
NVIDIA CEO Jensen Huang Keynote at COMPUTEX 2024(2024/6/2)(日本語翻訳)

私は皆さんに中国語で話したいのですが、話したいことがたくさんありすぎて、中国語で話すのは大変です。ですから、英語で話させていただきます。
皆さんが目にしたすべての基盤には、2つの基本技術があります。それは加速コンピューティングと人工知能です。この2つの技術、この2つの基本的な力はコンピュータ業界を再構築するでしょう。

コンピュータ業界は現在およそ60年の歴史があります。多くの点で、今日私たちが行っているすべてのことは、1964年に私が生まれた翌年に発明されたものです。IBMのシステム360は中央処理装置、汎用コンピューティング、オペレーティングシステムを通じたハードウェアとソフトウェアの分離、マルチタスク、I/Oサブシステム、DMAなど、今日使用しているさまざまな技術、アーキテクチャ互換性、後方互換性、ファミリー互換性を導入しました。今日私たちが知っているコンピューティングに関するすべてのことは、1964年に大部分が説明されました。
もちろん、PC革命はコンピューティングを民主化し、すべての人々の手に届けました。そして2007年、iPhoneはモバイルコンピューティングを導入し、コンピュータを私たちのポケットに入れました。それ以来、すべてが接続され、モバイルクラウドを通じて常に稼働しています。この60年間で、実際にはあまり多くない、2〜3回の主要な技術シフト、コンピューティングの2〜3回のテクトニックシフトが見られました。そして今、再びそのような変化を目撃しようとしています。
現在、2つの基本的な変化が起きています。

まず1つ目は、コンピュータ業界を駆動するエンジンである中央処理装置、プロセッサの性能スケーリングが大幅に遅くなっている一方で、私たちが行うべき計算の量は急速に増加し続けています。もし処理要件、処理すべきデータが指数関数的に増加し続ける一方で、性能が追いつかない場合、私たちは計算インフレーションを経験することになるでしょう。そして実際、私たちは現在、その現象を目の当たりにしています。世界中で使用されるデータセンターの電力消費量は大幅に増加しています。コンピューティングのコストも増加しています。計算インフレーションが進行しています。これは続けることはできません。データは指数関数的に増加し続け、CPUの性能スケーリングは決して戻らないでしょう。より良い方法があります。
約20年間、私たちは加速コンピューティングに取り組んできました。CUDAはCPUを補完し、専門的なプロセッサが非常に効率的に処理できる作業をオフロードして加速します。実際、その性能は非常に優れているため、CPUのスケーリングが遅くなり、ほぼ停止している今、すべてを加速すべきであることが明らかです。私は、処理集約型のすべてのアプリケーションが加速されると予測しています。そして間違いなく、近い将来、すべてのデータセンターが加速されるでしょう。
加速コンピューティングは非常に合理的です。あるアプリケーションを見ると、ここでは100Tが100時間単位の時間を意味します。それは100秒かもしれませんし、100時間かもしれません。そして多くの場合、皆さんが知っているように、私たちは現在、100日間動作する人工知能アプリケーションに取り組んでいます。1Tは逐次処理が必要なコードであり、シングルスレッドのCPUが非常に重要です。オペレーティングシステムや制御ロジックなど、1つの命令が次の命令の後に実行されることが本当に重要です。しかし、多くのアルゴリズムがあります。コンピュータグラフィックスもその1つであり、完全に並列に操作することができます。コンピュータグラフィックス、画像処理、物理シミュレーション、組合せ最適化、グラフ処理、データベース処理、そしてもちろん非常に有名なディープラーニングの線形代数などです。並列処理によって加速が可能なアルゴリズムはたくさんあります。

そこで私たちはそれを実現するアーキテクチャを発明しました。GPUをCPUに追加することで、専門的なプロセッサは膨大な時間を要する作業を非常に高速に処理できます。2つのプロセッサが並行して動作することができるため、処理時間を100単位の時間から1単位の時間に加速できます。このスピードアップは驚異的で、ほとんど信じられないほどです。しかし今日、私は多くの例を示します。この恩恵は非常に大きいです。100倍のスピードアップですが、消費電力は3倍程度増加するだけで、コストは約50%しか増加しません。PC業界では常にこれを行っています。$1,000のPCに$500のGeForce GPUを追加すると、性能が大幅に向上します。データセンターでも同様です。10億ドルのデータセンターに5億ドル相当のGPUを追加すると、突然AI工場になります。これは今日、世界中で起こっています。

節約効果は非常に大きいです。1ドルあたりの性能が60倍向上します。100倍のスピードアップで、消費電力は3倍しか増加しません。100倍のスピードアップで、コストは1.5倍しか増加しません。節約効果は驚異的です。この節約効果はドルで測定されます。多くの企業がクラウドでデータを処理するために数億ドルを費やしていることは明らかです。それが加速されれば、数億ドルの節約が可能です。それは非常に明白な理由です。一般目的のコンピューティングで長い間、インフレーションを経験してきました。今、私たちはついに加速する決意をしたため、大量の浪費を回収することができます。これにより、節約が実現し、エネルギーの節約、そしてお金の節約が実現します。これが、私が「買えば買うほど節約になる」と言っている理由です。
(観客の笑いと拍手)
そして今、その数学をお見せしました。それは正確ではありませんが、正しいです。これはCEOの数学と呼ばれます。CEOの数学は正確ではありませんが、正しいです。買えば買うほど節約になるのです。
加速コンピューティングは驚異的な結果をもたらしますが、それは簡単ではありません。なぜそれが多くのお金を節約するのに、長い間誰もそれを実行しなかったのでしょうか?それは非常に困難だからです。ソフトウェアを単にCコンパイラを通して実行し、突然そのアプリケーションが100倍速くなるようなことはありません。それは論理的ではありません。そのようなことが可能であれば、単にCPUを変更して実行すればよいのです。実際には、ソフトウェアを完全に書き直す必要があります。これが難しい部分です。ソフトウェアは完全に書き直され、アルゴリズムを再構築し、CPU上で書かれたアルゴリズムを再表現し、加速され、並列処理で実行されるようにする必要があります。このコンピュータサイエンスの作業は非常に困難です。

私たちは過去20年間、この作業を世界にとって容易にしました。もちろん、非常に有名なCUDNNはニューラルネットワークを処理するディープラーニングライブラリです。私たちは流体力学や他の多くのアプリケーションに使用できるAI物理ライブラリを持っています。これにより、ニューラルネットワークが物理法則に従う必要があります。また、CUDA加速された5G無線のための新しいライブラリであるARILもあります。これにより、私たちは世界のネットワーキングインターネットをソフトウェア定義し、加速できるようになります。そして、この加速のおかげで、すべての通信を本質的に同じプラットフォーム、つまりクラウドのようなコンピューティングプラットフォームに変えることができます。
CUDLithoは計算リソグラフィプラットフォームであり、チップ製造の最も計算集約的な部分であるマスクの製造を処理します。TSMCは現在、CUDLithoを使用して生産に移行しており、膨大なエネルギーとコストを節約しています。TSMCの目標は、スタックを加速し、アルゴリズムのさらなる進歩とより深く、より細かいトランジスタに備えることです。
Parabricksは遺伝子配列解析ライブラリであり、世界で最高のスループットを持つライブラリです。QoOptは組合せ最適化、ルート計画の最適化、旅行セールスマン問題など、非常に複雑な問題に対して驚異的なライブラリです。多くの科学者は、これを解決するには量子コンピュータが必要だと結論づけていました。私たちは加速コンピューティングで稲妻のように速いアルゴリズムを作成しました。23の世界記録を持っています。今日、私たちはすべての主要な世界記録を保持しています。
QoOpt Quantumは量子コンピュータのエミュレーションシステムです。量子コンピュータを設計するためには、シミュレータが必要です。量子アルゴリズムを設計するためには、量子エミュレータが必要です。量子コンピュータが存在しないときにどのようにそれを行いますか?今日存在する最速のコンピュータを使用します。もちろん、NVIDIA CUDAと呼びます。そして、その上で私たちは量子コンピュータをシミュレートするエミュレータを持っています。これは世界中の数十万人の研究者によって使用されています。すべての主要な量子コンピューティングフレームワークに統合され、世界中の科学的スーパーコンピューティングセンターで使用されています。
CUDFはデータ処理のための驚異的なライブラリです。データ処理は今日のクラウド支出の大部分を占めています。すべて加速されるべきです。CUDFは世界で使用されている主要なライブラリを加速します。多くの皆さんが企業で使用しているSpark。新しいものとしてPolar。もちろん、NetworkXも、グラフ処理データベースライブラリです。
これらはほんの一例です。他にもたくさんあります。これらのライブラリの1つ1つが、加速コンピューティングのエコシステムを活用するために作成されました。CUDNNを作成しなかったら、CUDAだけでは世界中のディープラーニング科学者が利用できるようにはなりませんでした。CUDAとTensorFlowやPyTorchで使用されるアルゴリズムの間の隔たりは非常に大きいです。それはまるで、OpenGLなしでコンピュータグラフィックスを行うようなものです。それはSQLなしでデータ処理を行うようなものです。これらのドメイン固有のライブラリは私たちの会社の宝物です。350ものライブラリがあります。これらのライブラリがあってこそ、私たちは多くの市場を開拓することができました。

いくつかの例をお見せします。先週、GoogleはCUDFをクラウドに導入し、Pandasを加速しました。Pandasは世界で最も人気のあるデータサイエンスライブラリです。多くの皆さんがすでにPandasを使用しているでしょう。世界中の1000万人のデータサイエンティストが使用し、毎月1億7000万回ダウンロードされています。それはデータサイエンティストのためのスプレッドシートであり、Excelのような存在です。今やワンクリックで、GoogleのクラウドデータセンタープラットフォームであるColabでPandasを使用できるようになりました。CUDFで加速されます。速度の向上は本当に驚異的です。見てみましょう。

素晴らしいデモでしたね。長くはかかりませんでしたね。データ処理をこれほど速く加速すると、デモは長くかかりません。

CUDAは今やティッピングポイントに達しましたが、それ以上のものです。CUDAは今や好循環を達成しました。これは非常に珍しいことです。歴史を振り返ると、すべてのコンピューティングアーキテクチャ、コンピューティングプラットフォームにおいて、マイクロプロセッサ、CPUの例では、60年間存在し続けています。このレベル、この方法でのコンピューティングは60年間変更されていません。このような新しいプラットフォームを作成することは非常に難しいです。それは鶏と卵の問題だからです。もしあなたのプラットフォームを使用する開発者がいなければ、当然ユーザーもいません。しかしユーザーがいなければ、インストールベースもありません。インストールベースがなければ、開発者は興味を持ちません。開発者は大規模なインストールベースのためにソフトウェアを書きたいと思っていますが、大規模なインストールベースは多くのアプリケーションが必要です。ユーザーがそのインストールベースを作成するためです。この鶏と卵の問題はほとんど破られたことがありません。私たちは今、20年間かけて、1つのドメインライブラリから次のライブラリ、1つの加速ライブラリから次のライブラリへと進んできました。そして今や、世界中に500万人の開発者がいます。私たちはあらゆる産業を対象にしています。ヘルスケア、金融サービス、もちろんコンピュータ産業、自動車産業、世界中のほぼすべての主要産業、ほぼすべての科学分野です。私たちのアーキテクチャの顧客が非常に多いため、OEMやクラウドサービスプロバイダーが私たちのシステムを構築することに興味を持っています。台湾のような素晴らしいシステムメーカーが私たちのシステムを構築することに興味を持っており、それが市場により多くのシステムを提供し、私たちにとってより大きな機会を生み出します。これにより、私たちの規模、R&Dの規模が拡大し、アプリケーションの速度がさらに向上します。アプリケーションの速度を向上させるたびに、コンピューティングのコストが下がります。
これは以前お見せしたスライドです。100倍のスピードアップは97%、96%、98%の節約につながります。そして100倍のスピードアップから200倍、1000倍のスピードアップに進むと、節約が続きます。コンピューティングの限界コストが低下し続けます。私たちはコンピューティングのコストを驚くほど下げることで、市場、開発者、科学者、発明者がますます多くのアルゴリズムを発見し、ますます多くのコンピューティングを消費することを期待しています。そしてある日、あることが起こり、フェーズシフトが起こり、コンピューティングの限界コストが非常に低くなると、新しいコンピュータの使用方法が出現します。実際、それが今目にしているものです。
過去10年間で、特定のアルゴリズムでコンピューティングの限界コストを100万倍低下させました。その結果、今ではインターネット上のすべてのデータを使って大規模な言語モデルを訓練することが非常に論理的で常識的なことになりました。誰もが当然のことと考えています。このアイデアは、非常に多くのデータを処理できるコンピュータを作成し、そのコンピュータが自らソフトウェアを書くことができるというもので、人工知能の出現は、コンピューティングのコストを安くし続ければ誰かが素晴らしい使い道を見つけるという完全な信念によって可能になりました。
今日はCUDAが好循環を達成したことをお見せしました。インストールベースが増え、コンピューティングコストが下がり、それがより多くの開発者に新しいアイデアを生み出させ、それがさらに需要を生み出しています。そして今、非常に重要な何かの始まりにいるのです。しかし、その前に、CUDAを作成し、現代の生成AI、生成的AIのビッグバンを作成しなければ不可能だったことをお見せします。これがEarth 2です。

地球のデジタルツインを作成し、地球をシミュレートして、災害を避けたり、気候変動の影響をよりよく理解して適応したりするために、地球の未来を予測するというアイデアです。私たちの習慣を変えるために、地球のデジタルツインはおそらく、世界で最も野心的なプロジェクトの1つです。そして毎年大きな進展を遂げており、毎年その結果をお見せします。今年も大きなブレークスルーを達成しました。見てみましょう。


(月曜日に嵐が再び北上し、台湾に接近するでしょう。進路には大きな不確実性があり、異なる進路が台湾に異なるレベルの影響を与えます。)
(観客の拍手)
近い将来、地球上のすべての平方キロメートルで継続的な気象予測が行われるでしょう。気候がどうなるか常に知ることができます。常に知ることができるのです。そしてこのAIは非常に少ないエネルギーで動作するため、この成果は非常に素晴らしいです。楽しんでいただけたでしょうか。非常に重要なことですが、(中国語で)真実は、あれはジェンセンAIでした。私ではありませんでした。(観客の笑い)
私が書いたものですが、AI、ジェンセンAIが話しました。

(中国語で)私たちの目標は性能を向上させ、コストを下げることに常に取り組んできました。研究者たちは2012年にCUDAを発見しました。これはNVIDIAがAIと初めて接触した重要な日でした。私たちは賢明にも、ディープラーニングを可能にするために科学者と協力しました。そしてAlexNetはもちろん、コンピュータビジョンの大きな突破口を達成しました。しかし、最大の賢明さは、ディープラーニングの背景、基盤、長期的な影響、潜在的な可能性を理解するために一歩下がることでした。この技術はスケールする大きな可能性を持っていることを理解しました。データの増加、大規模なネットワーク、そして非常に重要なことに、はるかに多くの計算能力によって、ディープラーニングは人間のアルゴリズムが達成できなかったことを達成できるようになりました。では、アーキテクチャをさらにスケールアップし、より大規模なネットワーク、より多くのデータ、より多くの計算能力を持ったらどうなるでしょうか?
私たちはすべてを再発明することに専念しました。2012年以降、私たちはGPUのアーキテクチャを変更し、Tensorコアを追加しました。NVLinkを発明しました。これが10年前のことです。私たちはCUDNN、TensorRT、NICLを発明し、Mellanox、TensorRT-LM、Triton推論サーバーを買収しました。そしてこれらすべてが新しいコンピュータに統合されましたが、誰も理解しませんでした。誰もそれを望んでいませんでした。

しかしOpenAI、サンフランシスコの小さな会社がそれを見て、私に1つ届けてくれと頼みました。私は2016年に世界初のAIスーパーコンピュータDGXをOpenAIに届けました。
その後、私たちはさらにスケールアップを続けました。1台のAIスーパーコンピュータから大規模なスーパーコンピュータにスケールアップしました。2017年には、膨大なデータを訓練し、長期間にわたるシーケンシャルなパターンを認識し、学習することができるトランスフォーマーが発見されました。これにより、大規模な言語モデルを訓練し、自然言語理解において突破口を達成することが可能になりました。その後もさらに大規模なモデルを構築し続けました。そして2022年11月、NVIDIAの数万台のGPUと非常に大規模なAIスーパーコンピュータで訓練されたOpenAIがChatGPTを発表しました。
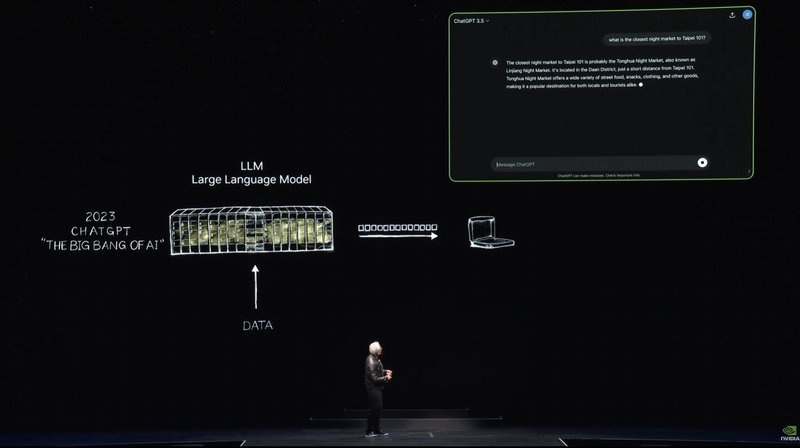
5日で100万人のユーザーが集まり、2か月で1億人に達しました。史上最も急成長したアプリケーションです。その理由は非常に簡単です。それは非常に使いやすく、魔法のように感じられるからです。コンピュータと人間のように対話できることです。明確に何を求めるかを言う代わりに、コンピュータがあなたの意味を理解し、意図を理解するのです。
ここで、私にとって非常に重要なスライドをお見せします。このスライドとこのスライドの根本的な違いはこれです。ChatGPTが世界に公開されるまで、AIはすべて認識に関するものでした。自然言語理解、コンピュータビジョン、音声認識です。それはすべて認識と検出に関するものでした。これが世界が生成AIを初めて目にした瞬間です。それはトークンを生成し、それらのトークンは言葉でした。いくつかのトークンは画像やチャート、表、歌、言葉、音声、ビデオなどになることができます。それらのトークンは何でも構いません。意味を学習できるものなら何でもです。化学物質のトークン、タンパク質、遺伝子のトークンでも構いません。先ほどEarth 2で見たように、天気のトークンを生成していました。物理学を学習できます。もし物理学を学習できるなら、AIモデルに物理学を教えることができます。AIモデルは物理学の意味を学び、それを生成できます。1キロメートルの範囲までスケールダウンする際にフィルタリングを使用せず、生成するのです。この方法を使用してほぼ何でも生成できます。価値のあるものは何でもです。車のステアリングコントロールを生成できます。ロボットアームの動作を生成できます。学習できるものは何でも生成できます。私たちは今、AIの時代ではなく、生成AIの時代に突入しました。しかし、重要なのはこれです。このコンピュータはスーパーコンピュータとして始まりましたが、今やデータセンターに進化し、1つのことを生産します。それはトークンです。AIファクトリーです。このAIファクトリーは価値のある新しい商品を生成し、生産し、作り出しています。

1890年代後半、ニコラ・テスラはACジェネレーターを発明しました。私たちはAIジェネレーターを発明しました。ACジェネレーターは電子を生成しました。NVIDIAのAIジェネレーターはトークンを生成します。これらのものはどちらも非常に大きな市場機会を持っています。ほぼすべての産業で完全に交換可能です。これは新しい産業革命です。私たちは今、新しい商品を生産する新しい工場を持っており、非常に価値のあるもので、すべての産業にとって非常に重要です。この方法論は非常にスケーラブルで、非常に再現可能です。新しいAIモデルが毎日のように発明されています。すべての産業が参加しています。
初めて、IT産業が3兆ドルの規模を持ち、100兆ドルの産業に直接サービスを提供できるものを創造しています。もはや情報の保存やデータ処理のための道具ではなく、すべての産業のための知識を生成する工場です。これは製造業です。コンピュータを製造する産業ではなく、製造業でコンピュータを使用する産業です。これはこれまでにないことです。加速コンピューティングから始まり、AIに至り、生成AIに至り、今や産業革命に至っています。

私たちの産業に与える影響も非常に大きいです。もちろん、多くの産業に新しい商品、トークンを提供できますが、私たち自身の産業への影響も非常に大きいです。初めて、60年間でコンピューティングのすべての層が変わりました。CPU、汎用コンピューティングから加速GPUコンピューティングに至り、コンピュータが命令を必要とし、今ではコンピュータがLLM、大規模言語モデル、AIモデルを処理します。過去のコンピューティングモデルは情報の取得に基づいていましたが、今後はできるだけ生成し、必要な情報だけを取得するようになります。生成されたデータは情報を取得するのに比べてエネルギーをあまり必要としません。生成されたデータは文脈に関連性があり、知識をエンコードし、あなたの理解をエンコードします。そして「その情報を取得してくれ」ではなく、「答えを求める」だけです。コンピュータが道具ではなく、スキルを生成するものになります。タスクを実行するのです。
産業も変わります。以前はソフトウェアを作成していた産業がありましたが、それは革命的なアイデアでした。Microsoftがソフトウェアをパッケージ化してPC産業を革新しました。パッケージソフトウェアがなければ、PCを何に使うか分からなかったでしょう。それがこの産業を駆動し、今や新しい工場、新しいコンピュータがあります。この上で動作する新しい種類のソフトウェアがあります。それをNIMS(NVIDIA Inference Microservices)と呼びます。

NIMはこの工場の中で動作し、事前に訓練されたモデルです。それはAIです。このAIは非常に複雑ですが、AIを動作させるコンピューティングスタックも非常に複雑です。ChatGPTを使用すると、その背後には膨大なソフトウェアが存在します。プロンプトの下には膨大なソフトウェアがあり、非常に大きなモデルがあり、何十億、何兆のパラメータがあります。それは1台のコンピュータだけで動作するものではありません。複数のコンピュータで動作し、複数のGPUにワークロードを分散する必要があります。テンソル並列処理、パイプライン並列処理、データ並列処理、専門家並列処理など、あらゆる種類の並列処理が必要です。これにより、ワークロードを複数のGPUに分散し、できるだけ早く処理する必要があります。工場を運営している場合、スループットは収益に直接関係します。スループットはサービスの品質に直接関係し、スループットはあなたのサービスを使用できる人々の数に直接関係します。
私たちは今、データセンターのスループット利用が非常に重要な世界にいます。過去には重要でしたが、現在は非常に重要です。過去には測定されませんでしたが、今日ではすべてのパラメータが測定されます。開始時間、稼働時間、利用率、スループット、アイドルタイムなど、すべてが測定されます。工場の場合、運営が企業の財務パフォーマンスに直接関係するためです。私たちはこの複雑さが多くの企業にとって非常に困難であることを理解しています。そこで私たちはAI in a boxを作成しました。

このボックスには膨大なソフトウェアが含まれています。このコンテナにはCUDA、CUDNN、TensorRT、推論サービスのためのTritonが含まれています。クラウドネイティブであり、Kubernetes環境で自動スケーリングできます。AIを監視するための管理サービスとフックが含まれています。標準的なAPIがあり、このボックスとチャットすることができます。CUDAがコンピュータにインストールされていれば、もちろんどこにでもあります。クラウドのすべてにあります。すべてのコンピュータメーカーから利用できます。何億ものPCにインストールされています。このNIMをダウンロードすると、AIがあり、ChatGPTのようにチャットできます。すべてのソフトウェアが統合されています。400の依存関係がすべて1つに統合されています。クラウドにある私たちの全インストールベースに対して、すべてのNIM、事前訓練されたモデルをテストしました。すべてのバージョンに対してです。PascalやAmpere、Hopperなど、さまざまなバージョンがあります。いくつかは忘れてしまいました。

NIMSは驚異的な発明です。これが私のお気に入りの1つです。そしてもちろん、私たちは今や大規模言語モデルやさまざまな種類の事前訓練モデルを作成する能力を持っています。これらのさまざまなバージョンがあります。言語ベース、ビジョンベース、イメージングベースなどです。ヘルスケア、デジタルバイオロジーのためのバージョンがあります。デジタルヒューマンのバージョンもあります。そしてその使い方は、ai.nvidia.comにアクセスするだけです。

今日、Hugging Faceに最適化されたLama 3 NIMを公開しました。無料で試すことができます。クラウドで実行したり、クラウドにダウンロードしたりできます。このコンテナをダウンロードし、データセンターに配置して、顧客に提供できます。
先ほど述べたように、さまざまなドメインがあります。物理、セマンティック検索のためのREG、ビジョン言語などです。これらのマイクロサービスを大規模なアプリケーションに接続する方法です。

今後重要なアプリケーションの1つは顧客サービスエージェントです。顧客サービスエージェントはほぼすべての産業で必要です。世界中で何兆ドルもの顧客サービスが存在します。看護師もある意味で顧客サービスエージェントです。一部は非処方箋または非診断ベースの看護師です。小売、クイックサービスフード、金融サービス、保険などの顧客サービスが何千万人も存在し、言語モデルやAIによって強化できます。これらのボックスは基本的にNIMSです。いくつかのNIMSは推論エージェントです。タスクを与えられた場合、ミッションを理解し、計画を立てます。いくつかのNIMSは情報を取得します。いくつかのNIMSは検索を行います。いくつかのNIMSはCOOPのようなツールを使用するかもしれません。SAP上で動作するツールを使用するかもしれません。特定の言語、ABAPを学習する必要があるかもしれません。いくつかのNIMSはSQLクエリを実行する必要があるかもしれません。これらのNIMSはすべて専門家であり、チームとして組み立てられます。では、何が起こっているのでしょうか?アプリケーション層が変更されています。以前は命令で書かれたアプリケーションが、今ではチームを組み立てるアプリケーションになっています。
プログラムを書く方法を知っている人はほとんどいませんが、問題を分解しチームを組み立てる方法を知っている人はほとんどです。将来的には、すべての会社が大規模なNIMSのコレクションを持ち、専門家を呼び出し、チームとして組み立てることになります。具体的にどう組み立てるかを考える必要もありません。エージェント、NIMにミッションを与え、タスクを分解して誰に渡すかを決定します。アプリケーションのリーダー、チームのリーダーがタスクを分解し、チームメンバーに指示を与えます。チームメンバーがタスクを実行し、リーダーに戻します。リーダーはそれを推論し、情報を提供します。これは私たちの近い将来に起こることです。これがアプリケーションの姿です。
もちろん、これらの大規模なAIサービスとテキストプロンプトや音声プロンプトで対話できます。しかし、他の方法でも対話したいアプリケーションがたくさんあります。人間のような形で対話できる方法です。私たちはこれをデジタルヒューマンと呼びます。NVIDIAは長い間、デジタルヒューマン技術に取り組んできました。お見せしましょう。

台湾にいるのは素晴らしいことです。ナイトマーケットに行く前に、デジタルヒューマンのエキサイティングなフロンティアを見てみましょう。未来にはコンピュータが人間のように対話できる世界を想像してみてください。

こんにちは、私はソフィーです。Youneetのデジタルヒューマンブランドアンバサダーです。これがデジタルヒューマンの驚異的な現実です。デジタルヒューマンは顧客サービスから広告、ゲームに至るまで業界を革新します。デジタルヒューマンの可能性は無限です。現在のキッチンのスキャンデータを使用して、美しいフォトリアリスティックな提案を生成し、材料と家具を調達するAIインテリアデザイナーになります。いくつかのデザインオプションを生成しました。AIカスタマーサービスエージェントとして、よりエンゲージングでパーソナライズされた対話を提供することもできます。デジタルヘルスケアワーカーとして患者の状態をチェックし、タイムリーでパーソナライズされたケアを提供することもできます。ペニシリンにアレルギーがあることを医師に言い忘れましたが、処方された抗生物質にはペニシリンが含まれていないので、安全に服用できます。AIブランドアンバサダーとして次のマーケティングや広告のトレンドを設定することもできます。

こんにちは、私はイマです。日本初のバーチャルモデルです。
生成AIとコンピュータグラフィックスの新しいブレークスルーにより、デジタルヒューマンは私たちと人間のように対話できるようになりました。おそらく録音や生産設定にいるようです。デジタルヒューマンの基盤は、多言語の音声認識と合成、会話を理解し生成する大規模言語モデル(LLM)に基づいています。特別な習慣はありますか?私たちには豊かな儀式と伝統舞踊、そして自然に対する深い敬意があります。AIは他の生成AIと接続し、リアルタイムのパストレーシングサブサーフェイススキャッタリングを使用して皮膚の光の透過、散乱、出口をシミュレートし、皮膚に柔らかさと透明感を与えます。
NVIDIA ACEはデジタルヒューマン技術のスイートであり、デプロイが容易で完全に最適化されたマイクロサービス(NIMS)として提供されます。開発者はACE NIMSを既存のフレームワーク、エンジン、デジタルヒューマン体験に統合できます。Nemetron SLMとLLM NIMSは意図を理解し、他のモデルを編成します。Riva Speech NIMSはインタラクティブな音声と翻訳のために使用されます。Audio-to-FaceとGesture NIMSは顔と体のアニメーションに使用されます。Omniverse RTXはDLSSを使用して皮膚や髪のニューラルレンダリングを行います。
ACE NIMSはNVIDIA GDN上で動作し、NVIDIA加速インフラストラクチャのグローバルネットワークで100以上の地域にわたる低遅延のデジタルヒューマン処理を提供します。
(デモ映像終わり)

非常に素晴らしいですね。ACEはクラウドでもPCでも動作します。私たちはTensor Core GPUをすべてのRTXに含める賢明な判断をしました。これにより、しばらくの間、AI GPUを提供してきました。この理由は非常に簡単です。新しいコンピューティングプラットフォームを作成するためには、まずインストールベースが必要です。最終的にはアプリケーションが登場します。インストールベースを作成しなければ、アプリケーションは来ません。
ですから、私たちはすべてのRTX GPUにTensor Core処理を含めました。そして今や1億台のGeForce RTX AI PCが存在し、出荷されています。このComputexでは、4つの新しい素晴らしいラップトップを紹介しています。すべてがAIを実行できます。将来のラップトップやPCはAIになります。常にあなたを助け、バックグラウンドで支援します。PCはAIによって強化されたアプリケーションを実行します。もちろん、すべての写真編集、執筆、ツールなど、使用するすべてのものがAIによって強化されます。そしてPCはAIを持つデジタルヒューマンのアプリケーションもホストします。AIはさまざまな形でPCに現れ、PCは非常に重要なAIプラットフォームになります。
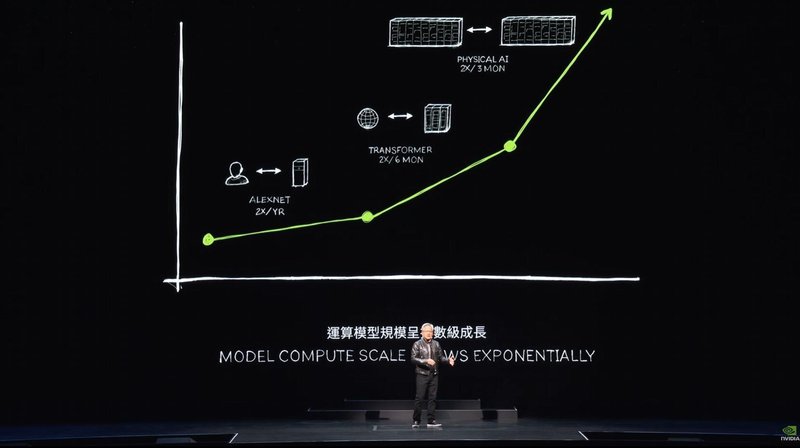
ここからどこへ進むのでしょうか?データセンターのスケーリングについて以前述べましたが、スケーリングするたびに新しいフェーズシフトが発生しました。DGXから大規模なAIスーパーコンピュータにスケーリングしたとき、大規模なデータセットを訓練するためのトランスフォーマーが可能になりました。最初はデータは人間が監督する必要がありました。AIを訓練するためには人間のラベル付けが必要でしたが、人間がラベル付けできる量には限りがあります。トランスフォーマーは教師なし学習を可能にしました。今やトランスフォーマーは膨大なデータやビデオ、画像を見て、膨大なデータを学習し、パターンや関係を見つけることができます。次世代のAIは物理ベースである必要があります。今日のほとんどのAIは物理法則を理解していません。物理世界に基づいていません。画像やビデオ、3Dグラフィックス、物理現象を生成するためには、物理法則を理解し、物理データに基づいたAIが必要です。
その方法の1つはビデオから学ぶことですが、もう1つの方法はシンセティックデータ、シミュレーションデータを使用することです。もう1つの方法は、コンピュータが互いに学習することです。これはAlphaGoが自己対戦し、同じ能力の間で長期間対戦し、よりスマートになるのと同じです。このようなAIが登場し始めます。AIデータが合成生成され、強化学習を使用する場合、データ生成の速度は進歩し続けます。データ生成が成長するたびに、提供する計算量も増加する必要があります。AIが物理法則を学習し、物理データに基づいたモデルを理解するフェーズに入りつつあります。モデルは成長し続け、大規模なGPUが必要です。Blackwellはこの世代のために設計されました。

これがBlackwellです。
いくつかの非常に重要な技術があります。1つはチップのサイズです。TSMCで最大のチップを2つつなぎ合わせ、10テラバイト/秒のリンクで接続しました。最先端のSERTISがこれら2つを接続します。次に、これら2つをコンピュータノードに配置し、グレイCPUと接続しました。グレイCPUは、訓練の際には迅速なチェックポイントと再起動に使用できます。推論と生成の際にはコンテキストメモリの保存に使用され、AIが会話のコンテキストを理解します。これは第2世代のトランスフォーマーエンジンです。トランスフォーマーエンジンは計算層に必要な精度と範囲に基づいて動的に低精度に適応します。これは第2世代のGPUであり、セキュアAIを備えています。サービスプロバイダーにAIの盗難や改ざんから保護するよう要求できます。第5世代のMVLinkです。これにより複数のGPUを接続できます。
また、信頼性と可用性エンジンも備えています。このシステムはすべてのトランジスタ、フリップフロップ、オンチップメモリ、オフチップメモリをテストできるため、フィールドで特定のチップが故障しているかどうかを判断できます。10,000台のGPUを持つスーパーコンピュータの平均故障間隔(MTBF)は数時間です。100,000台のGPUを持つスーパーコンピュータのMTBFは数分です。長期間動作するスーパーコンピュータが数か月間モデルを訓練することは、信頼性を向上させる技術を発明しない限り、ほぼ不可能です。信頼性は稼働時間を向上させ、コストに直接影響します。そして最後に、データ処理エンジンです。データ処理は非常に重要な作業の1つです。データ圧縮エンジン、解凍エンジンを追加し、今日可能な20倍の速度でデータをストレージから引き出すことができます。
これがBlackwellです。ここにあります。GTCではプロトタイプのBlackwellを紹介しました。

これは生産ボードです。最も複雑で高性能なコンピュータです。これがGray CPUです。これらは2つのBlackwellダイです。世界最大のチップです。それを10テラバイト/秒のリンクで接続します。性能は驚異的です。計算量の増加はコストの低下を意味します。Blackwellで行ったのは、GPT-4の訓練に必要なエネルギーを350倍削減したことです。Pascalでは1,000ギガワット時が必要でしたが、Blackwellでは3ギガワット時で済みます。訓練にかかる時間も大幅に短縮されました。

Blackwellの性能は驚異的ですが、それでも十分ではありません。さらに大きなマシンが必要です。

これがDGXです。BlackwellチップをDGXシステムに組み込みます。これがDGX Blackwellです。空冷式で、8つのGPUが搭載されています。GPUのヒートシンクのサイズを見てください。15キロワット、完全空冷です。液冷を希望する場合は、新しいシステムもあります。これがMGXです。モジュラーシステムであり、Blackwellボードを搭載しています。1ノードに4つのBlackwellチップがあります。液冷式です。72台のGPUを接続します。新しいNVLinkスイッチ第5世代を使用します。このスイッチは非常に高度な技術です。データレートは非常に高く、Blackwellを1つの巨大な72-GPUとして接続します。
これは1つのGPUドメインであり、72台のGPUを持つ1つのGPUのように見えます。前世代の8台と比較して9倍増加し、帯域幅は18倍、AIフロップスは45倍増加しました。消費電力は10倍です。これが100キロワット、これは10キロワットです。もちろん、さらに多くのGPUを接続できます。

このNVLinkチップは非常に重要です。大規模な言語モデルは非常に大きく、1つのGPUに収まりません。1つのノードにも収まりません。これをすべて接続し、非常に高速なネットワーキングで接続する必要があります。InfiniBandはスーパーコンピュータやAI工場で広く使用されていますが、すべてのデータセンターで対応できるわけではありません。EthernetアーキテクチャにInfiniBandの機能を導入しました。
Ethernetは高平均スループットのために設計されていますが、AI工場ではGPUが相互に通信します。部分的な結果を収集し、再分配するためのバーストトラフィックです。平均スループットではなく、最後の到着が重要です。Ethernetにはそのための仕組みがありません。そこで、いくつかの技術を作成しました。最先端のRDMA、ネットワークレベルのRDMAをEthernetで提供します。2つ目は混雑制御です。スイッチが常にテレメトリを行い、GPUやNICが過剰に情報を送信する場合、バックオフさせてホットスポットを防ぎます。3つ目はアダプティブルーティングです。混雑を検知し、使用されていないポートに送信し、受信側で再整理します。4つ目はノイズ隔離です。複数のモデルが同時に訓練されるため、ノイズが干渉します。ネットワーク利用率が40%低下し、訓練時間が20%長くなると、5億ドルのデータセンターが6億ドルのデータセンターのようになります。

Spectrum Xを使用したイーサネットは、ネットワークの性能を非常に向上させるため、ネットワークは実質的に無料になります。これは本当に大きな成果です。

私たちには一連のイーサネット製品があります。これがSpectrum X800です。これは51.2テラビット毎秒で256のラディックスを持っています。次に来るのは512ラディックスです。1年後に発売される予定です。512ラディックスで、これはSpectrum X800 Ultraと呼ばれます。その後に来るのはX1600です。
重要なアイデアは次のとおりです。X800は数万のGPU用に設計されています。X800 Ultraは数十万のGPU用に設計されており、X1600は数百万のGPU用に設計されています。
数百万のGPUデータセンターの時代がやってきます。その理由は非常にシンプルです。もちろん、より大きなモデルを訓練したいのですが、将来的には、インターネットやコンピュータとのほぼすべてのやり取りにクラウド上で動作する生成AIが関与する可能性が高くなります。
生成AIはあなたと連携し、ビデオや画像、テキスト、デジタルヒューマンを生成するかもしれません。そして、あなたはコンピュータとほぼ常にやり取りし、そのたびに生成AIが接続されています。一部はオンプレミスで、一部はデバイス上にあり、多くはクラウドに存在するかもしれません。
これらの生成AIは多くの推論能力も持つでしょう。一度の回答だけでなく、回答を改善するために反復するかもしれません。したがって、将来生成する量は非常に多くなるでしょう。
これらすべてを組み合わせたものを見てみましょう。
さて、今夜は初の夜間基調講演です。来てくれた皆さんに感謝します。(歓声と拍手)
今夜7時に来てくれた皆さんに感謝します。これから見せるものには新しい雰囲気があります。これが夜間基調講演の雰囲気ですので、楽しんでください。(拍手)
(ビデオ上映)

このスタイルの基調講演は、Computexでは初めてかもしれません。おそらく最後でしょう。(拍手)
これを実現できるのはNVIDIAだけです。これをできるのは私だけです。(歓声と拍手)
もちろん、Blackwellは、生成AI時代が到来したことを世界が知った直後に、AIファクトリーの重要性を認識した直後に、新しい産業革命の始まりに、最初に発表されたNVIDIAプラットフォームの第一世代です。

私たちには多くのサポートがあります。ほぼすべてのOEM、すべてのコンピューターメーカー、すべてのCSP、すべてのGPUクラウド、主権クラウド、さらには通信会社、世界中の企業がいます。
Blackwellの成功と採用、そしてその熱狂は非常に高く、皆さんに感謝したいと思います。(拍手)
私たちはそこに留まりません。この驚異的な成長の時期に、性能を向上させ続け、コストを削減し続け、トレーニングのコストや推論のコストを削減し続け、すべての企業がAIの能力を受け入れるためのスケールアウトを続けます。性能を向上させるほど、コストは低下します。
Hopperプラットフォームは、おそらく歴史上最も成功したデータセンタープロセッサーでした。しかし、Blackwellが登場し、各プラットフォームにはいくつかの特徴があります。CPU、GPU、NVLink、NIC、スイッチがあります。
NVLinkスイッチは、可能な限り大きなドメインとしてすべてのGPUを接続します。そして、できる限りのことをし、非常に大きく非常に高速なスイッチで接続します。各世代では、GPUだけでなく、その全体的なプラットフォームを構築します。AIファクトリースーパコンピュータに統合します。しかし、それを分解して世界に提供します。
それを分解して世界に提供します。
その理由は、皆さんが興味深く革新的な構成を作り出し、さまざまなスタイルを作り出し、異なるデータセンターや異なる顧客に合わせることができるからです。エッジのために、一部はテレコのために、そしてすべての異なるイノベーションが可能になります。
システムをオープンにし、皆さんが革新できるようにするために、統合されたシステムを設計し、分解して提供します。

Blackwellプラットフォームはここにあります。私たちの会社は一年のリズムで動いています。基本的な哲学は非常にシンプルです。データセンタースケール全体を構築し、それを分解して部品として販売し、一年のリズムで技術の限界まで押し進めます。TSMCのプロセス技術をどこまで押し進めるか、パッケージ技術をどこまで押し進めるか、メモリ技術をどこまで押し進めるか、SERTES技術、光学技術をどこまで押し進めるか、すべての技術を限界まで押し進めます。
その後、すべてのソフトウェアがこの全体のインストールベースで動作するようにします。ソフトウェアの慣性はコンピュータで最も重要なものです。コンピュータが後方互換性を持ち、既に作成されたすべてのソフトウェアとアーキテクチャ的に互換性がある場合、市場に出る速度が非常に速くなります。
インストールベースのソフトウェア全体を活用できると、速度が非常に速くなります。
Blackwellがここにあります。来年はBlackwell Ultraです。H100とH200があったように、Blackwell Ultraの新しい世代を見てください。再び限界まで押し進められます。
次世代のスペクトラムスイッチも同様です。これは次のクリックが初めて行われたものです。後悔するかどうかはまだわかりません。
(歓声)

私たちの会社にはコードネームがあります。非常に秘密にしています。多くの従業員も知りません。しかし、次世代プラットフォームはRubinと呼ばれます。Rubinプラットフォームです。
これについてあまり時間をかけません。写真を撮って、細かいところを見てください。Rubinプラットフォームがあります。1年後にRubin Ultraプラットフォームがあります。ここで示しているすべてのチップは、すべて完全に開発中です。技術の限界での1年のリズムで、すべて100%アーキテクチャ的に互換性があります。
これがNVIDIAが構築しているものであり、その上に豊富なソフトウェアがあります。多くの点で、過去12年間は、ImageNetの瞬間から、計算の未来が劇的に変わることを認識した瞬間から今日まで、本当に大きな変化を遂げました。
NVIDIAの会社は本当に大きく変わりました。そして、ここにいるすべてのパートナーに感謝したいと思います。

これはNVIDIA Blackwellプラットフォームです。

次に何が来るかについて話しましょう。次のAIの波は物理AIです。物理の法則を理解するAI、私たちの間で働くAIです。彼らは世界モデルを理解し、世界をどのように解釈するかを理解し、知覚する方法を理解する必要があります。
もちろん、優れた認知能力を持ち、私たちの要求を理解し、タスクを遂行する必要があります。将来、ロボティクスはより普及した概念になります。もちろん、ロボティクスと言うと、ヒューマノイドロボットがその代表例です。しかし、それは全く違います。
すべてがロボティックになるでしょう。すべての工場がロボティックになります。工場はロボットを編成し、ロボットがロボティックな製品を作ります。ロボットがロボットと相互作用し、ロボティックな製品を作ります。
それを実現するためには、いくつかのブレークスルーが必要です。ビデオを見てみましょう。

「ロボティクスの時代が到来しました。いつか動くすべてのものが自律的になります。研究者や企業は、物理AIによって動かされるロボットを開発しています。
物理AIは、指示を理解し、現実の世界で複雑なタスクを自律的に実行することができます。マルチモーダルLLMは、ロボットが学び、知覚し、周囲の世界を理解し、行動計画を立てるためのブレークスルーです。
人間のデモンストレーションから、ロボットは粗大および微細運動技能を使用して世界と相互作用するために必要な技能を学ぶことができます。
ロボティクスを進化させるための重要な技術の一つは、強化学習です。LLMが特定の技能を学ぶために人間のフィードバックを使用した強化学習(RLHF)を必要とするのと同様に、生成物理AIも仮想世界で物理的なフィードバックを使用して技能を学ぶことができます。
これらのシミュレーション環境では、ロボットが意思決定を行う方法を学ぶことができ、物理法則に従う仮想世界での行動を通じて、複雑で動的なタスクを安全かつ迅速に学び、数百万回の試行錯誤を経て技能を定義します。
私たちはNVIDIA Omniverseを、物理AIが作成されるオペレーティングシステムとして構築しました。Omniverseは、バーチャルワールドシミュレーションのための開発プラットフォームであり、リアルタイムの物理ベースレンダリング、物理シミュレーション、生成AI技術を組み合わせたものです。
Omniverseでは、ロボットがロボットになる方法を学びます。彼らは、物体を掴んだり扱ったりする精度を持って自律的に物体を操作する方法や、最適な経路を見つけ、障害物や危険を避けながら自律的に環境をナビゲートする方法を学びます。
Omniverseでの学習は、シムとリアルのギャップを最小化し、学習した行動の移転を最大化します。生成物理AIでロボットを構築するには、3つのコンピュータが必要です。NVIDIA AIスーパーコンピュータはモデルを訓練し、NVIDIA Jetson-ORINと次世代Jetson-Thorロボティクススーパーコンピュータはモデルを実行し、NVIDIA Omniverseは、ロボットが仮想世界で技能を学び、洗練する場所です。
私たちは、開発者や企業が必要とするプラットフォーム、アクセラレーションライブラリ、AIモデルを構築し、彼らが最適なスタックを使用できるようにします。
次のAIの波がここにあります。物理AIによるロボティクスは産業を革命化するでしょう。(拍手)

これは未来のことではありません。今、起こっています。
市場にサービスを提供する方法はいくつかあります。まず、各種のロボティクスシステム向けのプラットフォームを作成します。ロボティックファクトリーや倉庫向けのプラットフォーム、物を操作するロボット向けのプラットフォーム、移動するロボット向けのプラットフォーム、そしてヒューマノイドロボット向けのプラットフォームです。
これらのロボティクスプラットフォームは、ほぼすべての他のものと同様に、コンピュータ、アクセラレーションライブラリ、事前訓練されたモデルで構成されています。
コンピュータ、アクセラレーションライブラリ、事前訓練されたモデルです。私たちはすべてをテストし、すべてを訓練し、Omniverse内で統合します。Omniverseは、ビデオが言っていたように、ロボットがロボットになる方法を学ぶ場所です。
もちろん、ロボティック倉庫のエコシステムは非常に複雑です。多くの企業、多くのツール、多くの技術が現代の倉庫を構築するために必要です。倉庫はますますロボティクになります。いつか完全にロボティクになるでしょう。
各エコシステムには、ソフトウェア業界に接続されたSDKとAPI、エッジAI業界や企業に接続されたSDKとAPI、ODM向けのPLCやロボティクシステム向けのシステムがあります。その後、インテグレーターによって統合され、最終的には顧客のために倉庫が構築されます。

ここに、巨大なグループのためにロボティック倉庫を構築しているKenMacの例があります。
次に工場について話しましょう。工場には完全に異なるエコシステムがあります。Foxconnは世界で最も進んだ工場のいくつかを構築しています。彼らのエコシステムは、再びエッジコンピュータとロボティクス、工場を設計するためのソフトウェア、ワークフロー、ロボットのプログラミング、そしてデジタル工場やAI工場を編成するPLCコンピュータで構成されています。
私たちのSDKは、これらの各エコシステムにも接続されています。これは台湾全土で起こっています。

Foxconnは工場のデジタルツインを構築しています。Deltaは工場のデジタルツインを構築しています。ちなみに、半分はリアルで、半分はデジタルで、半分はOmniverseです。Pegatronはロボティック工場のデジタルツインを構築しています。Wishtronはロボティック工場のデジタルツインを構築しています。
これは本当に素晴らしいです。これはFoxconnの新しい工場のビデオです。見てみましょう。

NVIDIAの加速計算の需要は急増しています。世界が従来のデータセンターを生成AIファクトリーに近代化しているためです。
世界最大の電子機器メーカーであるFoxconnは、NVIDIA OmniverseとAIを使用して、この需要に応えるためにロボティック工場を構築しています。
工場のプランナーはOmniverseを使用して、Siemens TeamCenter XやAutodesk Revitなどの主要な業界アプリケーションから施設と設備データを統合しています。デジタルツインでは、フロアレイアウトとライン構成を最適化し、将来の運用を監視するためのカメラの最適な配置を見つけます。
仮想統合は、物理的な変更注文の莫大なコストを節約します。建設中、Foxconnのチームはデジタルツインを真実のソースとして使用し、正確な設備レイアウトをコミュニケーションし、検証します。Omniverseのデジタルツインは、Foxconnの開発者がNVIDIA Isaac AIアプリケーションをロボティックな認識と操作のために訓練し、テストするロボットジムでもあります。
Omniverseでは、FoxconnはAIスーパーコンピュータを構築するロボティック工場を構築し、NVIDIA Isaacを実行するロボットを編成します。(音楽)(拍手)

ロボティック工場は3つのコンピュータで設計されています。NVIDIA AIでAIを訓練し、工場を編成するためのPLCシステムでロボットを実行し、すべてをOmniverse内でシミュレートします。
ロボットアームとロボティックAMRも同様に3つのコンピュータシステムで設計されています。違いは、2つのOmniverseが一つの仮想空間を共有することです。共有する仮想空間では、ロボットアームがロボティック工場の中に入ります。そして再び、3つのコンピュータを提供し、加速レイヤーと事前訓練されたAIモデルを提供します。
私たちは、世界有数の産業自動化ソフトウェアとシステム会社であるSiemensと協力して、NVIDIA ManipulatorとNVIDIA Omniverseを統合しました。これは本当に素晴らしいパートナーシップであり、彼らは世界中の工場で作業しています。
Symantec PIC AIは、Isaac Manipulatorを統合しており、Symantec PIC AIはABB、KUKA、Yaskawa、Finuc、Universal Robotics、TechManを運用しています。
他にも多くの統合があります。見てみましょう。

ArcBestは、物体認識と人間の動きの追跡を強化するために、Isaac PerceptorをFoxSmart自律ロボットに統合しています。
BYD Electronicsは、製造効率を向上させるために、Isaac ManipulatorとPerceptorをAIロボットに統合しています。
Idealworksは、Isaac PerceptorをIWOSソフトウェアに統合し、工場物流のAIロボットを構築しています。
Intrinsicは、Isaac ManipulatorをFlowStateプラットフォームに採用し、ロボットの把握を進化させています。
Gideonは、Trey AI対応フォークリフトにIsaac Perceptorを統合し、AI対応物流を進化させています。
Argo Roboticsは、Isaac PerceptorをPerception Engineに採用し、ビジョンベースのAMRを進化させています。
Salomonは、産業操作のためにIsaac Manipulator AIモデルをAcupik 3Dソフトウェアに使用しています。
Techman Robotは、TMFlowにIsaac SimとManipulatorを採用し、自動光学検査を加速しています。
Teradyne Roboticsは、Polyscope XにIsaac Manipulatorを統合し、協働ロボットにIsaac Perceptorを統合しています。
Ventionは、AI操作ロボットのためにMachine LogicにIsaac Manipulatorを統合しています。

ロボティクスがここにあります。物理AIがここにあります。これはSFではなく、台湾全土で使用されています。本当にエキサイティングです。
そして、工場の中のロボット、そしてすべての製品もロボティックになるでしょう。2つの非常に大量のロボティック製品があります。
1つは自動運転車、または自律能力を持つ車です。NVIDIAは再び全スタックを構築します。来年、Mercedesのフリートで生産を開始し、その後、2026年にJLRのフリートが続きます。
私たちは世界にフルスタックを提供します。しかし、どの部分でもどのレイヤーでも自由に使用できます。ドライブスタック全体がオープンです。

次の大量のロボティック製品は、ロボティック工場で製造され、内部にロボットが入っているヒューマノイドロボットになるでしょう。近年、この分野では大きな進展がありました。認知能力は基盤モデルのおかげで、そして世界理解能力も進化しています。
この分野には非常に興奮しています。最も適応しやすいロボットはヒューマノイドロボットだからです。私たちのために作られた世界に最も適しています。さらに、他の種類のロボットよりも訓練データが豊富です。私たちと同じ体格を持っているからです。
デモンストレーションやビデオを通じて提供できる訓練データの量は非常に大きくなります。この分野で多くの進展が見られるでしょう。
さて、いくつかのロボットを紹介しましょう。

私のサイズくらいです。(笑)(拍手)

友達も一緒に来ています。
ロボティクスの未来はここにあります。次のAIの波です。
台湾はキーボード付きのコンピュータを作ります。ポケット用のコンピュータを作ります。クラウドのデータセンター用のコンピュータを作ります。将来的には、歩くコンピュータや、転がるコンピュータを作るでしょう。これらはすべてコンピュータです。
そして、技術は今日作っている他のすべてのコンピュータと非常に似ています。これは本当に素晴らしい旅になるでしょう。

さて、最後にビデオを作りました。楽しんでいただければと思います。再生しましょう。
ありがとう。
皆さんを愛しています。ありがとう。
皆さん、来てくれてありがとう。素晴らしいComputexを。
ありがとう。
この記事が気に入ったらサポートをしてみませんか?