
Transformerについてざっくり理解する

大規模言語モデルとは何か?を理解する上で
欠かせないのがTransformer(トランスフォーマー)です。
この記事では、
Transformerの仕組みについて、
難しい数式などは使わずに
分かりやすく解説していきます。
↓こちらもご覧ください
Transformerとは
Transfomerは、
Googleが2017年に発表した深層学習モデルです。
それまでのモデルに比べ、
格段に、学習時間が短くかつ高精度なモデルであったことから、
世界に大きな衝撃を与えました。
今では、大規模言語モデルの全てで
Transformerが採用されています。
また、大規模言語モデル以外に、
画像処理や音声処理の分野など多方面で利用されています。
Transformerは何がスゴいのか?
大規模言語モデルについては、
「スケーリング則」という経験則が
定着しつつあります。
スケーリング則とは、
学習の規模が大きくなればなるほど
モデルの性能が向上するというものです。
当たり前にようにも聞こえますが、
このことは最近までわかっていませんでした。
Transformerのすごいところは、
このスケーリング則を可能にしたことです。
具体的には、
インターネット上に存在する大量のテキストを
学習させることが可能になったのです。
これにより、言語モデルが格段に賢くなりました。
町の図書館の本しか知らない人より
世界中の本を知っている人の方が賢いですよね
それと同じ原理です。
Transformerが登場する以前の話
Transformerが登場する前は、
大量のテキストデータを学習させることが
困難でした。
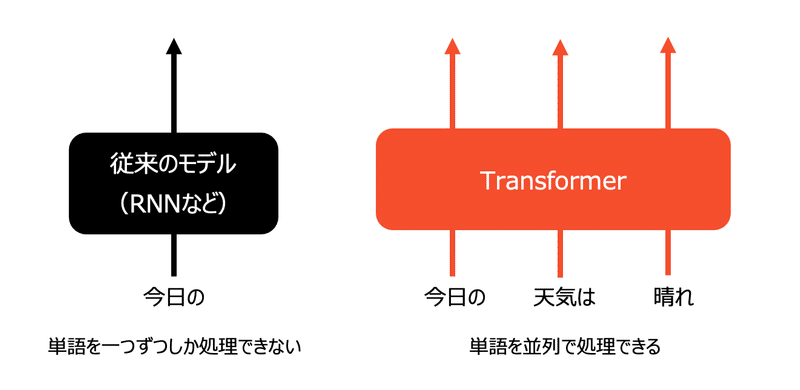
文章を学習させる際に、
文の先頭の単語から順番に入力し、
一語、一語ずつ処理する必要があったため、
計算にとても時間を要したのです。
ついでに言うと、
文の中で離れた位置にある単語の関係を捉えるのが
難しかったりという問題も抱えていました。
この問題を解決したのがTransformerです。
言語モデルで重要なこと
言語モデルは、
ある単語の次にどのような単語がくるかを
確率的に予測するモデルのことです。
そこでは、モデル自身が
単語の意味と
文脈の
二つを理解することが重要になってきます。
このうち、単語の意味を理解することは、
割と昔からできていました。
具体的には、大規模なテキストを学習し、
単語をベクトルで表現する技術が開発されました。
Word2Vecというモデルになります。
↓Word2Vecについてご紹介した記事はこちら
ところが、この技術には一つ問題がありました。
各単語に対してベクトルは一つしか割り当てられないのです。
つまり、多義語に対応していないということです。
例えば、「マウス」は、ネズミとパソコンの機器の二つの意味がありますが、Word2Vecだと一つのベクトルになります。
こうした問題もあり、
文脈を理解したうえで、単語の意味を理解する技術が
重要になってきました。
文脈を理解するために、
文章を頭から順番に処理し、
その単語の情報を覚えておくという
手法が考案されました。
ただ、こうした方法にも問題がありました。
具体的には、
離れた位置にある単語の情報を考慮しにくいし、
頭から順番に処理するため、
並列計算ができず、計算にとても時間がかかるという問題がありました。
こうした問題に対応できたのが
Transformerです。
Transformerの仕組み
主な特長は以下の2つです。
並列処理ができる
Transformerは文中の複数の単語を一度に処理できます。
これにより、処理速度が向上します。
GPUという並列処理ができる
プロセッサを用いることで
高速な計算処理が可能になりました
アテンション機構
アテンションという仕組みを取り入れたことで、
文の中の単語が他の単語とどのように関連しているかを
効率よく計算できるようになりました。
離れた位置にある単語の情報も適切に取り入れることができ、
より深く文脈を考慮することができるようになりました。
アテンションの詳しい仕組みは
難しいのでここでは割愛します。
興味のある方は、ぜひ、調べてみてください。
Transformerのキモはアテンションです。
言語の理解にアテンションを用いることで、
並列計算が可能になり、
言語モデルの大規模化を実現できました。
Transformerのモデル構造
最後にTransfomerのモデル構造を
簡単にご紹介します。
Transfomerは以下のような構造をしています。
エンコーダ・デコーダという
二つのモデル構成を持っています。
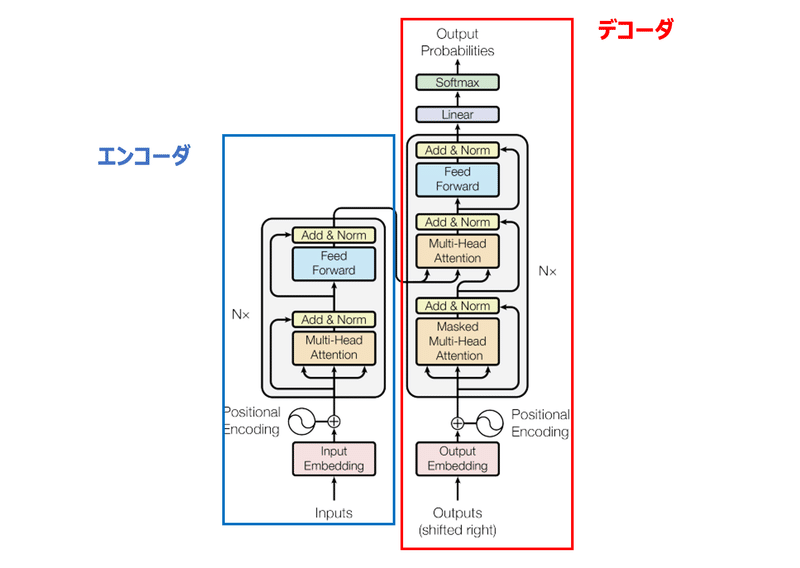
エンコーダの役割は、入力したテキストデータをコンピュータが処理できる形式に変換することです。
例えば、英語を日本語に機械翻訳するモデルを考えてみます。
エンコーダでは、英語の文章を入力し、コンピュータが処理できるよう数値ベクトルに変換します。
デコーダの役割は、エンコーダから受け取ったデータを別の形式に変換することです。
翻訳の例ですと、英語の数値ベクトルを受け取り、日本語に変換します。
ChatGPTには、
GPTという言語モデルが使われています、
GPTは、上記のデコーダ部分(右側)をベースに
作られています。
さいごに
いかがでしたでしょうか。
Transformerは
いまや画像処理・音声処理の世界でも使われていて、
AI全般の計算効率向上に大きな貢献を果たしています。
興味を持たれた方は、
論文も読んでみることをお勧めします。
次回は、大規模言語モデルの中の
BERTモデルについてみていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?