
【StableDiffusion】OneTrainer で LoRA (LyCORIS) を作ってみた!【つくよみちゃん】

こんな方にオススメ!
1.LoRA (LyCORIS) を使うことはできるから、オリジナルの LoRA (LyCORIS) を作ってみたい!
2.でも、TrainTrain, kohya-ss で作れなかった…。
3.StableMatrix で入れられる OneTrainer って何?
この記事を最後まで読むと…
本手法では、夢前黎 様が作成されたイラストと VRM モデルを学習に用いています。
つくよみちゃん公式サイト、つくよみちゃん公式 X
補足事項
・OneTrainer の使い方は無料で読めます。
・本記事の内容は 2024/10/21 現在の情報です。
・グラボは RTX 4070 SUPER を用いました。
・本記事は SDXL モデルで手順を紹介していますが、OneTrainer は他のモデルにも対応しています。
・本記事はあくまで OneTrainer の使い方を紹介することが目的です。作成したつくよみちゃん LoRA (LyCORIS) の配布はいたしません。
・本記事に掲載したつくよみちゃん生成画像を素材として用いることは禁止とします。
きっかけ
TrainTrain で LoRA を作ってみようとした
モデルマージでオリジナルの SDXL モデルも作れたし、LoRA も自作してみよう!
TrainTrain を使うと楽らしい。
オリジナルマージモデルで、いざ学習開始ぃ!
ん?

では、kohya_ss で
かつ作ってみたら効果が出ないこともありました…。他にLoRAを作れるツールは無いものか。
というのがきっかけです。
1. OneTrainer?
StabilityMatrix で導入可能
困りながら StabilityMatrix の Add Package の Training を見てみましたら、kohya_ss と並んで OneTrainer というものがありました。ググってみると、SDXL, SD1.5 はもちろん flux の LoRA も作れるツールだそうなのでインストールしました。

日本語の情報は少ないが
画面が見やすいのはいいのですが、日本語の情報は検索しても 10 件あるかどうかぐらいしかヒットしません。
ですが、公式の wiki を見るとクイックスタートガイドがあったり、タブの順番どおりに説明が書かれていたりと、こちらも見やすく作られています。
これならば、翻訳サイトにコピペして翻訳すればやっていけそうです。
2. OneTrainer の説明
クイックスタートガイド
※DeepL で訳した文を元にした意訳を記しています。
※長いので、把握しておくと良さそうな部分だけ載せてます。
このガイドは、OneTrainer の基本的な使い方の方針を、UI で表示される順番で説明することを目的としています。詳細な説明は wiki をご覧ください。
データセットの準備
トレーニングしたい画像を好きなディレクトリに置いてください。最も良い結果を得るためには、すべての画像にプロンプトを追加してください。方法は 2 つあります。
1. 同じディレクトリに各画像と同じ名前の .txt ファイルを追加します。このテキストファイルにはトレーニングするプロンプトを記述します。
2. すべての画像の名前をトレーニングしたいプロンプトに変更します。
プリセット
OneTrainer には、すぐに使えるようにプリセットセットが用意されています。目的に合ったものを選択して、必要に応じて設定を変更してください。独自のプリセットを追加することもできます。
ワークスペース
OneTrainer はワークスペースディレクトリを使用して各トレーニング実行結果を区別します。ワークスペースディレクトリには、1 つのランのバックアップ、サンプリング、テンソルボードのデータがすべて含まれます。新しいトレーニングを実行するときは、空のディレクトリをワークスペースとして選択することをお勧めします。
テンソルボード
Tensorboard を使用すると、トレーニング中にトレーニングの進捗状況を簡単に追跡できます。トレーニング実行中に、下部にある Tensorboard ボタンをクリックすると、ウェブブラウザが開きます。ここには、loss 値とサンプリング画像が表示されます。
コンセプトの追加
コンセプトはトレーニングしたいデータを定義します。まず設定を作成します。次に、必要な数のコンセプトを追加できます。コンセプトを追加したら、ウィジェットをクリックして詳細ウィンドウを開きます。このウィンドウでは、オプションで名前を選択し、画像を保存するディレクトリを指定できます。プロンプトソースはプロンプトをどこから読み込むかを定義します。
augmentation タブでは、トレーニング前に OneTrainer が画像をどのように修正するかを定義できます。これらの修正により、トレーニングデータの多様性を高めることができます。
トレーニング設定
ここではトレーニング中に使用されるすべてのパラメータを設定することができます。おそらくこれらの設定のほとんどは変更する必要がないでしょうが、ここでは最も重要なものの例をいくつか示します:
・Learning Rate: この設定はモデルにどれくらいの速さで学習させたいかを定義します。ただし、高すぎるとモデルが壊れてしまいます。
・Epochs: データセットの各画像に対して、モデルを何ステップ学習させるかを設定します。
・Batch Size: 一度に学習する画像の数を定義します。高く設定すると、より一般化された結果が得られますが、トレーニングに時間がかかり、より多くのVRAMが必要になります。
・Accumulation Steps: VRAM の制約で Batch Size を大きくできない場合、この設定を大きくすることで同じ効果が得られますが、学習速度はさらに遅くなります。
解像度
トレーニング画像は、トレーニング時にその解像度にリサイズされます。手動でリサイズする必要はありません。複数の解像度をカンマ区切りで指定できます。すべての解像度が同時にトレーニングされます。
サンプリング
ここでは、トレーニング中にモデルを定期的にサンプリングする時のプロンプトを定義できます。結果は tensorboard に表示され、ワークスペースディレクトリにも保存されます。
バックアップとコンティニュー
バックアップタブでは、トレーニング実行中に保存するバックアップの間隔の設定ができます。バックアップはワークスペースに保存されます。
バックアップにはトレーニング実行を継続するためのすべてのモデルデータが含まれます。以前のバックアップからトレーニングを継続するには、バックアップディレクトリをベースモデルとして選択します。
バックアップは、モデル変換ツールを使用してモデルファイルに変換することができます。
タブごとの説明~画像を添えて~
※DeepL で訳した文を元にした意訳を記しています。
※長いので、把握しておくと良さそうな部分だけ載せてます。
general タブ
このタブでは、OneTrainer が使用するディレクトリを定義します。
・Workspace Directory (default - workspace/run): 必須。このディレクトリには、トレーニング中に生成されたサンプル、トレーニング設定、バックアップ、tensorboard ログが格納されます。
・Cache Directory (default - workspace-cache/run): 必須。実行時にキャッシュされた画像とテキストを保存します。
・Continue from last backup (default - off): 有効にすると、選択したワークスペースの最後のバックアップを使用します。
・Debug Mode (default - off):
・Debug Directory (default - debug):
・Tensorboard (デフォルト - on): トレーニング開始時にTensorboardを起動するかどうか。
・Expose Tensorboard (default - off):
・Train device (default - cuda):
・Temp device (default - cpu):

24/10/21 時点の wiki では未記載でした。
model タブ
ここでは、トレーニングに使用するベースモデルと出力するモデルを定義します。
Base Model (default: hugging face link to base): 使用したいモデルのパスを指定するか、huggingface フォーマットでのリンクを指定します (例: stabilityai/stable-diffusion-xl-base-1.0)。
Vae (default:blank): カスタムVAEを使用する場合は、huggingfaceリンクである必要があります(例: madebyollin/sdxl-vae-fp16-fix)
Model Output destination: 任意のローカルフォルダの名前と出力するファイルの拡張子を設定します (例:C:/OneTrainer/Output/xxx.safetensors)。
注意 - ディフューザー出力を生成するモデルは、safetensor ファイルまで入れず、ディレクトリまでを入れてください。現在のところ、Pixart Alpha がこれにあたります。
Data Type: 4 つのオプションがあります。精度の低いものから float8、bfloat16、float16、float32 です。精度が高いほど学習時に必要なVRAMが増えます。
すべてのサンプルが黒くなる場合は、VAE データ型を float32 またはbfloat16 に設定するか、VAE オーバーライドを使用して固定 VAE をロードしてみてください。
注意:プリセット(左上のドロップダウン:#SD1.5 LoRA、#SD1.5 Embedding、...)を選ぶとデフォルト値が設定されます。その通りにしてください。
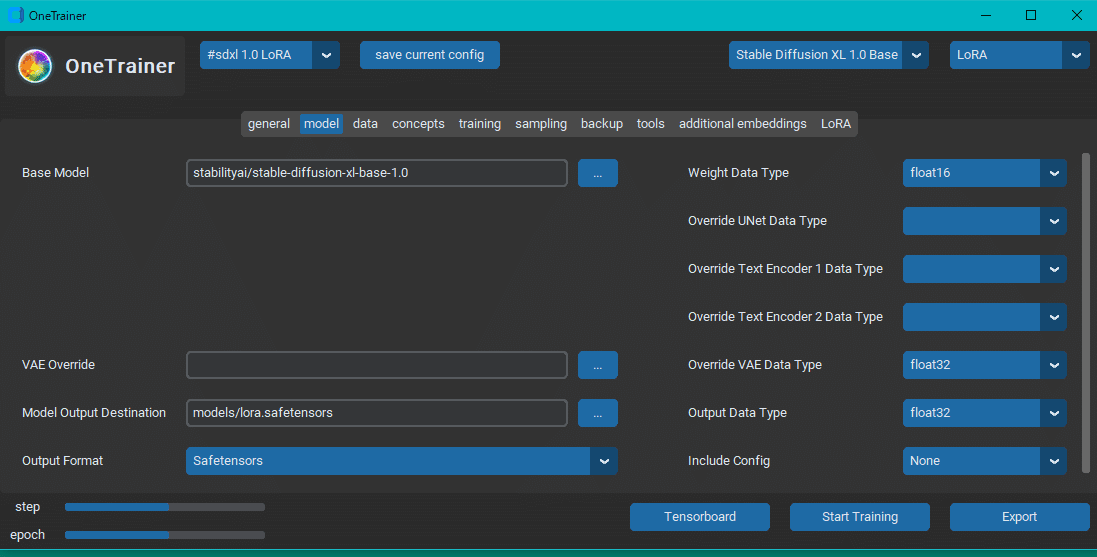
RTX 4070 SUPER ではこの設定かつバッチサイズ 4, Rank とalpha の値が 16 (後述) で、10 GB 程度の VRAM を使用していました。
data タブ
Aspect Ratio Bucketing は、異なるアスペクト比の画像に対して同時にモデルをトレーニングすることを可能にします。すべての画像は、同じ総ピクセル数にほぼ一致するようにリサイズされます。
Latent caching は中間データを保存することで学習を高速化します。この設定を有効にすると、トレーニング画像に基づいていくつかのデータが計算され、ディスクに保存されます。
concepts タブ
Concepts タブは OneTrainer に読み込ませる学習データを指示する場所です。Concepts には、学習データ、正則化データ、その他学習したいデータを指定することができます。
consepts タブは以下の要素で構成されています:
・ドロップダウンメニュー(デフォルト:concepts)
複数のコンフィグを設定、保存でき、ドロップダウンメニューでコンフィグを選択します。OneTrainer は選択されたコンフィグに含まれている consepts からのみトレーニングを行います。
・Add config
このボタンを押すと、新しいコンフィグを作成するための名前を入力する UI が表示されます。
・Add concept
このボタンを押すと、現在のコンフィグに新しい concept を追加作成します。
・Delete concept (赤の X)
コンセプト上のこのボタンを押すと、そのコンセプトが削除されます。
・Duplicate concept (緑色の +)
このボタンを押すと、すべての設定を含めてコンセプトをコピーして増やします。
・Enable concept (toggle, default: on)
このスライド式トグルは、concept の有効、無効を切り替えられます。有効な場合、トグルは青で表示されます。
・Edit concept
concept 画像のボタンとトグル以外の部分をクリックすると、concept 設定ウィンドウが開きます。
追加した concept の設定については後述します。
Training タブはほとんどコンフィグ通りの設定で良いと思われるかつ私が機械学習の専門家でない故に意訳できませんので大半を省略します。ご容赦ください。
training タブ
メインセッティング
最も重要な設定は、Learning Rate, Scheduler Optimizer。次に来るのが epochs, batch size, accumulation steps です。
最終的にベースモデルに応じてトレーニングの解像度を設定します。resolution にカンマ区切りの数値リストを指定することで、複数の解像度を同時に学習させることができます。各ステップでは、リストからランダムに選択された解像度でトレーニングが行われます。複数の解像度を同時に学習することで、モデルの品質が大幅に向上することが知られています。
マルチ解像度の値の例 (64 px ずつ上下させる) :
SD1.5 : 384, 448, 512, 576, 640
SDXL : 896, 960, 1024, 1088, 1152
また、オプションで解像度のオーバーライドを使用することもできます。
Epochs / batch / accumulation steps
・Epochs: エポックとは、すべての画像を学習するサイクルのことです。バッチサイズとデータセットに応じて、1 回またはそれ以上の反復数を設定します。
・Batch size: 処理のために GPU に送られる画像の数。
・accumulation steps: バッチサイズの乗数。
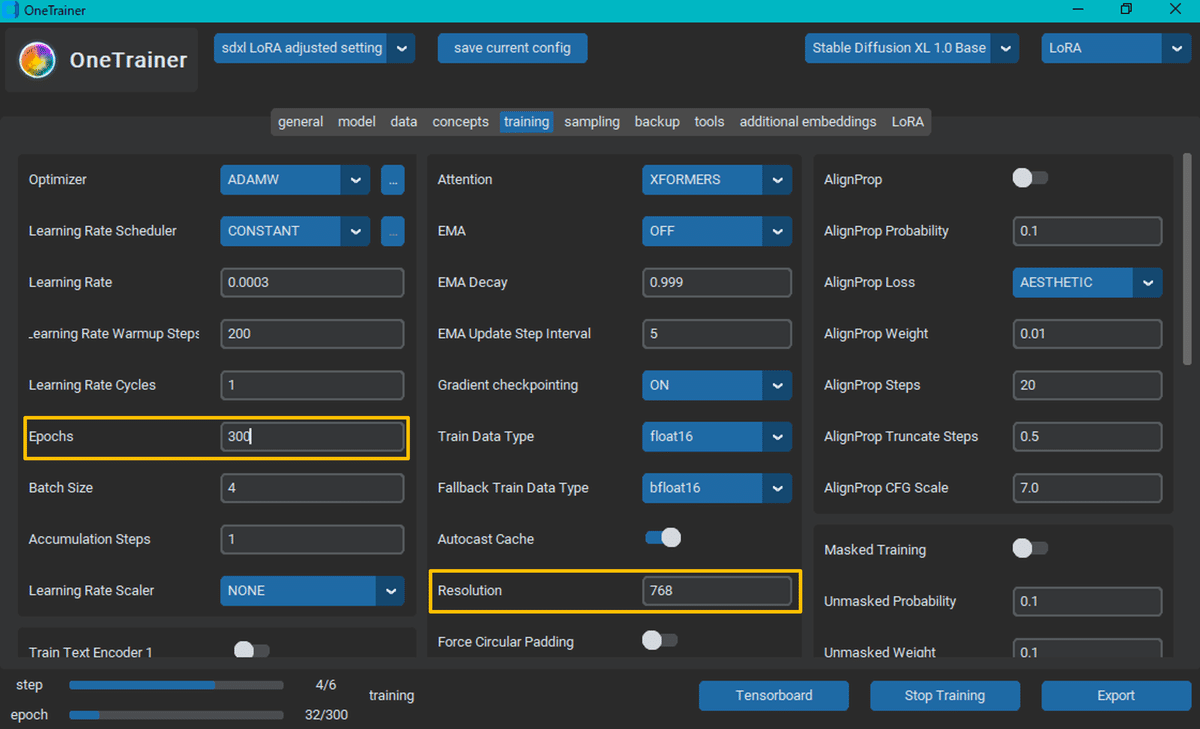
"解像度のオーバーライド" が何を意味しているのかは、理解していません
Resolution の値を 768 にしたのは、以下のサイトで "768か1024に" とあったからです。
sampling タブと backup タブは wiki に中身が書かれていないページしかなかったので、私の設定画面を貼り付けるだけにします。

Tools タブ と Embedding タブは今回使っていないので省略します。
LoRA タブ
このタブは LoRA を作成する場合のみ表示されます。
このタブにはいくつかのオプションがあります。
・タイプ (デフォルト:LoRA): どの形式のパラメータ効率の良い Fine Tuning 手法を実行するか。選択肢は LoRA (従来型) と LoHa (Lycorisプロジェクトが導入)。
・LoRA base model (デフォルト : 空欄): LoRA をロードして作業を続けることができます。また、バックアップフォルダを使用することもできますが、バックアップフォルダを読み込むと、できることが制限されるので注意してください。
・LoRA rank (デフォルト : 16): LoRAのレイヤー数を決める値です。レイヤー数が多いほど、より多くのVRAM が必要になりますが、保存できるデータも多くなります。
・LoRA alpha (デフォルト : 1.0): 調整可能なハイパーパラメーターです。alpha/rank の値を learning rate に乗じます。
・Decompose Weights (デフォルト:オフ): LoRA でのみ有効。大きさ/方向の重み分解を行う。これはしばしば DoRA として知られ、従来の手法よりもはるかに優れた学習と速い収束をもたらします。このオプションを選択する場合は、Dropout probability を通常の LoRA に設定する場合の 1/10 まで大幅に下げる必要があります。
・Dropout probability (デフォルト - 0.0): あるガイド (下記リンク先) では、0.1から0.5の間の値を推奨しています。もっと詳しく知りたい場合は、そのガイドをチェックしてください。
・LoRA weight data type (デフォルト : float32): LoRA をメモリにロードするときに、どの精度を使うか。
・Bundle Embeddings (デフォルト : オン): 追加のエンベッディングをトレーニングする場合、LoRAファイルにバンドルします。このオプションはAutomatic1111とSD.Nextでのみサポートされています。
・Layer Preset: 学習するモデルレイヤーを選択します。custom "を選択し、カンマ区切りで指定することもできます。しかし、attention onlyかattention+MLPのどちらかにすることをお勧めします。
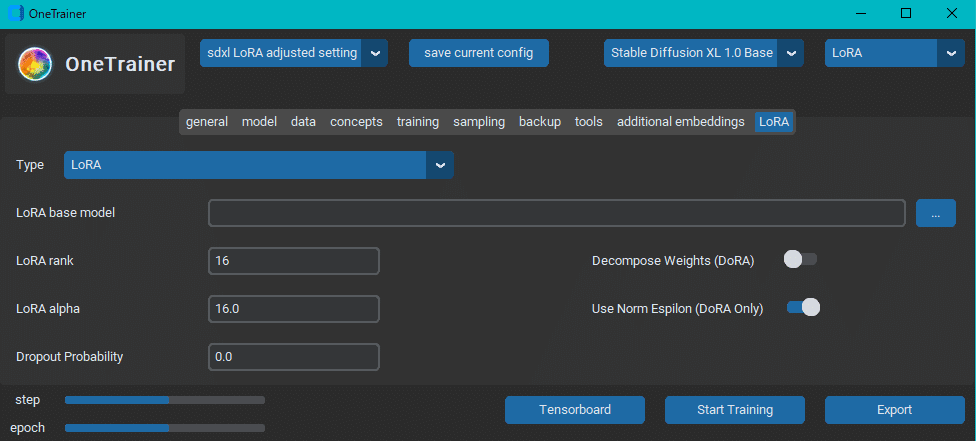
LoRA rank と alpha の値の参考にしたサイトは以下の 2サイトです。
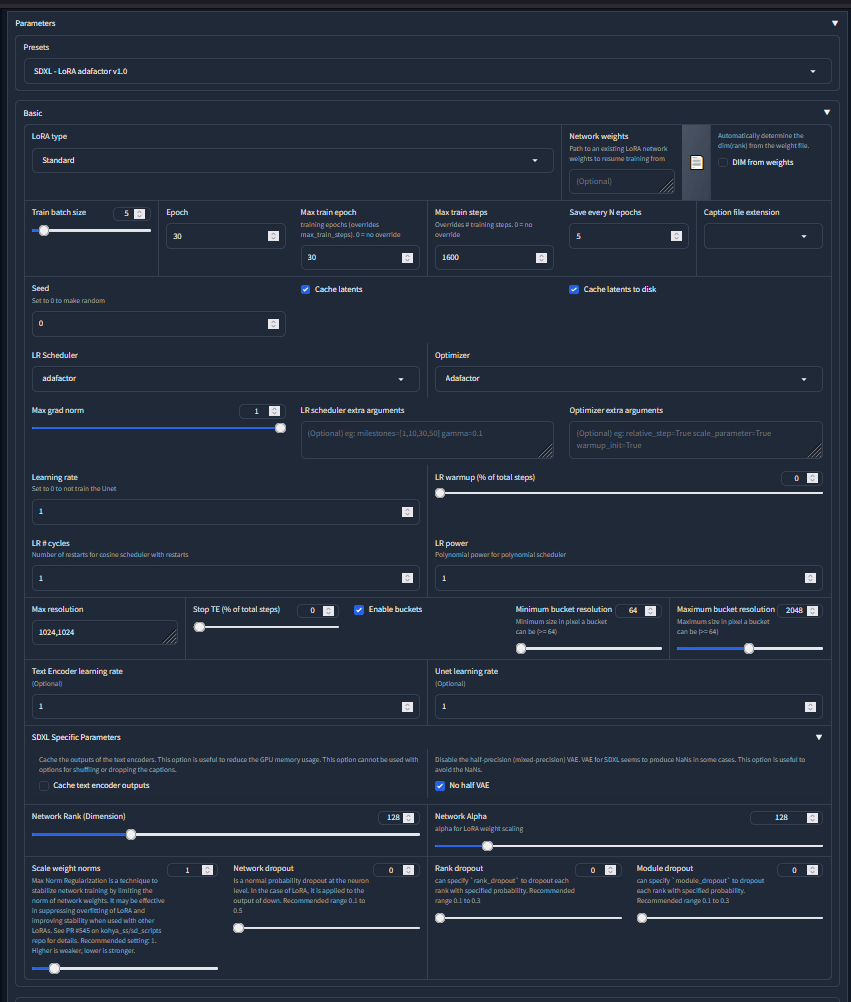
長々と書きましたが、基本的に #sdxl 1.0 LoRA というプリセットの設定のままで大丈夫だと思います。
①各種データ保存用ディレクトリ、②使用するモデル、③conceptsタブでの設定、④学習率 (Learning Rate), エポック数, 学習する画像の解像度、⑤サンプリングタブでの設定、⑥バックアップタブでの設定、⑦LoRA rank と LoRA alpha がその時その時の学習に応じて変えるであろう設定です。変えるときは先の 2 サイトを参考にすることをオススメします。
3. 学習素材の準備
※OneTrainer の設定だけで大分長くなったので、素材用意の過程で使ったフリーソフトや StableDiffusion Web UI の拡張機能の使い方は割愛します。
つくよみちゃん素材の入手
つくよみちゃんはフリー素材キャラクターです。公式サイトの "画像生成AIに対するつくよみちゃんプロジェクトの方針及びガイドライン" を見ますと、企画者である夢前黎 様がご用意されたイラスト素材および つくよみちゃん公式3Dモデル タイプA は "無制限に加工可能かつ i2i や学習に用いて良い" とあります。ということなので、ありがたく拝借しました。かわいいつくよみちゃんが生成できるように活用いたします。

私の中ではつくよみちゃんは和服を着ている娘というイメージなので、和服を着ているイラストを使いました。

イラストだけでは頭の部分の学習が難しいだろうと踏んで、撮らせて頂きました。
つくよみちゃん素材の水増し
枚数が心許ない気がしたので、フリーの画像編集ソフトである PhotoScape X を用いて画像を回転させたり切り出したりして枚数を増やしました。
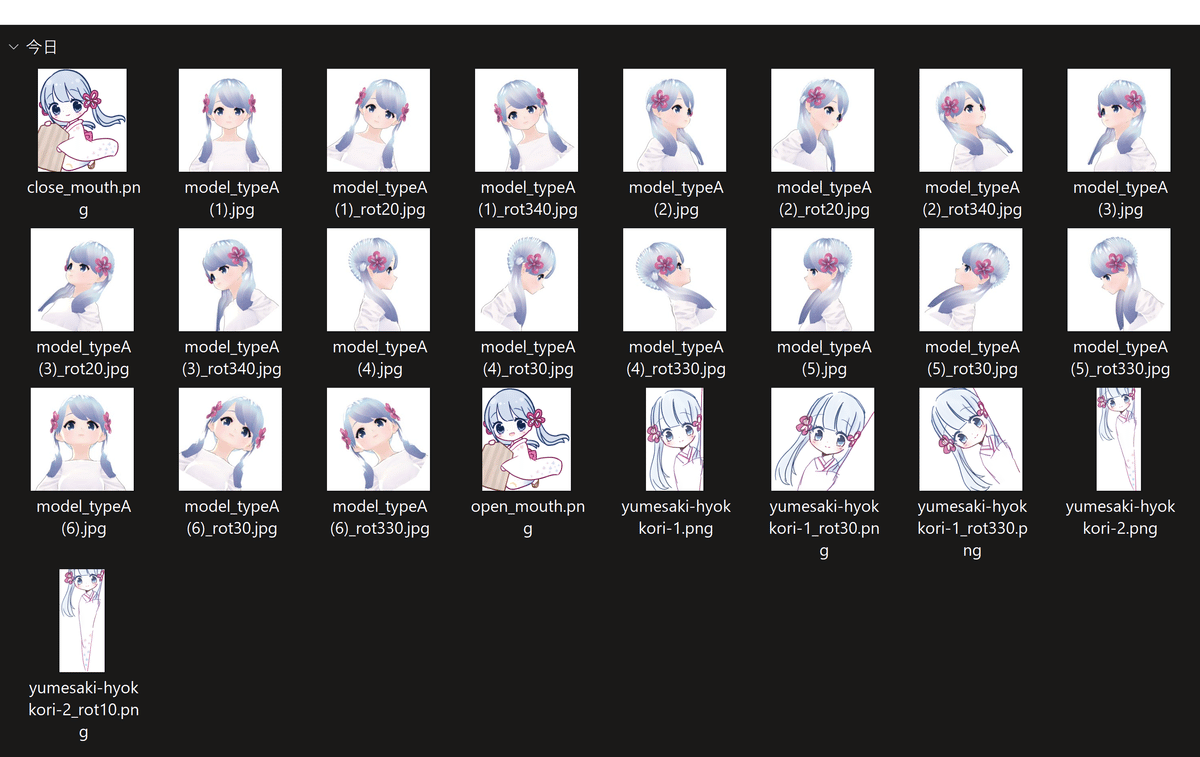
また、和服のイラストは隠れているところが多いので、i2i の inpaint でいい感じに補完された画像が出るまでガチャりました。
学習素材は計 32 枚となりました。
用意した素材に自動でタグを付け、タグを消す
Stable Diffusion web UI の拡張機能である stable-diffusion-webui-dataset-tag-editor で自動でタグを付けしました。Interrogators は DeepDanbooru と wd-v1-4-vit-tagger を使いました。
"TsukuyomiChan" というトリガーワードを全て画像のタグに付け加えてから、タグを書き込んだテキストファイルを作りました。
これらから、つくよみちゃんとして学習させたい要素のタグを消します。
ここで、LoRA 作成あるあるだと思いますが、自動でついたタグのうち、どれを消したら良いのでしょうか。
私が色々調べた中ではエマノン様が書かれた記事の解説が一番しっくりきました。
「用意した画像」と、「用意した画像に対応するテキストファイルに書かれたタグで生成された画像」との差分が学習されるというイメージのようです。
つまり、
テキストファイルから学習させたい要素のタグを消しておく。
タグがないので学習したい要素を含んだ画像が生成できなくなる。
入れても生成画像に影響を与えない (意味を持たない) ワードを仕込んでおくと、「用意した画像とタグから生成した画像の差は、このワードによって引き起こされてるんですね!分かりました!覚えます!」となる。
意味を持っていなかったワードに差分が学習され、トリガーワードに進化する。
トリガーワードをプロンプトに入れると、学習したことを出してくれる LoRA が出来上がる。
といった感じなのでしょう (あくまでもイメージです)。だから、「学習させたい要素のタグを消しましょう!」とよく言われてるんですね。
というわけで、今回はつくよみちゃんをつくよみちゃんたらしめている要素である (と私が思っている)「blue eyes, blue hair, long hair, flower, hair flower, japanese clothes, kimono, twintails, white kimono, obi, pink kimono, wide sleeves, floral print, print kimono, pink bow, pink flower, puffy sleeves, bow, yukata」のタグを消しました。
タグを書き込んだテキストファイルを作成して、つくよみちゃんの素材フォルダが出来上がりました。
4. concept をセットしてスタート!
general タブ
OneTrainer の concepts タブを開き、add concept を押します。
追加された concept (虹色の玉) をクリックします。
素材フォルダのパスを general タブ内のフォルダ指定部分に書き込みます。画像が読み込まれたら、concept のサムネイルが虹の玉から変わるはずです。
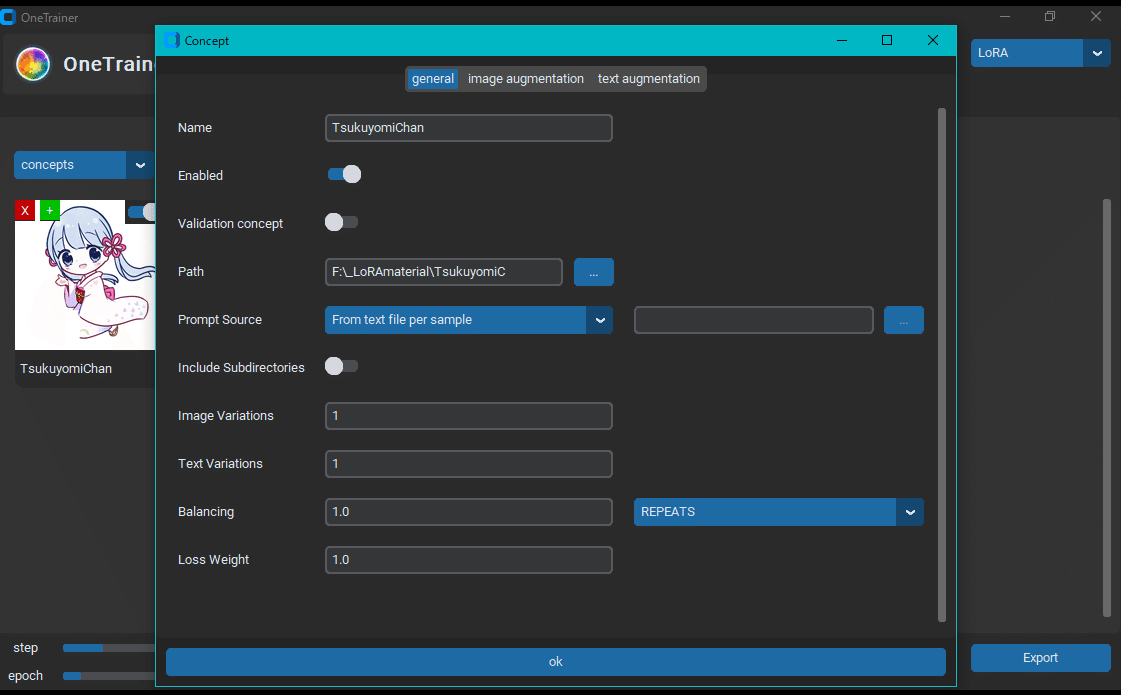
他の設定については wiki から引用します。
※DeepL で訳した文を元にした意訳を記しています。
※把握しておくと良さそうな部分だけ載せてます。
Name (デフォルト : 空欄)
ここにはコンセプトの名前を入力できます。名前を選択しない場合、ウィンドウを閉じたとき、入力したフォルダ名がデフォルトになります。
Prompt Source (デフォルト : from text file per sample)
このドロップダウンには3つのオプションがあります。
1. From text file per sample - 0001.jpg はプロンプトとして 0001.txt ファイルを使用します。複数のキャプションを追加することもできます。
2. From single text file - ドロップダウンの右側の欄で指定されたテキストファイルのプロンプトが、すべての画像に使用されます。
3. From image file name - tag1 tag2 tag3.jpg というファイル名のとき、tag1 tag2 tag3 がプロンプトとして使用されます。
Include Subdirectories (デフォルト : False)
このトグルを有効にするとサブディレクトリを使用することができますが、OneTrainer は内部管理のためにそれらを 1 つの concept として扱います。
Image Variations (デフォルト : 1)
Text Variations (デフォルト : 1)
Balancing (デフォルト : 1 Repeats)
数値とドロップダウンメニューは、concept のバランスをコントロールします。その名の通り、1 つのコンセプトと他のコンセプトとのバランスを変えられます。これを使うケースのひとつは、正則化画像です。ソース画像が 100 枚で、正則化画像が 10,000 枚ある場合、エポックごとに正則化画像の一部の画像だけを使用することができます。この設定には2つの方法があります。
1. Repeats - エポック毎にソース画像の総数に入力値を掛けただけの枚数が使用されます。例えば、10,000 枚の画像があり、.01 を使用した場合、100 枚の画像がエポック毎に使用されます。
2. Sample - OneTrainer に、各エポックに使用する画像の数をはっきりと指示します。例えば 100 を指定すると、常にエポックごとに 100 枚の画像を使用します。これは 10,000 枚でも 20 枚でも同じです。
Loss Weight (デフォルト : 1)
入力のバランスをとるもう一つのテクニックです。この使用例としては、正則化画像がトレーニングに必要以上に影響している場合、正則化画像に 1 より小さい値を使用します。
image augmentation タブ
image augmentation タブでは、画像を回転させたり、色の変化を反映させたりしてから学習に使うように設定できます。
Random を有効にすると文字通りランダムに反映します。Fired を有効にすると入力した設定を反映させたままになります。Update Preview をクリックすれば、どのように変わるのかが見られます。お好みで調整して反映してください。

オーバーライドは説明を見ても理解できませんでした。
Update Preview で見られない (と思われる) ものについては wiki から引用します。
※DeepL で訳した文を元にした意訳を記しています。
Crop Jitter (デフォルト : オン)
OneTrainerは画像に最も近い標準解像度のバケットを選択しようとしますが、画像をトリミングする必要があるときにこのオプションが選択されている場合、画像が異なるものになるように、中央以外のトリミングをランダムに実行します。
Resolution Override (デフォルト : Off - 512)
この機能を使用すると、コンセプトのトレーニング解像度をオーバーライドすることができます。無効にすると、One Trainer は画像をトレーニング解像度に再スケーリングします。有効にすると、2つの目的に使用できます。
1. マルチ解像度トレーニング (カンマで区切られた複数のトレーニング解像度で) : コンセプトの画像のうち、同じ解像度の画像を使用します。
2. 画像のアップスケーリングを防ぐ。512 または 256 の画像をアップスケールされずに 1024 (ターゲット解像度) でトレーニングすることができます。トレーニングは 512 または 256 で行われます。低画質の画像に役立ちます。
「回転させられるなら、何で予め回転した画像なんか作ったの?」と思われることでしょう。
OneTrainer による回転では、画像が無くなった部分の背景が真っ黒になります。どうもこの黒い部分も学習されるようで、角から辺にかけて黒い部分が入った画像が生成されるようになったことがありました。
なので、今回は回転済みの画像を予め作ることにしたというわけです。
設定次第では黒い部分は無視されるのかもしれませんが、2024 年 10 月現在の私は平気になる設定を把握できておりません。
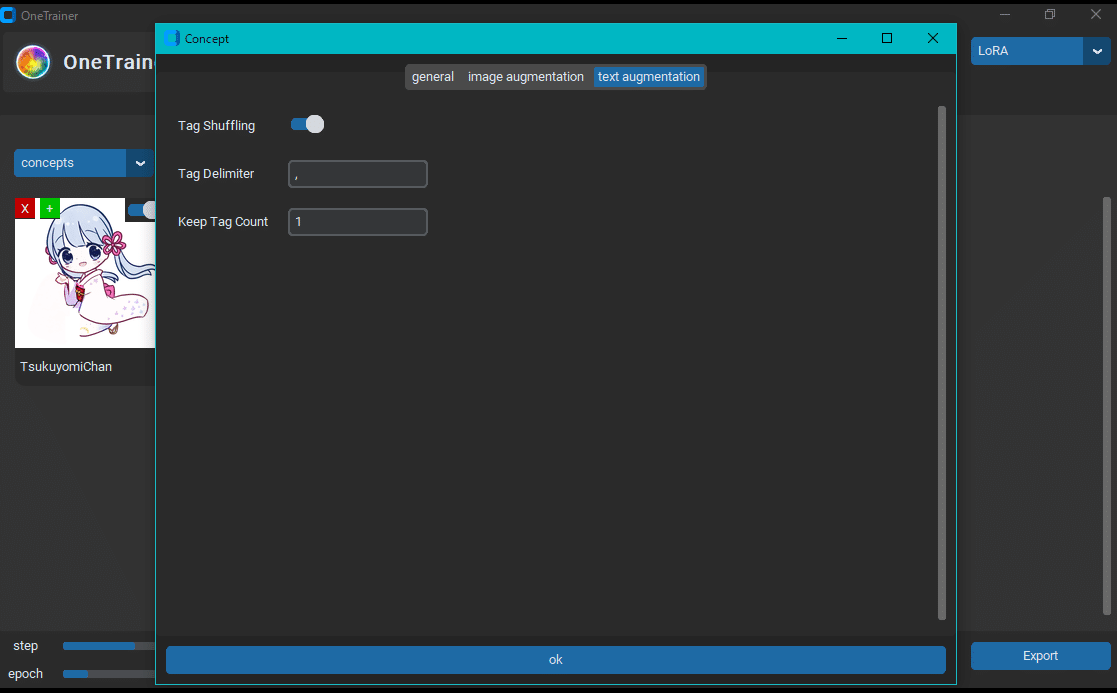
Text Augmentation タブ
text augmentation タブではタグをシャッフルするかを設定できます。プロンプトの順番を変えると生成される画像も少し変わりますので、シャッフルした方が良いのではないかと思います。
↓DeepL で訳した文を元にした wiki の文の意訳
このタブは、タグのシャッフルを目的とします。Keep Tag Count は、シャッフルさせない左からのタグの数を定義します。タグの区切り文字は 1 つだけ指定できます (デフォルトはカンマ)。
上記 3. で記した設定と concept のセットが済めばあとは Start Training をクリックするだけです!
学習開始ぃ!
スタート後に step 数が刻まれ始めてから、右下の Tensorboard をクリックすると Web ブラウザが起動して学習の進み具合が見られます。Sampling タブで設定した保存フォルダには、設定した間隔毎に生成された画像が保存されているので、それを見ても進み具合が分かります。
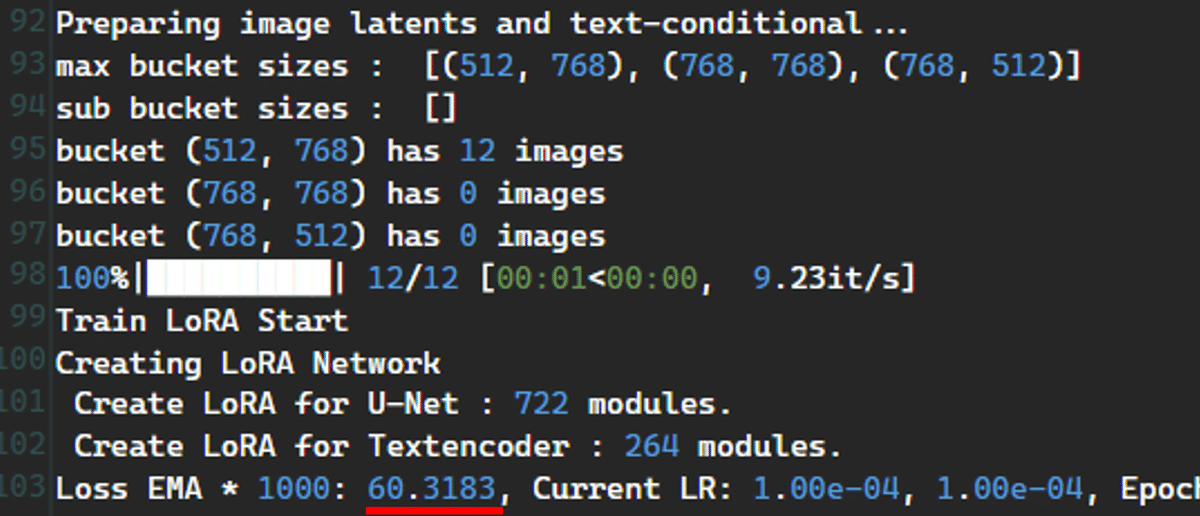
TrainTrain では私のマージモデルをベースにすると nan と表示されましたが、OneTrainer では問題なく学習が進みました。
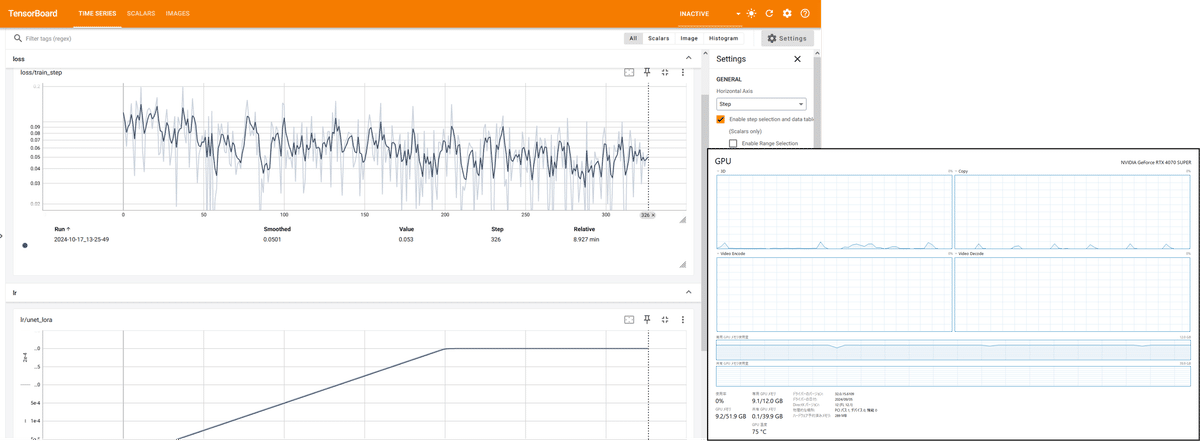
今回の設定で学習させると VRAM は 10GB 程度使われていました。
ちなみに、今回用意した画像でバッチ数 4 の設定では、1 エポックあたりのステップ数が 6 になりました。エポック数は 300 にしましたので総ステップ数は 1800 でした。かかった時間は、RTX 4070 SUPER で 50 分でした。
1 エポックあたりのステップ数はどうやって算出されているのかは分かりません。もしかすると、今回の設定では、弾かれた学習画像があったのかも知れません。
算出方法が分からないので、「一度スタートして 1 エポックあたりのステップ数を確認したら即止めて、改めてエポック数を設定する」という手順で総ステップ数を変えました。
なお、これまでの経験から「1800 ステップも踏めばいけるやろ」という感覚になっているので、1800 ステップになるようにしました。200 ステップごとにバックアップしているので、やりずぎていたとしても安心です。
5. 完成した LoRA (LyCORIS) の確認
OneTrainer で LoRA (LyCORIS) が作れた!
200 ステップ毎にバックアップをとっていましたので、それらと合わせて効きを確かめました。
生成は StabilityMatrix で導入した Stable Diffusion web UI by AUTOMATIC1111 で行いました。

思っていたより大分低ステップの時点でつくよみちゃんを覚えてくれていたようです。むしろ、1800 ステップまで学習させた LoRA (LyCORIS) は i2i で作った素材画像のつくよみちゃんがほぼそのまま出てきていますので、過学習してしまったようです。あってよかったバックアップ。
着せ替えできるかどうかも試しました。

これらの生成画像を見た感じでは、髪飾りがちゃんと出ているかつ元画像に近すぎないつくよみちゃんが生成されているので、600 ステップの LoRA (LyCORIS) が一番良さげですかね。
ここまで読んでいただきありがとうございました。
これで OneTrainer を使えるようになりました!🙌
ちなみに、ずっと "LoRA (LyCORIS)" と書いている理由ですが、ここから先の手順によって「OneTrainer で作られるのは LyCORIS のようだ」と分かるからです。 分かる人は目次だけで理由が分かるかもしれません。
もっとこだわりたい!
LoRA (LyCORIS) は完成しましたが、ここでこの 2 枚を比べてみましょう。

背景の絵柄は変わってなさげですが、つくよみちゃんの絵柄は大分違いますね (特に頭)。明らかに学習に使った 3D モデル画像の影響を受けています。
キャラが出るのは良いけど、元のモデルの絵柄が消えるのは嫌だ!
と思われている方は、この先の有料部分を是非ご覧ください。
有料部分の手順をこなすと…

このように、3D モデルの頭感が無くなります!頭だけでなく、襟元のリボンも変わってますね!
この先では、生成に役立った拡張機能やプロンプトの紹介もしますので、ご興味があれば是非!
ここから先は
¥ 300
この記事が気に入ったらチップで応援してみませんか?