で約8,000トークンほど。このgpt-3.5-turboのFine-tuningにおいても、4kトークンの制限はあるようで、エラーが出ました。
そこで絵文字ラベルを3グループ(455種類)に分けてます。
例えば、メモ内容に対して"mountain"という絵文字がラベリングされている場合は、グループ1に該当しているので、system_promptにはグループ1の絵文字ラベルリストを記載しよう!といった感じです。
ということでひとまず、n_epoch=3でやってみたのですが失敗でした😞
絵文字ラベル名ではなく、Unicode絵文字やSlackでのスタンプ形式などが出力されてしまい、期待する挙動は得られずに終わってしまいました。残念!
存在するカウント: 0
存在しないカウント: 10
グループごとの存在するカウント: {'Group 1': 0, 'Group 2': 0, 'Group 3': 0}
各ラベルの出現回数: {':clipboard:': 1, 'computer_scientist': 1, '運動': 1, '🧳': 1, ':thumbsup:': 1, '🏔️': 1, '🍽️': 1, ':books:': 1, '💪': 1, '🎉': 1}考察としては、大量の絵文字ラベルを詰め込んだため、systemメッセージの情報量が膨大となってしまったためinstruct-input-outputの関係性が掴めにくかったのかなと思ってます。
感覚としては、そのプロンプトはgpt-3.5-turboと会話する時に上手くいきそうか?みたいな判断基準が当てはまりそうな気がしています。結局モデルはプロンプトの最初と最後に注目が当たっているということなので、多すぎても理解されないみたいな。
Few-shot的な感じで、10件程度ずつ取り込んでいけばまた変わったかもしれないです。お金に余裕がないので、検証としてはここで断念です💸
Fine-tuningモデルを使ってデータセット数を増やしてみた
n_epoch=9でFine-tuningしたモデルによる絵文字ラベリングは、人間の目から見ても遜色ない(むしろ良い)形で実現できた感があります。
そこで新たにFine-tuningモデルで作った、メモと絵文字のデータセットを100件加えてみました!
もちろんメモは新たに100件を新規作成し、それを自動で絵文字ラベリングしたものを、人の目で再度見返してブラッシュアップしています。
データセット数を増やすことで、さらに精度が向上するかなと考えたのですが、結果としては残念な形に。出力結果が絵文字Unicodeとなり、絵文字ラベル名ではありませんでした。Fine-tuning失敗です😇
===epoch_3_dataset_200===
存在するカウント: 0
存在しないカウント: 100
グループごとの存在するカウント: {'Group 1': 0, 'Group 2': 0, 'Group 3': 0}
各ラベルの出現回数: {':clipboard:': 6, '💻': 3, '💪': 8, '✈️': 1, '👍': 3, '🥾': 1, '🍽️': 4, '📚': 3, '🎉': 2, '💰': 4, '📝': 3, '💡': 3, '🎁': 2, '🏆': 1, '🎨': 2, '🎾': 1, '🐶': 2, '🌱': 1, '🤝': 1, '🎙️': 2, '📈': 1, ':heart:': 2, '👨\u200d💼': 1, '🏔️': 1, '☕': 2, '🎬': 1, ':house_with_garden:': 1, '🎯': 1, '🌍': 1, ':relieved:': 2, ':earth_asia:': 1, '⏰': 1, '👗': 1, '🌿': 1, '🎵': 2, '🌅': 1, '🔧': 1, '🚗': 2, '📊': 2, '👨\u200d👩\u200d👧\u200d👦': 1, '🧘': 1, '🕹️': 1, '🎹': 1, ':shopping_bags:': 2, '🎥': 1, '👟': 1, '🥗': 1, ':email:': 1, '🚀': 1, ':potable_water:': 1, ':family_with_children:': 1, '💄': 1, '📺': 1, '🏬': 1, '⚙️': 1, ':sparkles:': 1, '💼': 1, '🌟': 1, ':moneybag:': 1, '🏠': 1}
===epoch_6_dataset_200===
存在するカウント: 0
存在しないカウント: 100
グループごとの存在するカウント: {'Group 1': 0, 'Group 2': 0, 'Group 3': 0}
各ラベルの出現回数: {'📋': 1, '🖥️': 2, '🏋️\u200d♂️': 3, '🧳': 1, '👍': 1, '🥾': 1, '🍽️': 4, '📚': 3, '💪': 5, '🏃': 1, '💰': 2, '🔧': 1, '🎨': 2, '🎁': 2, '📈': 2, '🏆': 1, '🖼️': 1, '🎾': 1, '🐶': 2, '🌱': 1, '🚩 フラグ:ラベルの提案': 1, '📅': 2, ':heart:': 2, '⭐️絵文字ラベル: 📚': 1, '👨\u200d💼': 1, '⛰️': 1, '☕': 2, 'メモを分類する絵文字ラベルは「📝」(メモ)です。': 1, '🎬': 1, '🏠': 2, '🎯 目標達成': 1, '🌍': 2, '💆\u200d♂️ (リフレッシュ)': 1, '🌟': 1, '⏰ (時計)': 1, '👕': 1, '📷': 1, '🌿': 1, '✍️ ブリーフケースとティームugg !\n\nこのメモは仕事の効率化とツールについての話題であり、特にプロジェクト管理やタスク管理のツールが注目されていると述べています。それに加えて、直感的に使いやすくチーム全体での進捗管理ができるツールや自動化や統合ができるツールの例も挙げられています。この情報から、✍️ (ペンと紙) の絵文字が最も該当する絵文字ラベルです。': 1, '🎵': 2, '🌅': 1, '🖋️': 1, '✍️': 1, '🚗': 3, '👏': 1, '👨\u200d👩\u200d👧\u200d👦': 1, '🧘': 1, '📊': 3, ':weight_lifting:': 1, '🎮': 1, '🎹': 1, '🛍️': 1, '🎥': 1, '👟': 1, '🥦': 1, '📩': 1, '🚀': 1, '⭐️': 1, '💼': 1, '🚰 (飲み物)': 1, '🌳': 1, '🔒': 1, '🧴': 1, '📺': 1, '🏬': 1, '🌟(星)': 1, '📰': 1, '📱': 1, '🧹': 1, '🛒': 1, '🎉 (パーティーポッパー)': 1, '💻': 1, '🎯': 1}完全に精度向上すると思いきや失敗したので、なんでだろうと気になり原因の切り分けをしてみました。
すると、AIでラベリングしたデータセット100件のみを利用して学習させた場合でも同様の絵文字Unicodeが出力される結果となりました。
つまり、データセット数が増えたことが問題ではなく、AIによってラベリングしたもの(数件は人の手で修正してます)を使ったことが原因で、上手くいかなかったみたいです。
これに関してはちょっと何でなのか分からないですね。今後うまくいかなかった場合の判断材料として頭の隅に置いておこうと思います。
データセットのファイル管理ミス
自分の性格上、得られた結果を見てすぐ新しい検証に手が出てしまうのですが、その結果、過去の結果が雑に保管されてしまい、自分が想定していたデータセットではないものを学習に使用していて、結果を見て「あれー!?」みたいなことがありました。。
特にデータセットもjsonlファイルで、スクリプト内で自動生成してアップロードする形にしていたので、中身をちゃんと確認せずに作ってしまっていたのもよくないですね。
ここら辺で数十ドルと1日を無駄にしてしまったので、一度立ち止まって実験管理をしっかりしたいなと思いました!
OpenAIがFine-tuning用のUIを作ってくれる予定らしいので、実験管理周りもぜひ充実してもらいたいところです…!
おわりに
今回のFine-tuningでの学びを改めて、箇条書きでまとめてみます!
Fine-tuningをすると強めに出力形式を強制してくれる。そのためFunction Callingよりも強力に形式を指定したい場合に有効そう
epoch数が多ければ品質向上するわけではなく、個々のケースにおいて最適解がありそう。OpenAIは1~2回ずつ変えながら調整してみてと言ってる
学習用データセットによってFine-tuningモデルの品質はかなり変わる。「その会話集は、通常のgpt-3.5-turboとの会話でもうまくいきそうか?」みたいな視点を持っておくと良いかもしれない
実験管理はちゃんとしよう!ファイルの中身はちゃんと確認し、ファイル名やモデル名には識別子を設定して、差分が何かをドキュメントにまとめておこう!
2日で120ドルは飛んで行きましたが、それ相応の学びはあった気がするので良しとします!💸(Fine-tuningを15回くらいしました)
この記事は、2023/8/30のLLM Application Vol.2でのLT登壇での補完記事となっています。