
自動車メーカーのロゴ判別

はじめに
同じような形をした自動車を見て、AIはその自動車がどこのメーカーであるか、判別することができるのか?
先日上場したAIプログラミングスクール「aidemy」で自動運転の仕組みに繋がるCNN (Conbolutional Neural Network)の画像認識を学んでいた私は、自動車から見えるメーカーロゴの画像を集め検証。そのモデルを使ったWebアプリを作ることにしました。
実行環境
・Visual Studio Code
・Google Colaboratory
1.データ収集
まずは学習の元となる自動車ロゴの画像収集です。最近ではEVの開発が目覚ましい自動車業界。EVメーカーも含め代表的な自動車メーカーのロゴをできるだけ車体も見える画像を求めてWebスクレイピングしました。検索キーワードは"自動車メーカー名称 + logo + on the car"です。ピックしたのは「テスラ」「フォルクスワーゲン」「メルセデス・ベンツ」「ホンダ」「トヨタ」「日産」「ポルシェ」「レクサス」の8メーカーのロゴ。
google.colabをインポートして自分のドライブにマウントします。
from google.colab import drive
drive.mount('/content/drive')2.画像アップロード
検索で「on the car」と付けましたが、ほとんどはロゴのアップ画像でした。心配していたような遠目の車体に小さく見えるロゴといった、判別しづらい画像はあまりなくて、そのため間引きしたのはほんの少しでした。その点では楽ではありましたが、本来は車体(ボディ)がもっと大きく見える画像が好ましかったと思います。ドンピシャの画像が多数出てくる検索方法についても別の機会に学んでおきたいものです。
!pip install icrawler
from icrawler.builtin import BingImageCrawlersearch_word = "tesla logo on the car"
crawler = BingImageCrawler(storage={'root_dir': "/content/drive/MyDrive/Aidemy/Tesla"})
crawler.crawl(keyword=search_word, max_num=100)8種のロゴ画像はそれぞれ100枚を上限にしました。


3.画像をリストに入れる
スクレイピングしてドライブに保管した画像を今度はリストにインポートします。しかし、ここでエラーが・・・なぜだろう。

自分で調べても分からず技術カウンセリングを受けます。すると、画像を取りにいくパスに「/」(スラッシュ)が1つ足りないというシンプルなことでした。 /content/drive/MyDrive/Aidemy/Tesla/と最後に「/」を付けていなかっただけ。Teslaディレクトリの中に画像が集まっているのですから必要です。コードを修正、再度セルを実行。ようやく走り出しました。
4.インポート
pythonで画像認識を行うために専用のライブラリをインポートします。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers5.ロゴの格納
スクレイピングしたロゴをドライブに格納します。このとき画像サイズを最初は50にしていました。しかしのちに紹介するモデル学習の結果、正解率が低かったため150に変更しました。確かに50pixelって小さい。
#ロゴ画像の格納
drive_Tesla = "/content/drive/MyDrive/Aidemy/Tesla/"
drive_Mercedesbenz = "/content/drive/MyDrive/Aidemy/Mercedes-benz/"
drive_Honda = "/content/drive/MyDrive/Aidemy/Honda/"
drive_Toyota = "/content/drive/MyDrive/Aidemy/Toyota/"
drive_Lexus = "/content/drive/MyDrive/Aidemy/Lexus/"
drive_Porshe = "/content/drive/MyDrive/Aidemy/Porsche/"
drive_Nissan = "/content/drive/MyDrive/Aidemy/Nissan/"
drive_Volkswagen = "/content/drive/MyDrive/Aidemy/Volkswagen/"
image_size = 150
#os.listdir() で指定したファイルを取得
path_Tesla = [filename for filename in os.listdir(drive_Tesla) if not filename.startswith('.')]
path_Mercedesbenz = [filename for filename in os.listdir(drive_Mercedesbenz) if not filename.startswith('.')]
path_Honda = [filename for filename in os.listdir(drive_Honda) if not filename.startswith('.')]
path_Toyota = [filename for filename in os.listdir(drive_Toyota) if not filename.startswith('.')]
path_Lexus = [filename for filename in os.listdir(drive_Lexus) if not filename.startswith('.')]
path_Porshe = [filename for filename in os.listdir(drive_Porshe) if not filename.startswith('.')]
path_Nissan = [filename for filename in os.listdir(drive_Nissan) if not filename.startswith('.')]
path_Volkswagen = [filename for filename in os.listdir(drive_Volkswagen) if not filename.startswith('.')]
#各種ロゴの画像を格納するリスト作成
img_Tesla = []
img_Mercedesbenz = []
img_Honda = []
img_Toyota = []
img_Lexus = []
img_Porshe = []
img_Nissan = []
img_Volkswagen = []6.画像の読み込み
For文で8種全ての画像を読み込んでいきます。
for i in range(len(path_Tesla)):
img = cv2.imread(drive_Tesla + path_Tesla[i]) #画像を読み込む
img = cv2.resize(img, (image_size, image_size)) #画像をリサイズする
img_Tesla.append(img) #画像配列に画像を加える
for i in range(len(path_Mercedesbenz)):
img = cv2.imread(drive_Mercedesbenz + path_Mercedesbenz[i])
img = cv2.resize(img, (image_size, image_size))
img_Mercedesbenz.append(img)
for i in range(len(path_Honda)):
img = cv2.imread(drive_Honda + path_Honda[i])
img = cv2.resize(img, (image_size, image_size))
img_Honda.append(img)
for i in range(len(path_Toyota)):
img = cv2.imread(drive_Toyota + path_Toyota[i])
img = cv2.resize(img, (image_size, image_size))
img_Toyota.append(img)
for i in range(len(path_Lexus)):
img = cv2.imread(drive_Lexus + path_Lexus[i])
img = cv2.resize(img, (image_size, image_size))
img_Lexus.append(img)
for i in range(len(path_Porshe)):
img = cv2.imread(drive_Porshe + path_Porshe[i])
img = cv2.resize(img, (image_size, image_size))
img_Porshe.append(img)
for i in range(len(path_Nissan)):
img = cv2.imread(drive_Nissan + path_Nissan[i])
img = cv2.resize(img, (image_size, image_size))
img_Nissan.append(img)
for i in range(len(path_Volkswagen)):
img = cv2.imread(drive_Volkswagen + path_Volkswagen[i])
img = cv2.resize(img, (image_size, image_size))
img_Volkswagen.append(img)7.学習データと検証データの準備
このあと計算をしていくため画像の配列をX、yに代入していきます。VGG16を使った転移学習も行います。
#np.arrayでXに学習画像を代入
X = np.array(img_Tesla + img_Mercedesbenz + img_Honda + img_Toyota + img_Lexus + img_Porshe + img_Nissan + img_Volkswagen)
#yに正解ラベルを代入
y = np.array([0]*len(img_Tesla) + [1]*len(img_Mercedesbenz) + [2]*len(img_Honda) + [3]*len(img_Toyota) + [4]*len(img_Lexus) + [5]*len(img_Porshe) + [6]*len(img_Nissan) + [7]*len(img_Volkswagen))
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone-hotベクトルの形にする
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#input_tensorの定義をして、転移学習のモデルとしてVGG16を使用
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)8.モデルの定義
今回はVGG16を使っているのでflatten関数で配列を1次元にします。
#モデルの定義、活性化関数シグモイド
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='sigmoid'))
#top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='sigmoid'))
#top_model.add(Dropout(0.5))
top_model.add(Dense(8, activation='softmax'))
#vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#19層目までの重みをfor文を用いて固定
for layer in model.layers[:19]:
layer.trainable = False実はこの上の重みを固定するところで、つまずきました。というのも最初は15層目までの重みしか固定していなかったのです。
9.モデル構造の確認
model.summaryでモデル構造とパラメーター数を確認します。
#学習の前に、モデル構造を確認
model.summary()
10.モデルのコンパイルと学習
技術カウンセリングで教えてもらいました。ここはAdamが強力だと。そしていよいよコンピュータに学習させます。epoch数は50にしました。
#コンパイル Adamに変更
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])
#モデルの学習
history = model.fit(X_train, y_train, batch_size=1, epochs=50, verbose=1, validation_data=(X_test, y_test))
11.精度の評価
さて精度のほどは。
#精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
#正解率の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()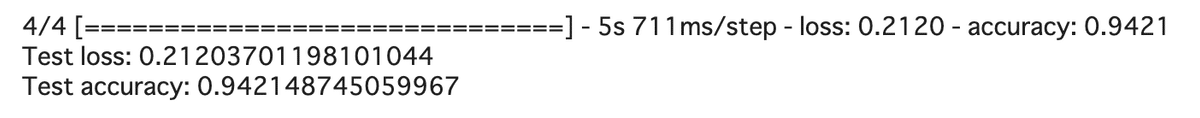
重みを15層目までにしていたときはaccuracyが15%しかなかったのですが、19層目までとしたら94%まで一気に高まりました。

もっとも正解率は100%に近づきましたが、この間にスクレイピングした画像であまりにもロゴと関係のないもの(さまざまなメーカーロゴが入り混じった画像や、指定したメーカーの車両だがロゴが全く映っていない画像)については間引いたり、モデルの畳み込み層を増やしたり、epoch回数を増やしたりと、さまざま試みて80% => 84% => 94%とだんだん上がっていきました。
ロゴ(メーカーさんのエンブレム)の雰囲気はどのメーカーも似ています。とくにホンダとトヨタ。線画のあたり、人間には区別がついても、コンピュータ的にはかなり似ているんじゃないかな。そう思いながら作っていたので、まだ6%間違う可能性が残っているものの、94%までこれらをちゃんと識別してくれているのはけっこう素晴らしいことなのでは。そんなふうに思いました。
12.Flask側を作成してrenderでデプロイ
自動車ロゴを識別するモデルができたので、画像検知ができるフレームワークFlaskを使ってアプリ化、そしてrenderを使ってWebに公開します。renderとはWebアプリを手軽に公開できる環境を提供しているサービスのことです。renderする前にgoogle colabで作成したモデルを保存し、モデルのダウンロードを行います。
#モデルの保存
from google.colab import files
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
#重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' ) 
Aidemyの教材を参考にしながらVScodeでアプリ表面上のレイアウトとなるindex.html、デザインを指定するstylesheet.cssを書き、読み込みライブラリを記したrequirements.txtのファイルを用意。そしてアプリとしてメインで動くcarlogo.pyを次のように作成しました。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["テスラ","メルセデスベンツ","ホンダ","トヨタ","レクサス","ポルシェ","日産","フォルクスワーゲン"]
image_size = 150
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5', compile=False) #学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
最後にrenderにターミナルからデプロイ。公開することができました。

自宅でクルマのロゴを撮影。

アプリに画像をアップロードして、いざ識別。

答えは「ホンダ」ということで・・・正解です!
以上、8種の自動車メーカーロゴ識別アプリが完成しました。今回は画像サイズやepoch数、重みの固定層を変更することで精度を高めることができましたが、他にも活性化関数、損失関数を変更したモデルを試すことで正解率を高めることができます。
結果と考察
目次の「11.精度の評価」でも述べましたが、スクレイピングした画像は最初はロゴと関係のない画像もいくらか混じっていました。それらを間引く前と後では正解率の差は十数%もあったわけで、事前処理がいかに大事かを身をもって学びました。
画像の数、事前処理
パラメーター、重みの固定、epochs数
これらをさまざまな角度から目標をとらえ改善していく作業の必要性を強く感じることができました。今後は、
指定した8メーカー以外のロゴが入ってきた場合の対処法
画像をもっと増やすことで精度を高める方法もあったこと
もっと遠目から見た画像であってもロゴを判別できる工夫
この3点にも視野を広げてアプリの構想をアップデートさせていければと思っています。まだまだ学びたいことが山ほどあります。
おわりに
今回aidemyの課題を通じて、ディープラーニングやAIの体系的なしくみを学ぶことができました。また知識だけでなく、実際に手を動かして数々の課題をクリアしていくうちに、基本的なモデルの構築やアプリのフロントサイドおよびサーバーサイドのプログラム、そしてWebへのデプロイまで実践的かつ楽しい経験を積むことができました。
詰まったときはGoogle meetで顔を突き合わせて質問ができる技術カウンセリングを受けました。技術カウンセリングの存在は私にとって大変貴重なものでした。そこには独学では到底達成できない学びのスピード感を得ました。
Python自体はPyQ等で勉強して慣れてはいたのですが、aidemyの他の講座やKaggleで一層ブラッシュアップさせていきたいと思います。次は自然言語処理、自動運転、自動翻訳、E資格対策に取り組んでいきます。
以上、ながーい報告文をここまで読んでくださりありがとうございました。
https://flask-car-logo-app.onrender.com
制作したアプリはこちらです。 ↑