
音声合成モデルStyle-Bert-VITS2をサーバレスアーキテクチャでWeb API化する

夢が詰まっているこちらのリポジトリを、Web APIとして立てて動かすための解説記事です。
この解説記事を書くにあたって、以下の記事を大変参考にしました。ありがとうございます!ただバージョンの違いがあったのか、これだけでは動かなかったため、補足という形で本記事は情報を補うものとしています。
概要
サーバレスで動かすにあたって、今回はRunPod.ioを利用します。こちらでリクエストが来たタイミングでコンテナを立ち上げて、レスポンスを返すAPIを作ろうと思います。
また常時立ち上げているわけではないので、お金もかからなさそう。実際にどれくらいかかるかは後ほど検証しようと思います。今回はAPI化できた喜びを原動力として、立ち上げる方法についてわかりやすく解説します!
デプロイの流れとしてはこんな感じです!
1.ローカルでStyle-Bert-VITS2の環境を構築する
↓
2.Docker Hubへデプロイ
↓
3.RunPod.io上でDocker HubのイメージをプルしてAPIを立ち上げる
事前準備
まず、サクッとRunPod.ioアカウント登録とクレジット購入を済ませましょう!Google アカウントで作成できるので簡単だと思います!

Docker Hubを利用するのでアカウントを作りましょう!ローカルからloginしたり、デプロイする際にユーザー名を利用します
ローカル環境構築
まずは以下をクローンしてください。本家との差分は、RunPodにデプロイするために色々と整えています。
クローンしたらまず以下のコマンドを実行します。
cd Style-Bert-VITS2-API
chmod +x deploy.sh
python initialize.py簡単に説明すると、deploy.shファイルはローカルで構築したDockerイメージをDocker Hubにプッシュするものです。これを実行する権限をchmod +x deploy.shで付与しています。
initialize.pyを実行するとBERT関連のモデルロードが開始します。少し時間がかかると思うので、待ちましょう!
`loguru`が足りないといったエラーが出るかも知れません。 その時は、pip install loguru など実行しましょう
待っている間に一部ファイルの書き換えを行います。
deploy.sh
#!/bin/bash
USER="xxxx" <-ココを変更する
APP_NAME="runpod-style-bert-vits2-api"
VERSION=1.0.0
# VERSIONを目視で確認するのでy/Nで確認
echo "バージョンは$VERSIONでよろしいですか?"
read -p "y/N: " yn
case "$yn" in [yY]*) ;; *) echo "中止します" ; exit ;; esac
# git tag -a $VERSION -m "$VERSION"
# buildコマンド
sudo DOCKER_BUILDKIT=1 docker build --progress=plain . -f Dockerfile.runpod -t $USER/$APP_NAME:$VERSION
# pushコマンド
sudo docker push $USER/$APP_NAME:$VERSIONUSER="xxxx"にあたる部分をDocker Hubの名前に変更してください。
モデルロードとファイルの変更が完了したら、続いては以下のコマンドを実行します。
./deploy.sh$ ./deploy.sh
バージョンは��よろしいですか?
y/N:
上記のように出力されるので、yを入力します。その後、パスワードを求められるので、PCのパスワードを入力しましょう。
dea734d627e1: Layer already exists
bf2755549a90: Layer already exists
153abc56f3bb: Layer already exists
b9b3f7370d80: Layer already exists
3ec86ec070db: Layer already exists
16e9eda75b46: Layer already exists
ff4c02002f9d: Layer already exists
2b12bfc8de3b: Layer already exists
27b726dae958: Layer already exists
3a03f09d2129: Layer already exists
1.0.0: digest: sha256:b8a5280xxxxxxxx8368b38e7f7dxxxxxxx9a126b75eae98f4f187 size: 4502
このように出力されたら成功です!Docker Hubのリポジトリに{user_name}/runpod-style-bert-vits2-apiというイメージが存在しているはずです。
Docker Hubとの接続に失敗するかも知れません。その時は docker login などを実行すれば解決するかも知れません。
RunPodでの設定
続いてRunPodでの設定です。ここではDocker Hubに上がっているイメージを利用して環境を構築し、サーバレスでAPIを立てます。
まず左サイドバーのSettingsを開いて、ここでDocker Hubとの連携にあたってCredentialを作成します。
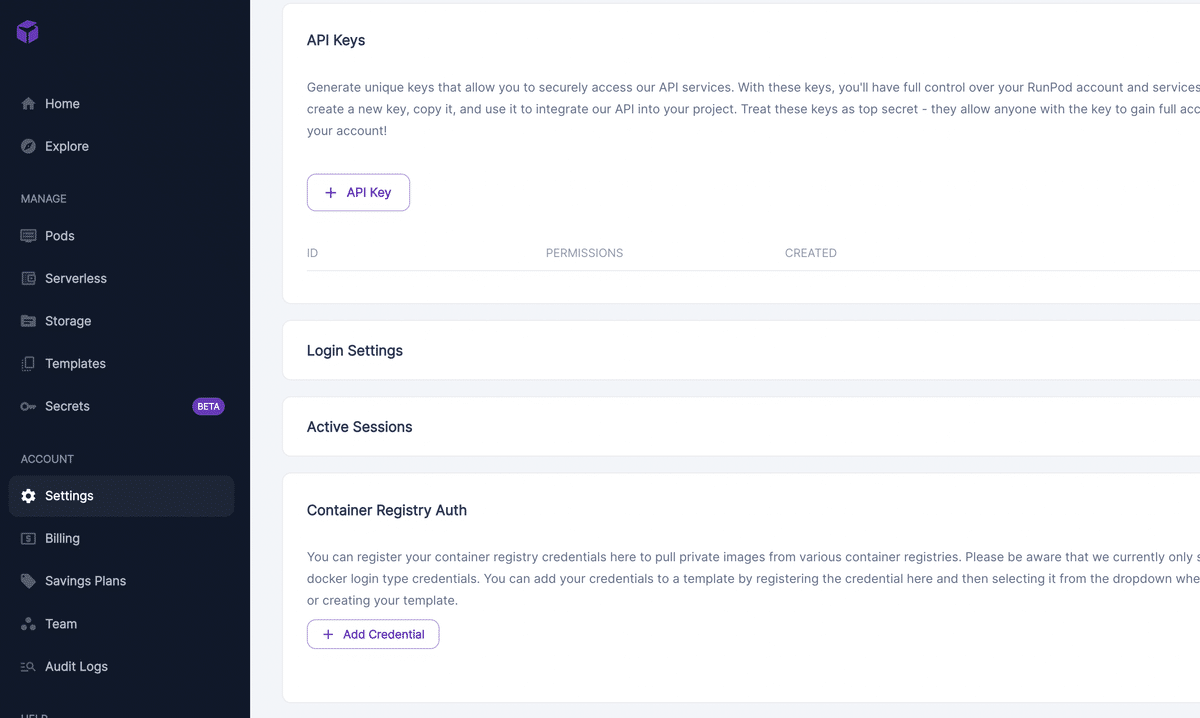
Container Registry AuthでAdd Credentialを押して、Docker Hubのログイン情報を入力します。なお、Credential Nameは識別用なので何でも構いません!
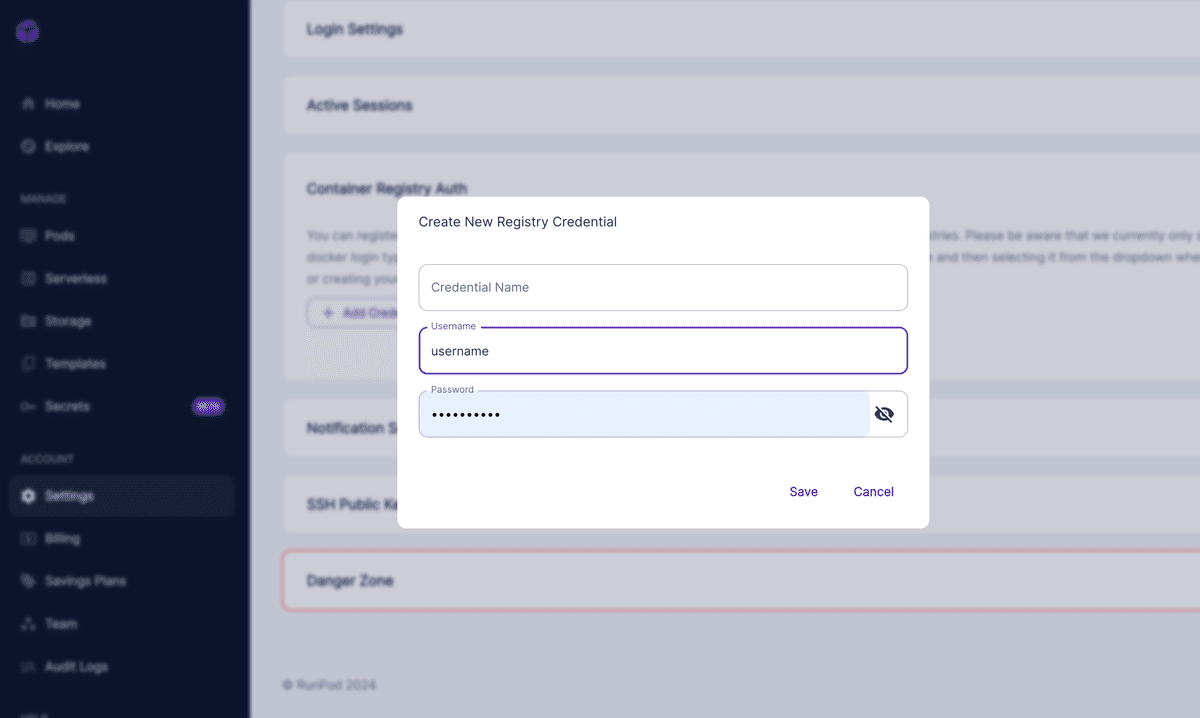
完了したら、次にTemplatesを開きます。
左上のNew Templateを押して、項目を埋めます。
Template Nameは任意
Container Imageは先ほどアップロードしたDocker Hub上のイメージを記載(タグの1.0.0も忘れずに)
Container Registry Credentialは先ほど作成したものをプルダウンから選びましょう
Container Start Commandは空白で、Container Diskは10GBとしておきます(割とモデルが大きくデフォルトの5GBだと足りないため。実際に動かすときにうまくいかない場合は、このGBを上げましょう)

Save Templateをしたらこのような感じで、新しくテンプレートが出来上がります。このテンプレートを利用して、次のステップのサーバレスでのエンドポイントを作ります。

続いてServerlessを開きます。右上が$0でないことを確認します。0の場合はBillingからチャージしてください。
問題なければNew Endpointをクリックします。

今回は安く利用したいので、16GBの1番安いやつを選びます。FlashBootも選択しておきましょう。立ち上がりが早くなるっぽいです(詳しくは知らない)
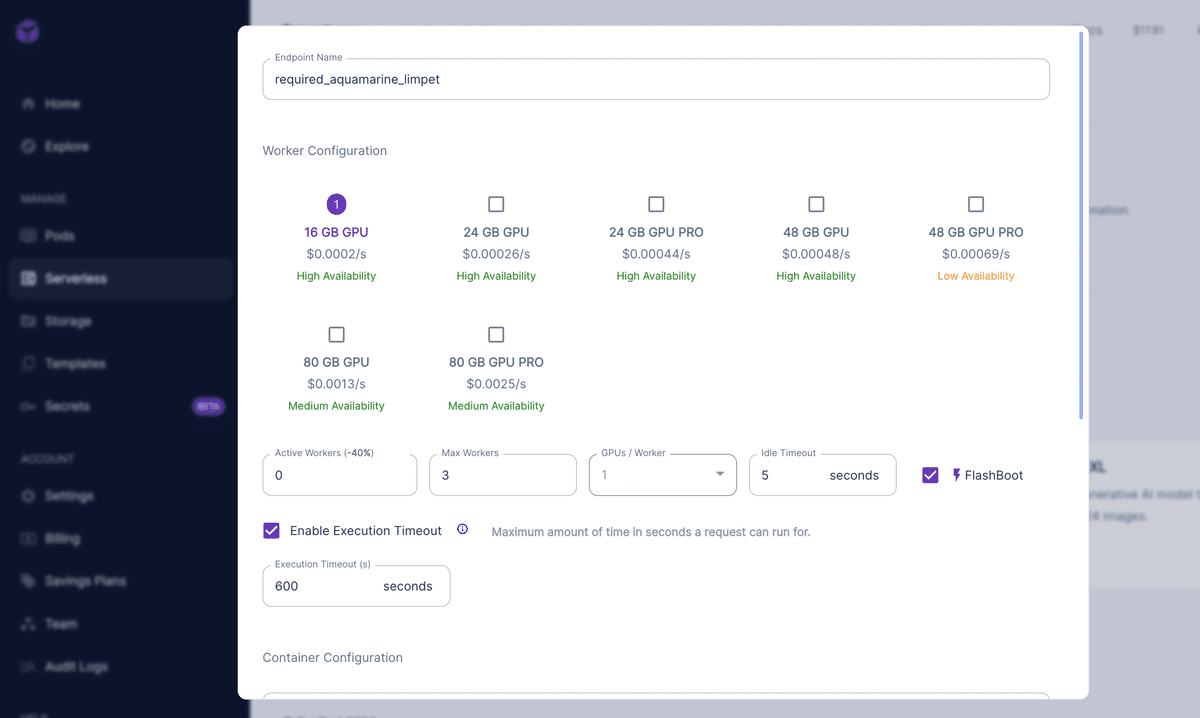
下にスクロールしていくと、Container Configurationが出てきます。ここで先ほど選択したテンプレートを選択することで該当項目を自動で埋めてくれます。

完了したらDeployを押しましょう!
このような感じでinitialize状態になるので、Readyとなるまで少し待ちます。
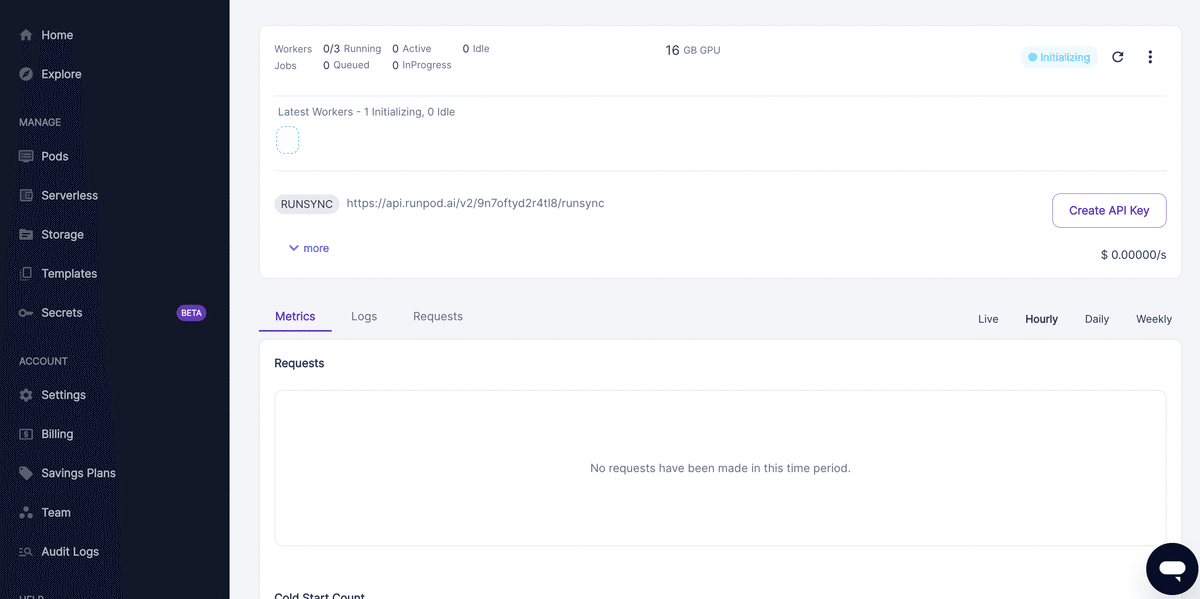
待っている間にコード側に戻ります。実際にエンドポイントを叩く用のpythonファイルを修正する必要があります。
まずEndpoint画面の`RUNSYNC`右側にあるURLをコピーします。これをcall_runpod.py のurl部分に記載します。
続いて、Create API Keyをクリックします。するとAPI Keyが発行されるので、これをコピーして、call_runpod.pyのapi_key部分に記載します。
最終的には以下のようになります。
# call_runpod.py
import base64
import json
import requests
import wave
url = "https://api.runpod.ai/v2/xxxxxxx/runsync" # urlを記載
api_key = "GFD304DOHG6PUTTS8XXXXXXXXXFLGP2Y7GYE635" # 実際のapi_keyを記載
text = "はーい、みなさーん、こちららんぽっどのAPI経由での音声です!"
file_path = "runpod_test_voice.wav"
model_id = 0
# APIから音声データを取得する関数
def fetch_audio_from_api(text):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
data = {
"input": {
"action": "/voice",
"model_id": model_id,
"text": text,
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
return response.json()["output"]["voice"]
else:
raise Exception(f"API call failed with status code {response.status_code}")
# base64エンコードされた音声データをデコードしてファイルに保存する関数
def save_audio_file(base64_data, file_path):
audio_data = base64.b64decode(base64_data)
with open(file_path, "wb") as file:
file.write(audio_data)
# wavファイルの情報をチェックする関数
def check_wav_file_info(file_path):
with wave.open(file_path, "rb") as wav_file:
print(f"Channels: {wav_file.getnchannels()}")
print(f"Sample width: {wav_file.getsampwidth()}")
print(f"Frame rate (sample rate): {wav_file.getframerate()}")
print(f"Number of frames: {wav_file.getnframes()}")
print(f"Params: {wav_file.getparams()}")
if __name__ == "__main__":
try:
# APIから音声データを取得
base64_audio = fetch_audio_from_api(text)
# ファイルに保存
save_audio_file(base64_audio, file_path)
print(f"Audio saved to {file_path}")
# wavファイルの情報をチェック
check_wav_file_info(file_path)
except Exception as e:
print(f"Error: {e}")
そうしている間に、Ready状態になりましたね!

ローカルのターミナルで、以下のコマンドを実行します。
python call_runpod.pyもし実行できない場合は、requestsライブラリが不足しているからかも知れません。pip install requestsを実行して再試行してみてください。
$ python call_runpod.py
Audio saved to runpod_test_voice.wav
Channels: 1
Sample width: 2
Frame rate (sample rate): 44100
Number of frames: 196608
Params: _wave_params(nchannels=1, sampwidth=2, framerate=44100, nframes=196608, comptype='NONE', compname='not compressed')このように出力されたら成功です!runpod_test_voice.wavというファイルが新しく作成されているので、再生して聴くことができます。
なおかかった時間は3.822秒でした。
モデルを追加したい場合
model_assets/ 配下にデフォルトで以下のようなディレクトリがあります。
model_assets
├── jvnv-F1-jp
│ ├── config.json
│ ├── jvnv-F1-jp_e160_s14000.safetensors
│ └── style_vectors.npy
├── jvnv-F2-jp
│ ├── config.json
│ ├── jvnv-F2_e166_s20000.safetensors
│ └── style_vectors.npy
├── jvnv-M1-jp
│ ├── config.json
│ ├── jvnv-M1-jp_e158_s14000.safetensors
│ └── style_vectors.npy
└── jvnv-M2-jp
├── config.json
├── jvnv-M2-jp_e159_s17000.safetensors
└── style_vectors.npyここに新しくディレクトリを作って、config.json, xxx.safetensors, style_vector.npyを追加して、再度デプロイをすることで追加することができます。
また call_runpod.py の model_id を1とかに切り替えることで、モデルの指定を変えることができます。
おわりに
この記事の「おわりに」を書き始めたところでちょうど気づいたのですが、Style-Bert-VITS2の音声合成はCPUで利用できるとのことでした…🫠(気付くのが遅いんじゃぁぁ)
RunPod.ioはGPU用のサービスなので、多分これより安くやる方法があると思いますね。AWS LambdaとかGoogle Cloud Functionsとか…
機会があったらそっちでも動かせるようにやってみたいと思います。
追記
このようなコメントをもらいました(ようさん、ありがとうございます!)
CPU推論にすると、生成速度が変わるかもということです。ちょっとRunPodの見方があんまりわからず、ちゃんとGPUリソース使われているのか確認できていないのですが、速度優先の場合はRunPod.ioという選択肢はありかも知れません!
CPUとGPUだと生成速度がかな。変わりそうだけど、つよつよCPUだったら解決できる?? https://t.co/LkcbNmZXjL
— ようさん (@ayousanz) March 30, 2024
追記2
RunPod上で見たところ、GPUリソースがちゃんと使われていたのでRunPod上で動かすほうが生成速度は速くなりそうな気配を感じます。RunPodにデプロイする意義が見つかって一安心です😮💨

一応GPUは使われていたので、 RunPod使ったほうが生成速度は速いのかも? pic.twitter.com/yjI3Z3KEad
— にょす@LLM系アプリを個人開発してます (@nyosubro0706) March 30, 2024