
Gemini Pro1.5って使えるの?

こんにちは、にゃんたです。
今回は、Googleが開発した大規模言語モデル「Gemini Pro1.5」について詳しく解説していきます。
GeminiPro 1.5は、他のモデルと比較して圧倒的に多い入力トークン数や、高い音声・画像認識性能が特徴です。この記事では、Gemini Pro1.5の強みや他社モデルとの比較、そして現在無料で利用できる点などについてお伝えします。
1. Gemini Pro1.5の圧倒的なトークン数
まずGemini Pro1.5の大きな特徴の一つが、圧倒的に多い入力可能なトークン数です。
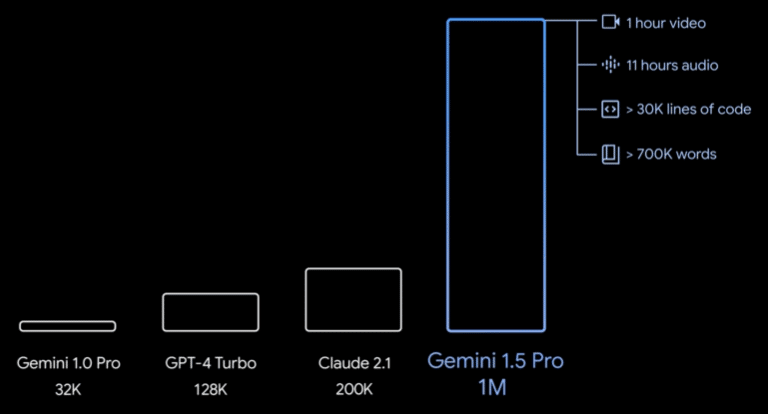
トークンとは、AIのモデルで処理されるときの文字の単位になっています。
AIのモデルでは、文字ではなくてトークンと呼ばれる単位に変換されて処理されます。
一般的に、トークン数が多いほどより多くの情報を入力でき、より複雑なタスクに対応できます。
Gemini Pro1.5は、なんと最大100万トークンまで入力可能です。これは、OpenAIのGPT-4の12.8万トークン、Anthropic社のClaude 3の20万トークンと比べて、圧倒的な数字です。
将来的には、1000万トークンまで入力できるようになる可能性もあるそうで、本当にあらゆる情報を扱えるようになるかもしれません。
2. 画像と音声認識の高い精度
Gemini Pro1.5のもう一つの大きな特徴が、画像と音声データの認識精度の高さです。
音声認識の精度については、OpenAIのWhisperやGoogleの以前のモデルであるUSMと比較して、Gemini Pro1.0でも全ての評価項目で上回っています。
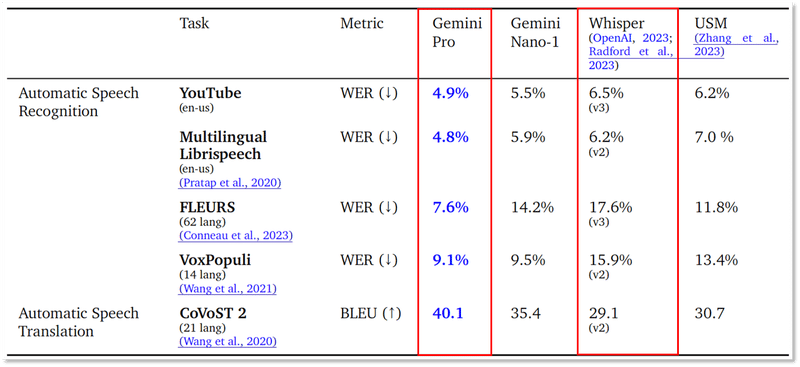
上記は、Gemini Pro1.5の前のバージョンであるGemini Pro1.0の結果ですが、既にOpenAIのWhisperより精度が高いことがわかります。
Gemini Pro1.5になってさらにパワーアップしていることを考えると、現状、音声認識分野ではGemini Pro1.5が世界最高レベルと言えるかもしれません。
また、画像認識の精度についても、OpenAIのGPT-4Vと比較して同等かそれ以上の性能を示しています。
このような高い画像・音声認識精度を活かせば、例えば動画の内容理解や、画像を伴う複雑なタスクなどにGeminiのモデルは向いていそうです。
3. 期間限定の無料利用
現時点では、Gemini Pro1.5の全ての機能を無料で利用することができます。
ただし、APIを介して利用する場合は、2023年5月2日以降は有料化されるので注意が必要です。
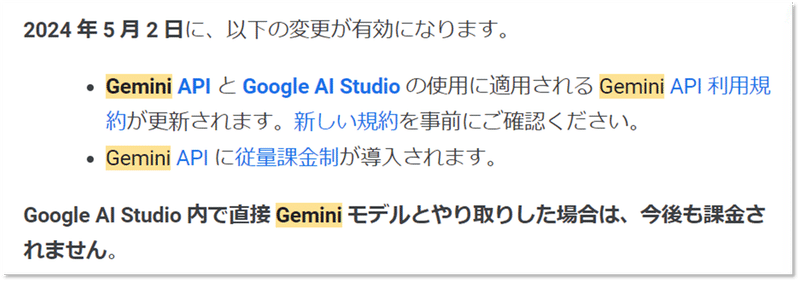
とはいえ、Google AI Studioというウェブブラウザの環境では、5月2日以降も無料で使い続けられるそうです。
このレベルの高性能なモデルが無料で使えるのは、非常にありがたいことですね。
4. 高性能なEmbeddingモデル
あまり注目されないこととして、Googleは最近、Embeddingモデルもリリースしました。Embeddingモデルは、テキストデータを数値化するために使われ、RAG(Retrieval-Augmented Generation)と呼ばれる技術の性能に大きく影響します。
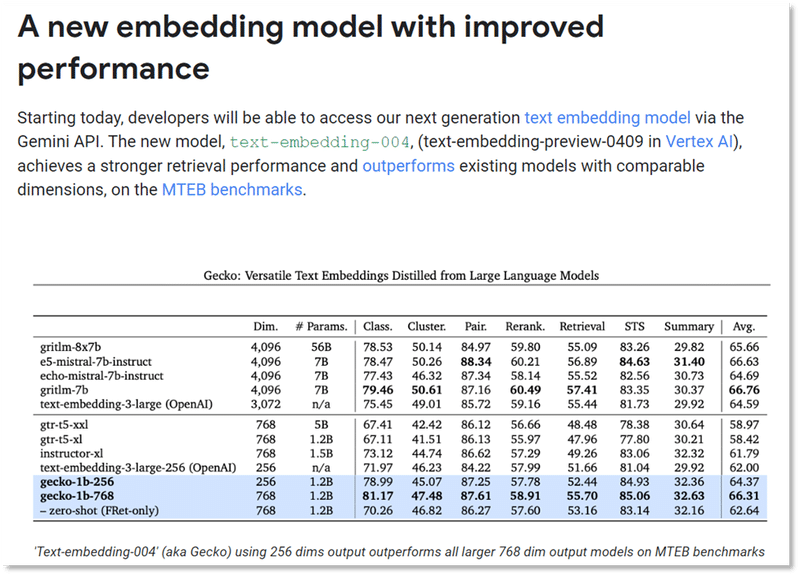
GoogleのMTEBリーダーボードを見るとEmbeddingモデルは、OpenAIの最新モデルよりも高い精度を持っています。
なので、言語処理タスクにおいては他社のモデルを使いつつ、Embeddingでは、Googleのモデルを使うという組み合わせはありかもしれません。
5. Gemini Pro1.5による高精度な文字起こし
音声認識精度がWhisperより強いモデルということで、YouTubeの動画をアップロードして、文字起こしを行ってみました。
ただ、単純に「この動画を文字起こししてください」というシンプルな指示で試してみましたが、うまくいきませんでした。(私は音声を認識できませんと返答が来ました。)
恐らく純粋なマルチモーダルなモデルではなくて、音声認識モデルと言語モデルを組み合わせているので、このような挙動になるのではないかと考えられます。
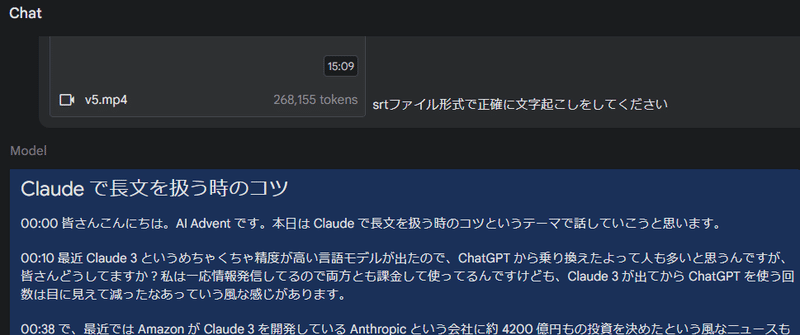
色々試してみると、「この音声をsrt形式で文字起こししてください」と指示を変えてみたところ、見事に文字起こしが完了しました。
文字起こしの精度は非常に高く、ほぼ完璧にテキスト化されていました。
さらに、複数の話者が登場する音声データでも、各話者を正しく識別し、それぞれの発言を正確に書き起こすことができました。

従来通り話者識別を行う場合、専用のAIモデルを用意する必要があります。
例えば、議事録を作成する際などに話者識別モデルは必須なのですが
Geminiを使えば1つのモデルでできるというのは中々良いのではないかと思います。
6. まとめ
GoogleのGemini Pro1.5の特徴と魅力について紹介しました。
圧倒的な入力可能トークン数(最大100万、将来的には1000万トークンの可能性も)
画像・音声認識の高い精度(特に音声認識は世界最高レベル)
現在は全ての機能が無料で利用可能(APIは5/2以降有料化)
高性能なEmbeddingモデルの存在
話者識別もできる
など、Gemini Pro1.5にはとても魅力的な特徴がたくさんあります。
大量のデータを扱うタスクや、画像・音声を含む複雑なタスクなどに挑戦したい方は、ぜひGemini Pro1.5の利用を検討してみてはいかがでしょうか。
Gemini Ultra1.5などが公開されれば、今後さらに利用シーンが広がっていくことが期待できますね。
最後まで読んでくださりありがとうございました😆
最後にLINE 公式を始めたので興味があったら見てみてください!
https://liff.line.me/2004040861-3Jvq4bAG
ChatGPT, Claude3のプロンプトテクをまとめたプレゼントを無料で配布中です!(キーワード「プロンプト」と入力してください)
この記事が気に入ったらサポートをしてみませんか?