Whisper、ChatGPTを活用した、テキスト入力不要な新感覚メモ日記アプリの紹介と、開発における学び

日常生活の中で生まれた「できごと」や「思ったこと」を、楽しく記録できるメモ日記アプリを開発しました!
しゃべったら、あとは丸投げして良い感じにメモを残してくれる「シャべマル」です!(笑)
シャべマルの紹介
具体的には、、

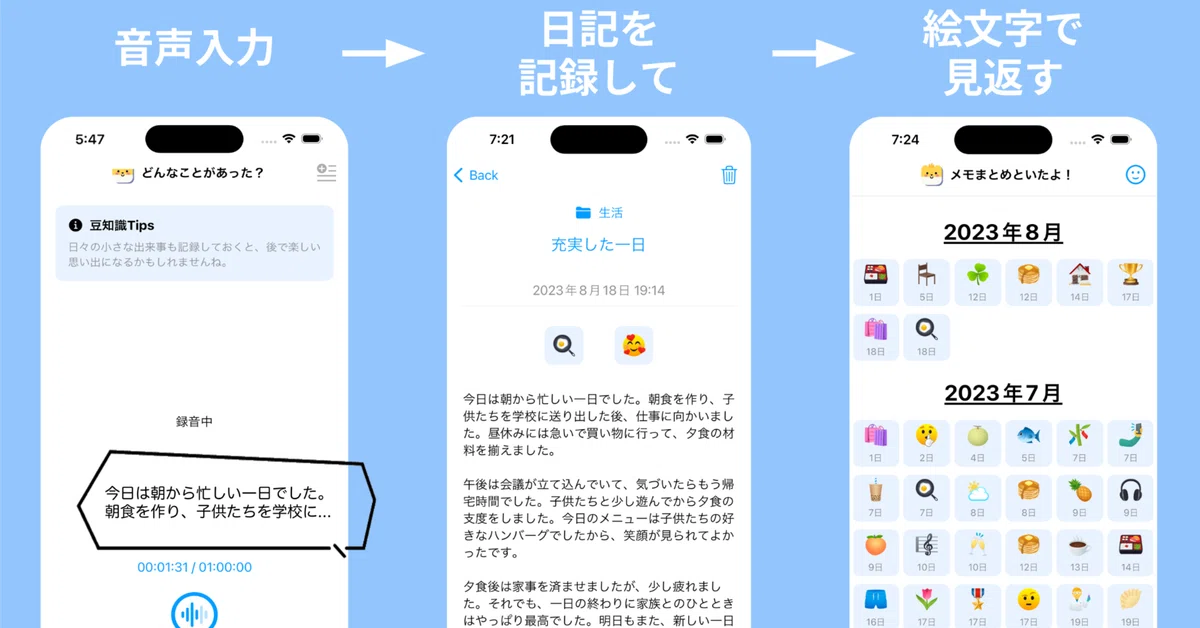
音声入力でメモ内容を作成。かなり高精度な音声認識モデル(Whisper)を用いているので、想像以上にちゃんと文字起こししてくれます!
「今日あったこと」など、日記として利用するのもオススメです。1日を振り返る機会になって、それが後から振り返りできるので、あの時こんなこと考えていたなー、といった発見につながるはずです!
そして個人的にここが目玉なのですが、文字起こしされたメモには、「タイトル」「絵文字アイコン」「感情アイコン」「カテゴリ」が自動で紐づきます!
これ何が良いかというと、圧倒的に見返しやすくなるんですよね。タイトルもそうなんですけど、個人的に絵文字で一覧を見返せると、絵文字から「あの日はあんなことあったなー」と一目で思い出せます。
あとは振り返りと言う観点で、毎月のレポート機能も作りました!メモから自動でレポート作成できるので、毎月のできごとを振り返ることができます。
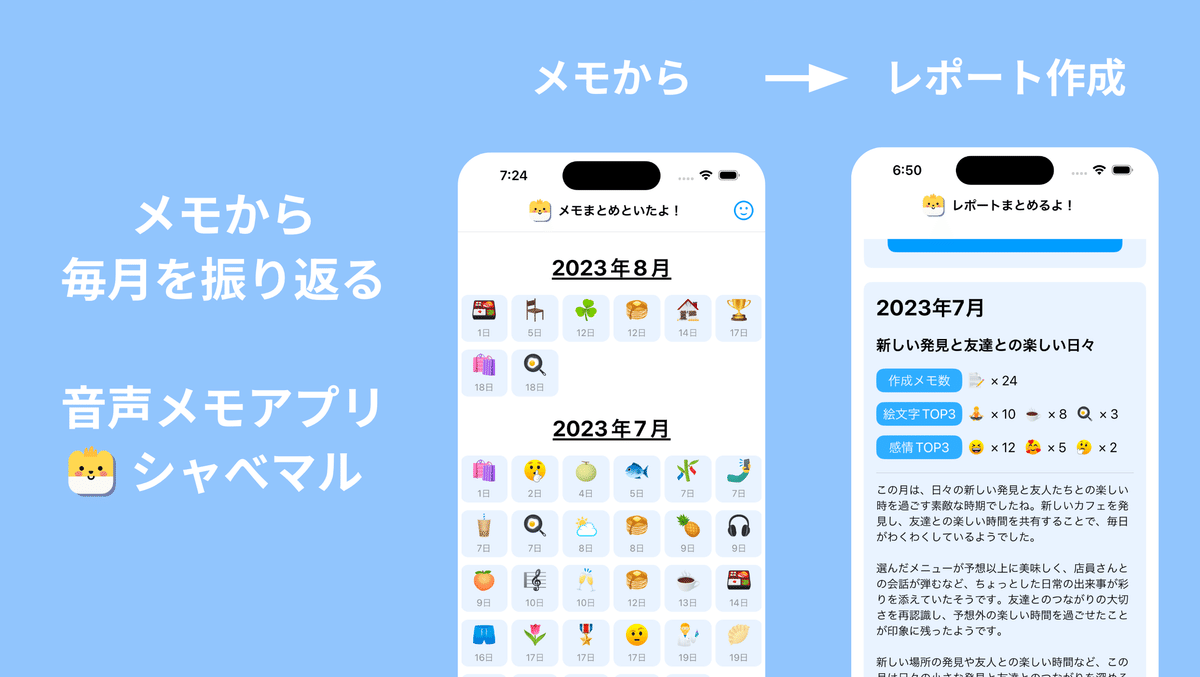
レポート作成って、多分形式的なもの(例えば、先月は感情の割合としてこれが多かったから、このレポートを表示など)が多いかなと思うんですが、シャべマルのレポートはChatGPTを用いてるので、メモ内容をベースにオリジナルの振り返り内容を作成します!
月ごとに何があったかをスクロールで見返せるの、結構良いです!
と言うわけで、シャべマルの紹介でした!ここからは企画・開発にあたっての学びを言語化していきます。
前置き
日常生活に溶け込ませるChatGPTなどの大規模言語モデル(LLM)活用を、ここ数ヶ月考えてきまして、この7,8月は音声認識メモアプリという領域で模索していました。
7月は、ideaPotというアイデアを創発する音声認識メモアプリを開発しまして、「これまでにない音声入力の手軽さ」と「自分のメモから新たなアイデアが生まれるワクワク感」を作りだすというところで、一つ可能性を拓けたかなと思っています!
ただ実際に使用してみての感想などを聞くと、アイデアというよりかは日常生活の中での記録に利用されていることが多く、自分の想定したユースケースとは異なることが多かったです。ただそれでも、
音声入力で手軽に入力できて良い
タイトルやメモのトピックスが自動生成されるのが良い感じ
といったことで利用していただいていた感じでした。
そこで今回は、アイデアよりも広く、さまざまな「こと」を見返しやすい形で、楽しく記録できるようなメモアプリを作ったら、これまた面白いのではないか!?という視点で開発に着手しました。
「見返しやすい」&「楽しく」という観点で、どこまで大規模言語モデルを活用できるかを考え抜いたアプリになります!
着目した課題感
これは実体験なのですが、メモを整理された形で残していくのって結構大変なんですよね。。。
テキスト入力にはどうしても時間がかかってしまう
既にあるページに追記してしまって、後から見つけにくい
タイトルをつけないとメモした内容が埋もれてしまう
急いで書いたために文脈が欠落して、後から読んでも思い出せない、、
それで、色々なところにメモが散らばってしまい、振り返りも全然できないというのがありました。結果、メモ習慣が継続ができないというお決まりループが自分にはあります。。
この体験を、音声認識モデル「Whisper」と大規模言語モデル「ChatGPT」を用いて、解決していこうというのが今回の主旨になります!
具体的に実現する体験
では、具体的にどうするのか?というところですが、今回取った方針は主に以下になります。
高精度な音声認識による、メモ作成の省力化
タイトル自動生成による、見返しやすさの向上
カテゴリへの自動分類による、整理されたメモ管理の実現
絵文字と感情を紐づけることで、メモ一覧を見返しやすく&楽しく
毎月のレポートを作成することで、月ごとの振り返りを簡単に
「しゃべるだけで、あとの工程はすべて良い感じにやってくれる体験」を実現することを考えました。つまり、しゃべって丸投げですね!
ここからは各機能でのこだわったポイントをまとめて行きます。エンジニア視点の内容が多めです。
✅ 高精度な音声認識による、メモ作成の省力化
OpenAI社のWhisper APIを用いているのですが、これだけで十分に高精度なんです。ただそれに加えて、いくつかこだわったポイントがあります。

句読点形式で出力してもらう
Whisper APIはデフォルトだと「今日は朝から忙しい一日でした 朝食を作り 子供達を学校に送り出した後 仕事に向かいました」みたいな文字起こしになります。
かなり読みづらいですよね。。なので句読点形式で文字起こししてもらえるように工夫しました。
具体的には、whisper APIにリクエストを送る際のパラメータに`prompt`というのがあるのですが、ここに句読点を用いた短い文章を指定します。シャべマルの場合は、「今から、メモを作成します。」と付け加えています。
Whisperのプロンプトは、出力形式を整える形で用いることができます。

プロンプト指示により誤認識の改善
合わせてプロンプトは誤認識を改善できる単語帳にもなるそうです。
シャべマルでは、「カテゴリ名」と「よく使う単語」に登録された単語を、自動的にプロンプトに盛り込むことで、誤認識の文字起こしを改善しています。
メモや日記は、特に固有名詞が多く含まれる傾向があるので、対応してみました。ChatGPT、LLMなど、新しい言葉や省略単語などにも、ある程度対応してくれる感覚があります。
改行を盛り込む
「メモの見返しやすさ」を考えた時、長文で書き起こしされたメモはかなり苦痛であることが分かりました。改行の無い長文は、結構きついです。笑
【改行なしVer.】
今日は朝から忙しい一日でした。朝食を作り、子供たちを学校に送り出した後、仕事に向かいました。昼休みには急いで買い物に行って、夕食の材料を揃えました。午後は会議が立て込んでいて、気づいたらもう帰宅時間でした。子供たちと少し遊んでから夕食の支度をしました。今日のメニューは子供たちの好きなハンバーグでしたから、笑顔が見られてよかったです。夕食後は家事を済ませましたが、少し疲れました。それでも、一日の終わりに家族とのひとときはやっぱり最高でした。明日もまた、新しい一日が始まります。頑張らなくては、と思いました。
【改行ありVer.】
今日は朝から忙しい一日でした。朝食を作り、子供たちを学校に送り出した後、仕事に向かいました。昼休みには急いで買い物に行って、夕食の材料を揃えました。
午後は会議が立て込んでいて、気づいたらもう帰宅時間でした。子供たちと少し遊んでから夕食の支度をしました。今日のメニューは子供たちの好きなハンバーグでしたから、笑顔が見られてよかったです。
夕食後は家事を済ませましたが、少し疲れました。それでも、一日の終わりに家族とのひとときはやっぱり最高でした。明日もまた、新しい一日が始まります。頑張らなくては、と思いました。
そこでシステム的に句点を判定し、前回の改行から30文字以上続いている場合は改行すると言う形で、見返しやすいメモ内容に整えています!
✅ タイトル自動生成による、見返しやすさの向上
メモ内容をリスト形式で見返す際は、タイトルがある方がメモを見つけやすいです。ただ手動でタイトル付けをするのは結構手間なので、自動化しました!

Function Callingでタイトル生成の安定化を図る
メモ内容をベースにタイトルを生成しています。gpt-3.5-turbo-16kを用いており、タイトルのみを生成してもらえるようにFunction Callingを用いています。
またここら辺やってみて分かったのですが、Function Callingは指定する関数のパラメータ名や組み合わせによっても出力結果の性質が変わる感があります。
例えば、引数に`title`ではなく、`attractiveTitle`とするとより意図を汲み取ってくれたりします。他にも`reasoning`などを加えると、理由を出力するとともに`title`の生成結果にも作用する実感値があります。(ちゃんと検証はできていないです)
出力結果の質に影響を与えると言う観点で、Function Callingのパラメータ名や組み合わせはプロンプトエンジニアリング的な要素があるなと感じます。
トークン上限を考慮した設計
gpt-3.5-turbo-16kを利用しているのは、文字起こしされた文章が長文となり、トークン上限数を超えてしまうの防ぐためです。ただ16kを超える場合もある気がしており、そこの対策を考えていました。
一旦の着地としては、10,000文字を超える場合は文章を20分割し、中間のチャンク(分割した塊)をランダムに取り除いて10,000文字以内に抑えています。
メモの場合、最初と最後に重要な箇所が多いと言うこともあり、この方式によって全体的な内容を汲み取ったタイトルを生成することができます。
✅ カテゴリへの自動分類による、整理されたメモ管理の実現
作成されたカテゴリに、自動で分類する機能です。ジャンルごとに見返したいという時もあるので、メモ内容から近いカテゴリへ自動で分類するようにしています。

ベクトル類似度による分類
カテゴリを作成する際に、カテゴリ名の埋め込み表現(ベクトル)を取得しておき、メモ内容とカテゴリのコサイン類似度を測定しています。EmbeddingにはOpenAI社の`text-embedding-ada-002`を利用しています。
メモ内容についても、もちろんEmbeddingをしているのですが、その前にgpt-3.5-turbo-16kに、メモ内容からカテゴリ名を生成してもらっています。
類似度検索をする際には、クエリとターゲットの形式を統一した方が良いという話もあり、メモ内容(長文)とカテゴリ名(主に単語)での類似度検索は精度が悪くなる懸念があったためです。この考えはHyDEと言う手法から来ています。
✅ 絵文字と感情を紐づけることで、メモ一覧を見返しやすく&楽しく
ただ単純にテキスト形式のメモを残していくだけでは、目新しさもなく楽しくもないな、という感覚があったので、他のメモアプリを参考にすると、カレンダー形式で毎日埋めていくという方式が結構主流なのが分かりました。
そこで、シャべマルでは絵文字が貯まっていく形を採用することで、より視覚的にメモが蓄積されており、またメモ内容を探しやすい形にしています。

ただし、iOSにおいて絵文字は商用利用が不可
懸念はしていましたが、絵文字は商用利用不可ということが判明しました(笑)。なので、ChatGPTが出力するようなUnicodeで表現される絵文字は利用できません。
そこで商用利用可能な絵文字素材を扱うJoyPixelsのプレミアムライセンスを購入する形で対応しました。結果的に、高品質な絵文字を色々と選択することができるようになり、よかったなと思います!(高かったですが…笑)
最近傍探索による分類
こちらも同様にベクトルによる類似度を求めようと思ったのですが、絵文字の場合は種類が多いため、類似度計算にやや時間がかかりました。
そこで絵文字に関しては、コサイン類似度ではなくユークリッド距離による最近傍探索を採用することで、処理にかかる時間を2割ほど短縮しました。
ここら辺はちょっとあまり詳しくなく、ChatGPTと試行錯誤しての着地なので、もう少しパフォーマンス改善できる余地がある気がします。
ただ一つ言えるのは、正解のない分類タスクであるため、精度よりも速度に振り切って改善に取り組める感があります。
絵文字/感情の分類精度はChatGPTで改善
カテゴリと同様に、メモ内容からFunction Callingを用いて絵文字の分類用に文字列を変換し直しています。
流れとしては、こんな感じです。
メモ内容 → メモトピック(絵文字検索用クエリ) → 類似度検索 → 最も類似する絵文字を設定
絵文字は単数・複数単語でのケバブケースでラベリングされているので、Function Callingではメモ内容から複数のtopicsを英単語で出力してもらう形をとっています。
絵文字の分類精度は「クエリの生成部分」で改善するという形で、責任範囲を切り分けることで改善のしやすさが向上した気がします。
✅ 毎月のレポートを作成することで、月ごとの振り返りを簡単に
先月分のメモからレポートを作成できるようになっています。メモ数や多かった絵文字や感情などが一目でわかるので、簡単な分析にもなります!
下部にはどんなことがあったかをメモ内容から汲み取って、一緒に振り返ることができるようなコンテンツができあがります。毎月貯まっていくと、スクロールでサクッと何があったかを見返せます!

長めのコンテンツ生成にはFunction Callingを用いない
Function Callingは一見万能な感じがしますが、割と長めの文章に関するコンテンツ生成に関しては質が落ちるなと感じてます。
なのでレポート内容に関しては、Function Callingを用いていません。ただタイトル部分の生成に関しては利用しています。
流れとしては、メモデータをインプットとして、レポート内容を生成し、そのレポート内容からさらにFunction Callingでタイトルを生成するという形をとっています。
プロンプトの作り方
これは自分流ですが、基本的にプロンプトに関しては、Few Shotを用いています。最初はGPT-4と対話しながら、良いレポート内容とはどんなか?について模索。
その上で、良いレポート内容のサンプルをいくつか作成した上で、それをプロンプトで「出力例」として用いる形です。簡素的ではありますが、素早く及第点までは目指せる感じです。
システムへの導入において「gpt-3.5-turboで実現する」ということは処理速度とコストの観点からかなり重要で、ここら辺のプロンプトエンジニアリング力をもっと身につけたいなと思っています。
おわりに
長くなってしまいましたが、シャべマル開発にあたっての学びを言語化しました!
シャべマルは、既存のメンタルモデル(今回はメモを取るという行動)の中で、大規模言語モデルだからこそ実現できる新しい体験を模索した結果になります。
OpenAI社のWhisper、ChatGPT APIを利用しているため月額500円で設定させてもらっていますが、この新感覚を試してもらいたいと思って、1ヶ月無料で利用し放題にしてます!ぜひ試してみてもらえると嬉しいです!
この記事が気に入ったらサポートをしてみませんか?