高速化おじさんが心がけていること

Supership株式会社でエンジニアをしている中野です。
この記事は、部内勉強会の発表資料を外部公開向けに再編したものになります。
この記事の目的
入社以来、部内に高速化のTipsを情報共有したり、速度に困っているプロジェクトに首を突っ込んで一緒に悩んだりする「高速化おじさん」活動をしてきました。成果が出る"こともある"ので、考え方を共有すると役立つ場面があるかもと思い、まとておくことにしました。
「高速化」とは
この記事では、サーバーで実行されるアプリケーションが
・実行結果をより短い時間で得られるようにすること
・同じ時間で、より多く処理できるようにすること
・単位計算リソースあたりの処理量を増やすこと
を指して「高速化」と呼んでいます。
ニュースサイトで、記事検索APIの応答時間を3秒から0.1秒に縮める
ECサイトの閲覧ログ集計に必要なサーバ台数を10台から5台に減らす
のようなイメージです。
また、今回は物理サーバまたはVM上でアプリケーションを実行することを前提として記事を書いています。 実際にはAWSやGCPなどに用意されたマネージド製品を活用する場面も多いと思いますが、それは今回の記事の対象外です。
なぜ高速化するのか
高速化すると多くのメリットを得られます。例えば、
・ユーザーがアプリケーションを快適に使えるようになる
・インフラコストが安く済む
・改善のための試行錯誤を速いサイクルで回せる
・処理量が多すぎて諦めていたあの機能が実現可能に!!
などです。ただし、
・実現に時間がかかりがち
・実装が複雑になりやすい
という側面もあります。
負の側面を承知してでもメリットを得たい時だけ、高速化を実施することになります。ECサイトを例に極端な例を挙げれば
・ほぼ全員が使う商品検索ページのために1万台のサーバを割り当てており、応答に毎回3秒かかっている
- ユーザーの使用感改善のためにも、事業者のサーバコスト削減のためにも高速化が強く求められる
・月間PVが10のキャンペーンページに2台のサーバを割り当てており、応答に毎回10秒かかっている
- 時間をかけて高速化してもメリットが少ないので、優先度を下げて後回し
となります。
高速化すると決めたら考えること
速い製品を使おう
処理を構成する際、言語標準のライブラリやOSに最初から入っているコマンドをそのまま使うことが多いと思います。調べてみると、使い勝手がほぼ同じでもっと速い製品が見つかることがあります。製品を差し替えるだけで苦労なく速くなるなら、使わない手はありません。世界の開発者たちに感謝!!
ここからは実際に業務で検証した製品をいくつかご紹介します。処理速度のグラフは同じ処理をするのにかかった時間を表しており、全て lower is better です。
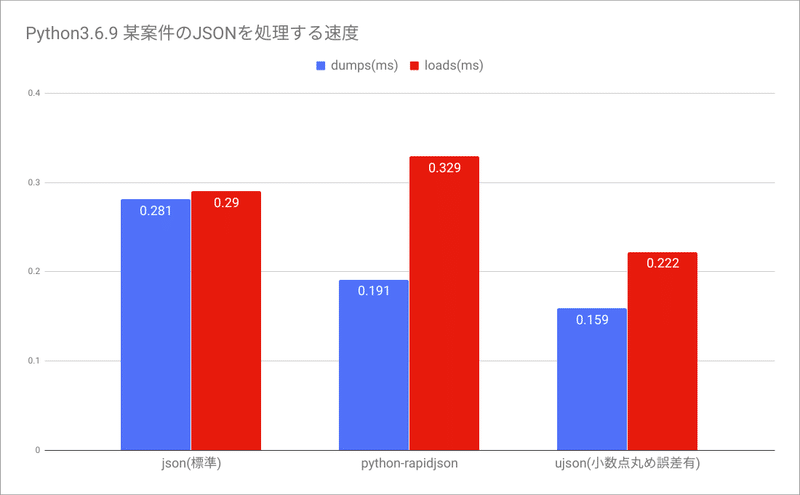
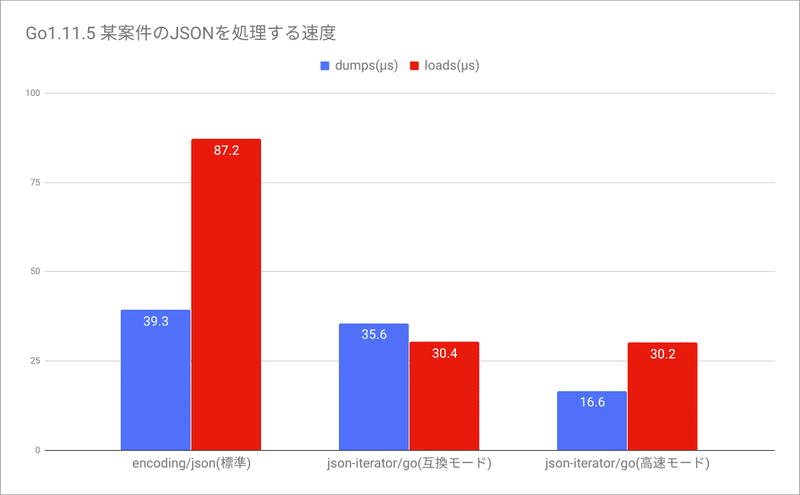
JSONでデータを受け取り、加工し、JSONを出力して後段の処理に渡す処理を書くことがよくあります。 PythonもGoも言語の標準機能としてJSONを扱うことができますが、探してみると同じインターフェースでより高速なライブラリが見つかりました。
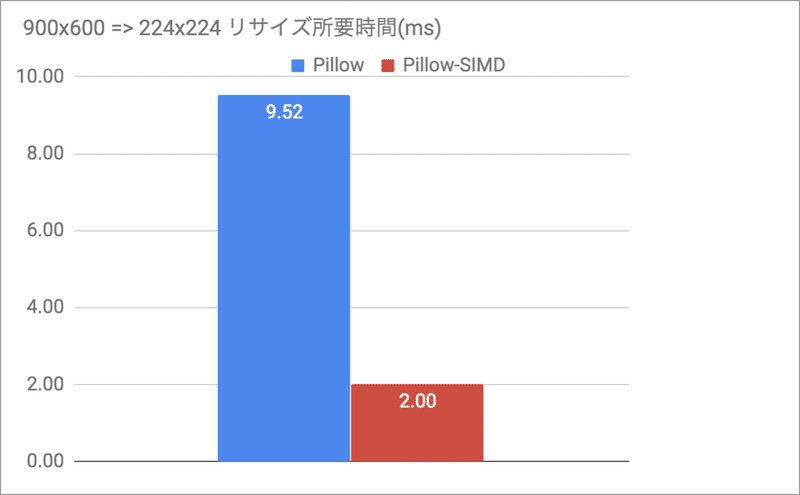
Pythonの画像処理ライブラリで定番のPillowには、SIMD命令で高速化されたPillow-SIMDが用意されています。 amd64 CPU環境であれば、全く同じインターフェースで圧倒的に高速です。
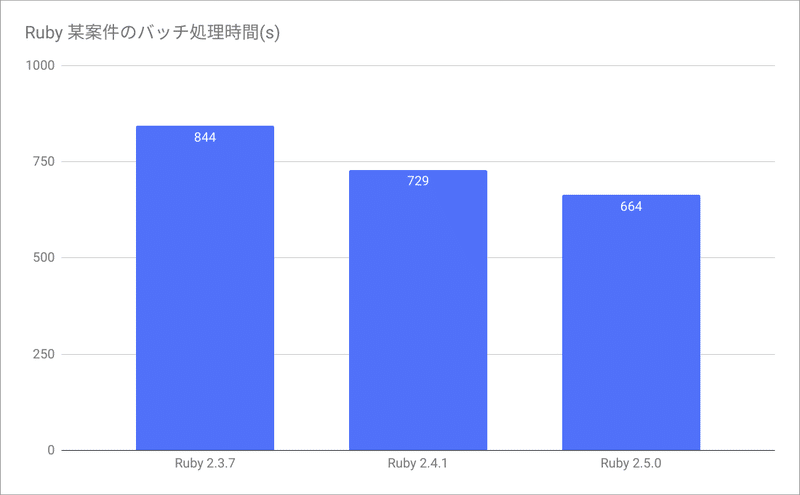
少し古い話ですが、Rubyのバージョンを上げるとアプリケーションを1文字も変えてないのに速くなったことがありました。
Linuxのファイル圧縮にはgzipを使うのがこれまでの定番でした。 最近は圧縮率・圧縮速度・伸長速度の全てでgzipを上回るzstdを使うことが多いのではないでしょうか。
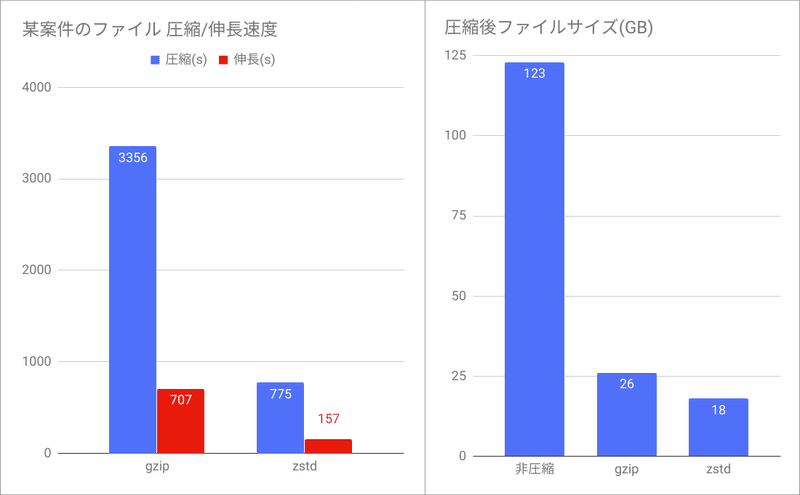
場合によっては、開発言語自体を変える、フレームワーク止めて生で書く、のような判断をすることもあります。 こちらは往々にして開発・保守性が下がるので、得られるメリットとのバランスを見つつ導入可否の判断をします。
処理の流れを整理しよう
材料が揃ったら、繋いで処理を作っていきます。
2つのことに気をつけて処理の流れを整理します。
1. 目的を最小手数で達成する手順を考える
2. 用意された計算機を使い切る
記事が長くなってきたので基本的に箇条書きにします。。
■目的を最小手数で達成する手順を考える
・不要な処理をしない
function filterRecords(records) {
const validRecords = [];
records.forEach(record => {
record.score = heavyScoreFunc(record.rank, record.price);
if (record.hasStock) {
validRecords.push(record);
}
});
return validRecords;
}↓
function filterRecords(records) {
const validRecords = [];
records.forEach(record => {
if (!record.hasStock) {
continue;
}
record.score = heavyScoreFunc(record.rank, record.price);
validRecords.push(record);
});
return validRecords;
}・1回で済む処理は1回だけやる
import MeCab
def tokenize_docs(docs):
tokenized_docs = []
for doc in docs:
tagger = MeCab.Tagger('-O wakati')
tokenized_docs.append(tagger.parse(doc).strip())
return torkenized_docs↓
import MeCab
tagger = MeCab.Tagger('-O wakati')
def tokenize_docs(docs):
tokenized_docs = []
for doc in docs:
tokenized_docs.append(tagger.parse(doc).strip())
return torkenized_docs・アルゴリズム
偉大なる先人たちが編み出した、効率よく処理するための知恵
- 大量の数値を小さい順に並べ替える最速の方法は?
- 大量の文字列からキーワードを高速に探す方法は?
できれば把握しておきたいこと
- 使っている製品はどんなアルゴリズムで動いているのか?
- そのアルゴリズムの特性、長所、短所
用意された計算機を使い切る
・暇な時間を作らない
直列に処理を書くとリソースが余る場合は
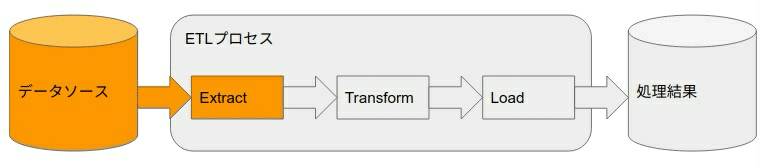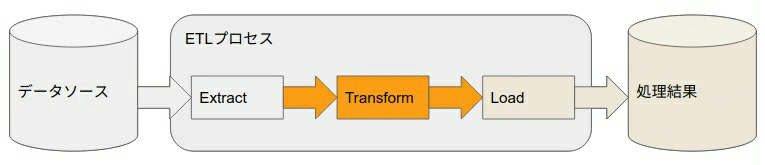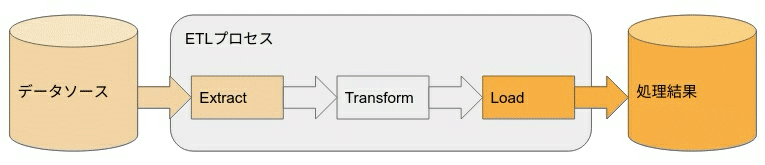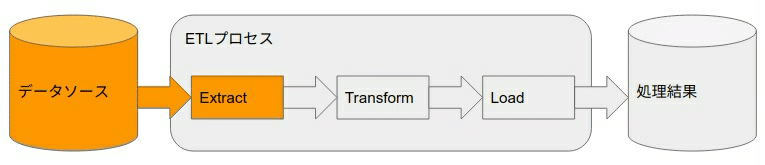
↓ パイプライン化して使い切ります。
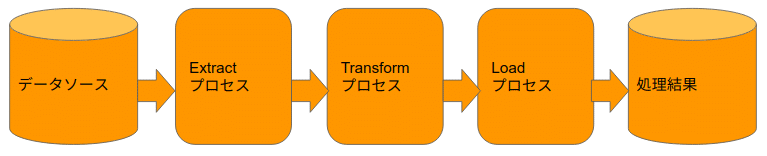
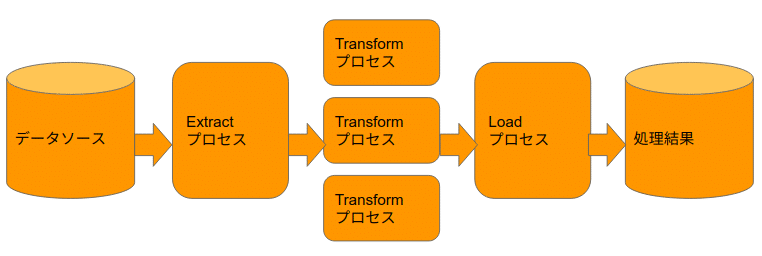
・並行処理
一部の処理が遅い場合は、並行処理します。
・データは塊で取り回す
コップ1杯ずつ水を運ぶよりも
INSERT INTO samples (id, value) VALUES (0, 'sample0');
INSERT INTO samples (id, value) VALUES (1, 'sample1');
INSERT INTO samples (id, value) VALUES (2, 'sample2');バケツにまとめて運ぶほうが効率的です。
INSERT INTO samples (id, value) VALUES (0, 'sample0'), (1, 'sample1'), (2, 'sample2');・その他
- 本当に全データ使う必要ある? サンプリングと推計で良くない?
- 製品の間違った使い方をしてないか
* Index使わずRDBに絞り込み条件指定
* Athenaに大量の行を出力させる
実験、計測、記録
実験
・手法の有効性はタスク、データ、環境に依存して変わる
・良かれと思ってやったことが裏目に出ることは普通
・実際にやってみよう(本番に出す前に)
計測
・定量評価は超重要
・どこがどれだけ遅いのか、内訳も知りたい
- profiling tool
- 自分で計測コードを仕込む
・たとえ直感に反する結果が出ても、計測結果は常に真
・速度に加えてサーバリソースも計測
- CPU使用量
- Memory使用量
-Disk IO使用量
記録
・後で見返せるように、記録を残そう
・人から見えるところに残せば、チームの知見になる
・データ、コード、サーバスペック、結果、セットアップ手順をセットで残す
・自分以外の人が100%再現できる記録を目指す
まとめ
長々と書いてしまいました。まとめるとこういうことです。
・高速化して利益を得られる時だけ頑張ろう。益がないならやめよう。
・速い製品を探してきて使おう。
・必要最小限の処理を、必要最小限の手順で実行しよう。
・計算機を余すことなく全部使おう。
・何をするとどこがどれくらい速くなるか、実験して記録を残そう。
この記事が誰かの役に立つことがあれば幸いです。
この記事が気に入ったらサポートをしてみませんか?