Python+DjangoでSNSを作る~Day1 WebサイトとHTML

このシリーズは、「PythonのFlameWorkであるDjango(ジャンゴ)というパッケージを使って、Webアプリを作ってみよう。」という記事です。
本当は他に作ってみたいアプリがあるのですが、いきなりだと難しいと思うので、簡単なもの作ってローカル環境で動かすようにし、Webにもアップしてみる、ところまで書こうと思います。
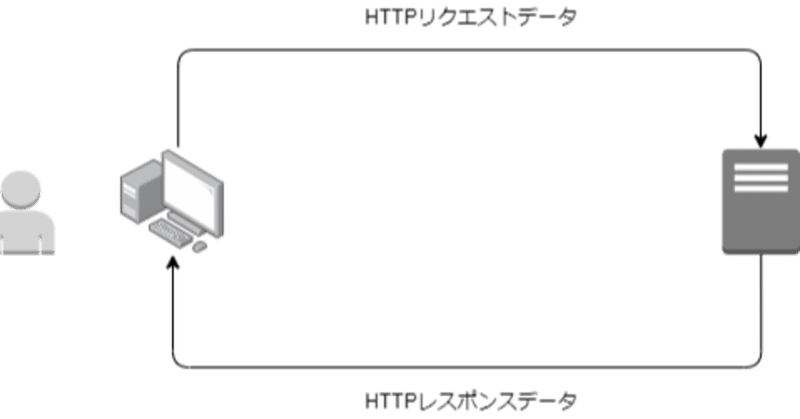
1.Webサイトの仕組み
Webサイトの仕組みを、ご存知の方もいると思いますが、まずはざっくりと。
① クライアント(端末)から、インターネット回線を経由して、該当のアドレス(いわゆるURL)にリクエスト送信を行います。(HTTPリクエスト)
➁ リクエストされた内容に対して、Webサイト側にあるHTMLデータをクライアント側に返します。(HTTPレスポンス)
➂ クライアント側のブラウザで、HTMLデータを今あなたが見ているこのページのように表示する。
以下のようなイメージです。
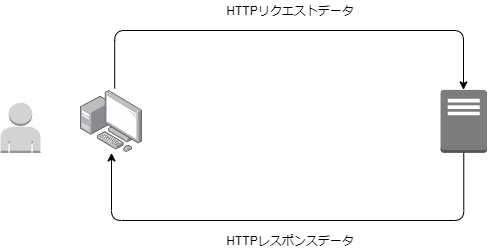
このHTTPレスポンスデータの中に、いわゆるHTML(後述)で記載されたWebページを表示するためのネタが入っているのです。
2. HTMLとは
HTMLは、ハイパーテキスト・マークアップ・ランゲージと言います。簡単に言うと、記載された文章をタグで囲むことで、それぞれに役割を与えられます。
3. HTMLを記述して開いてみよう
例えば、メモ帳を開いてみてください。
開いたら、以下のように記述してみてください。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>test_page</title>
</heda>
<body>
<h1>すっとこどっこいノンストップ飯田</h1>
<h2>本当にすっとこどっこいなの?</h2>
<p>はい。すっとこどっこいです。</p>
<h2>すっとどっこいデータ</h2>
<table border="1" width="500" bordercolor="#333333">
<tr>
<th bgcolor="#a9a9a9">要素</th>
<th bgcolor="#a9a9a9" width="150">説明</th>
<th bgcolor="#a9a9a9" width="200">すっとこどっこい度</th>
</tr>
<tr>
<td bgcolor="#778899">記憶力が悪い</td>
<td valign="top" width="150">人の名前覚えられず
</td>
<td bgcolor="#FFFFFF" valign="top" width="200">90</td>
</tr>
<tr>
<td bgcolor="#778899">ノリとはったり</td>
<td valign="top" width="150">基本適当です。
</td>
<td valign="top" width="200">80</td>
</tr>
</table>
<p>すっとこどっこいでごめんね。</p>
<h2>外部リンク</h2>
<a href="https://note.com/nonstop_iida/m/mbf364fb85bf7">外部サイト</a>
</body>
</html>この通りじゃなくても、文章は適当でいいです。
では、このメモ帳を保存する時に、拡張子を「.html」に変えて保存してみてください。
デフォルト
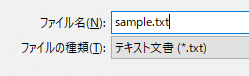
拡張子を変えて保存する
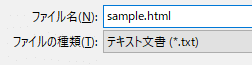
そうすると、フォルダにはこんな感じで、sample.htmlファイルが保存されます。これを開いてみましょう。

開くと・・・以下のように表示がされます。
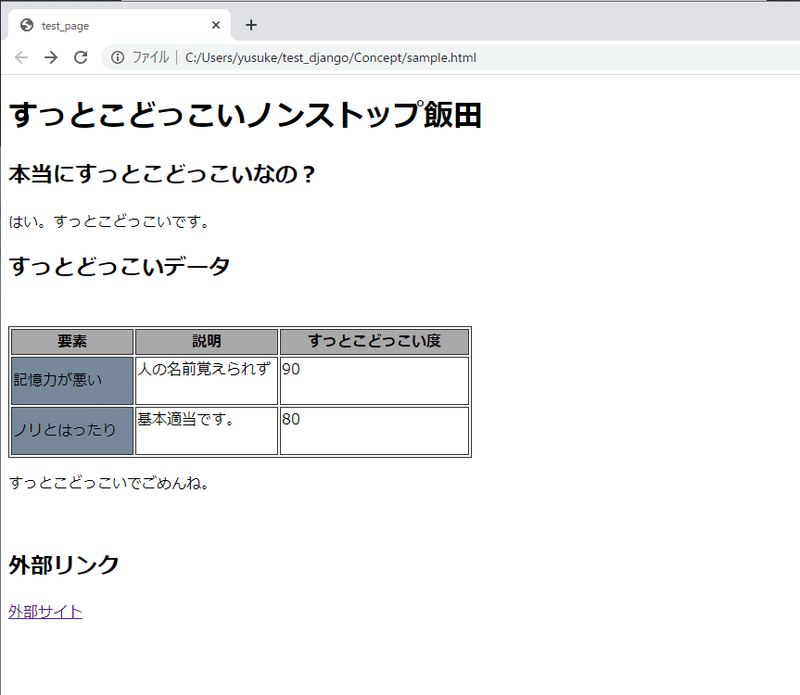
4.インターネットでWebサイト閲覧をする際の原理
普段Webブラウザで私たちがインターネット上の頁を見ている原理としては、Web上からHTTPレスポンスで取得した上記のようなhtmlファイルをブラウザでhtmlタグをもとに、上記のように表示しているのです。
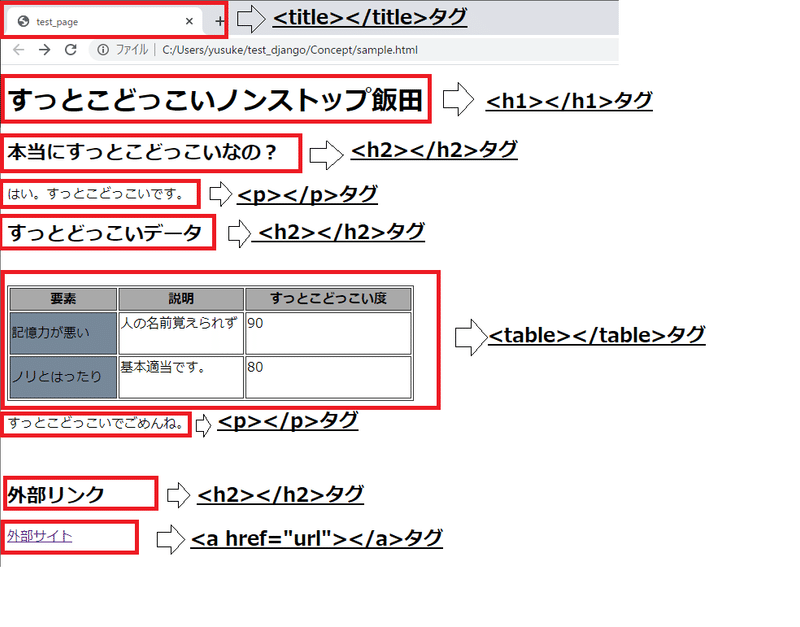
5.Webスクレイピングの原理
ちょっと脱線しますが・・・
WebスクレイピングはHTTPリクエストを行い、HTTPレスポンスデータからhtmlデータを取り出し、これをタグ等で絞って欲しい情報を抽出するものでした。
先ほど作成したhtmlファイルを利用しても、Webスクレイピングは可能です。ちょっとやってみましょう。
僕は、AnacondaでPythonを使っているので、仮想環境を有効化してJupyter Notebookを開いています。コマンドプロンプトやIDLE等のその他エディターでPythonを書ける方はそのやり方でOKです。
先ほどのhtmlファイルと同じフォルダに、プログラムを作ります。
では、sample.htmlファイルを読み込んで、h2タグの内容を抽出してみましょう。(スクレイピングのやり方等は、以下マガジンを参照)

はい、できました。
過去のWebスクレイピングの記事では、requestsライブラリをインポートし、getメソッドを使ってHTTPレスポンス情報を取得して、レスポンスデータからテキスト情報としてhtmlデータを取り出していました。
今回は、そもそもhtmlデータを自分で保有しているので、それをBeautifulSoupで解析した・・・ということです。
ちょっとスクレイピングで脱線しましたが、改めてWebサイトの仕組み・原理について少し理解が深まったのではないでしょうか。
次回は、Webアプリケーションの仕組みについて書きます。
この記事が気に入ったらサポートをしてみませんか?