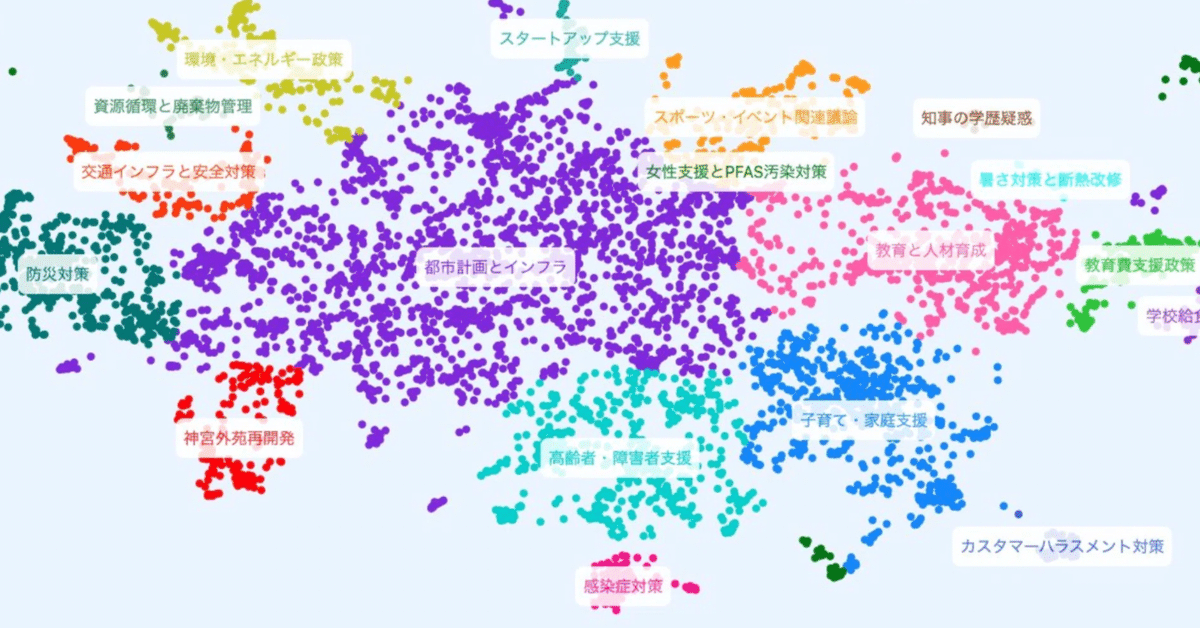
東京都知事選2024におけるTalk to the Cityの活用ノウハウ

安野たかひろ事務所 技術チームの西尾です。自己紹介などは前回の記事 ブロードリスニング:みんなが聖徳太子になる技術をご覧ください。
この記事では東京都知事選2024におけるTalk to the Cityの利用経験に基づいて、ノウハウを共有するために、技術的な解説とソースコードの公開を行います。
Talk to the Cityとは
Talk to the CityはアメリカのNPO法人AI • Objectives • Instituteが提供しているオープンソースソフトウェアです。ソースコードはこちら: GitHub
ライセンスはAffero GPLという強いコピーレフトのものです。それがどういう意味なのかを簡単にいえば「使ったら同じ条件でソースコードを公開せよ」です。なのでこの記事で公開するソースコードも同様にAffero GPLとします。詳細はこちら: GNU Affero General Public License - Wikipedia
Talk to the CityにはScatterとTurboがありますが、今回はScatterを使っています。Turboに関しても試してはいましたが、今回実用的に使うところまでは至りませんでした。
環境構築のトラブル
事前に一人で使ったことはありましたが、今回の都知事選で安野チームの一員としてTalk to the Cityを使う上で、色々と発見がありました。中でもこれは将来他の人が落ちそうな落とし穴としてGit LFSの問題を紹介します。
発生したエラー
Downloading scatter/pipeline/inputs/example-polis.csv (58 KB)
Error downloading object: scatter/pipeline/inputs/example-polis.csv (c30db8c):
Smudge error: Error downloading scatter/pipeline/inputs/example-polis.csv (Object does not exist on the server)Encountered 6 files that should have been pointers, but weren't:
scatter/pipeline/inputs/togikai_gijiroku_questions.csv
scatter/pipeline/outputs/togikai-gijiroku-questions/args.csv …上記のようなエラーが発生して悩まされました。
原因
Talk to the Cityのリポジトリはサンプルデータの配布にGit LFSをつかっています。しかも.gitattributeでワイルドカードでの指定がされているので、サンプルデータに限らず新しいファイルの一部はGit LFS管理下に入っていました。ところがこのことがチーム内で共有されていなかったためにGit LFSをenableした人とそうでない人が混在し、一部のファイルはポインターだけあって実体がない状態、一部のファイルはポインターのはずなのに実体がある状態になっていて、その不整合のためにトラブルが起きていました。
解決
解決策は二つありました。
案1: Git LFSを使わない側に倒す。現状のユースケースだとそれで問題なく進められると思います。が、100%大丈夫という自信がなくて、データが巨大になった時にGitHubにpushできないエラーになるはず、分析結果がどの程度のサイズまで大きくなるかが初期時点ではわかりませんでした。
案2: Git LFSを徹底する。しかし、リポジトリはすでに不整合が発生しているのでさらに見慣れないエラーが発生する可能性が高くて分析プロセスが止まるリスクがあります。
このトラブルは選挙戦序盤の時間がない時に起きたので、数日止まることが出足の遅さとして大きなダメージにつながることが懸念されました。そこで案1を選びました。選挙戦の間に30件以上のレポートを作成しましたが、データサイズの問題は発生しませんでした。
具体的アクション: scatter/.gitattributes, scatter/pipeline/inputs/example-polis.csv, scatter/pipeline/inputs/example-videos.csv の削除
内部向けプレビューサーバの作成
自分一人で試している時には気づかなかったのですが、チーム内でTalk to the Cityを使う場合、「Aさんがレポートを作る」「Bさんがそれを見る」を実現するためには、Aさんが全世界公開することなく結果をBさんに共有する手段が必要です。
Talk to the Cityは静的レンダリングを行うので、自分の手元でプレビューするなら python -mhttp.server でサーバを立ち上げるだけでいいし、公開するなら.nojekyll ファイルを置いてGitHub Pagesでホストすればいいです。しかし非公開のまま他人にシェアしようとしたとき、GitHub Pagesでプライベートリポジトリからデプロイしようとすると有償プランが必要になることがハードルになりました。
解決
内部向けプレビューサーバを開発してNetlifyでホストしました。Netlifyでもprivateリポジトリからの継続的デプロイは有償機能なのですが、1ヶ月の試用期間があったので選挙期間中は無償で実行できました。
これにより、誰がレポートを作成してもGitHubにpushすれば数分で公開した場合と同様の見た目でプレビューできるパーマリンクURLが生成され、Slackでシェアできるようになりました。最終的に色々なニーズに合わせて30件以上のレポートが作成されました。
おまけで一覧のページも自動更新するようにしていましたが、一覧に表示するものはレポートのフォルダ名ではなく人間可読なタイトルにした方がよかったかもね、と今回見返していて思いました。
ソースコード
設定

日本語化パッチ
Talk to the Cityは多言語化されています。これは言語の選択肢を指定すると、それぞれの言語へLLMを使って翻訳を行う仕組みです。
ところがこの設計は暗黙に英語をメイン言語と仮定しているように見えます。日本語をデフォルトにする機能が(たぶん)なく、レポートを都民の皆さんにシェアした場合に、まず英語で表示されてから右上の言語切り替えボタンで日本語に切り替える形になりそうでした。これは説明が複雑で、正しく伝わらず、英語画面を見て離脱されるのでは、と心配になりました。
これをどう解決するかは悩ましい問題です。あらゆる人の意見を聞くブロードリスニングの思想としては、あらゆる言語で意見を受け付け、あらゆる言語に翻訳して提供するのが理想です。しかし、それには無限にコストが掛かります。
今回は初の試みなので「まずは最も低コストな方法で実験をし、実験を繰り返して改善すべきだろう」と考えました。であるなら不確実性を拡大する翻訳プロセスを介在させない方が良いと判断し、日本語のみで提供することにしました。
解決
LLMによる翻訳プロセスを介在させずに、英語で記述されているUIをデフォルトで日本語に翻訳させるために、多言語化のコードをハックしました。また、UIの日本語訳データをコードに埋め込みました。
上記のパッチは git am コマンドでapplyできます。
最後に
実は私は本家Talk to the Cityのコントリビュータでもあるのですが、日本人が日本語で使っていく上ではまだまだ罠が多いと感じています。

ブロードリスニングは、為政者が使うことによって多くの人の声を聞くことができるようになるだけでも価値がありますが、さらに先の理想として多くの人が使えるようになることが好ましいです。多くの人の声を聞いて理解する人が増えることが、社会をより良い方向へとアップデートすることにつながるからです。
そのためにも、Talk to the City もしくはこの種のブロードリスニングのツールをもっと多くの人が使って、改善していけると良いなと思っています。ツールがオープンソースであることによって、みんなで改善していくことができます。新しいより良い社会をプログラミングによって実装できる時代が来たのです。
最後にオードリー・タンのドキュメンタリーの一節を引用します。
Q: オードリー・タンさん、世界の民主主義に対する最大の希望は何ですか?
A: 人々が民主主義を社会的技術と捉え、共に構築し、今ここで改善できるものだと認識することです。私たちは政治システムをコーディングすることができます。