Swarm - シンプルアイデアからマルチエージェントを動かせる

2024年10月にOpenAIは「Swarm」のレポを公開しました。その目的は、実験用に特化した軽量なマルチエージェントのオーケストレーションです。この記事では、Swarmを使ってどのようにマルチエージェントシステムを構築するかを解説します。行きましょう。
前提知識
LLM基礎知識
最近では、ChatGPTやClaudeなどのLLM(大規模言語モデル)が広く知られています。これらのモデルは、大量のデータから学習し、ユーザーの質問に答えます。しかし、LLMがまだ学習していない最新情報や、専門的なデータ、組織内部のデータ等は理解できません。この場合、LLMは「わからない」と答えるか、間違った情報を返すこと(ハルシネーション)があります。
この問題を解決するためには、以下の方法があります。
❶質問にできるだけ多くのコンテキスト情報を提供する。(ただし、消費するトークン数は多くなります。)
❷関数呼び出し(function calling):特定の関数を定義して、その関数は必要な情報を返す
❸外部の知識を参照する(RAG):必要な情報はベクター化されて、外部のストレージで保存する、LLMはそのストレージからデータを取得する。
この記事では、❷の方法をサンプルプログラムとして使用します。
関数呼び出し(function calling)
LLMは外部関数を利用することで、特定の情報を取得できます。たとえば、OpenAIのChatGPTは、リクエスト時に関数を呼び出すことが可能です。以下の例を見てみましょう。
def get_temperature(location: str):
"""
Get the temperature of a specific location
"""
if location == "Tokyo":
return 18
elif location == "Hanoi":
return 25
return 20
この関数に対応するスキーマは以下のようになります。
{
"type": "function",
"function": {
"name": "get_temperature",
"description": "Get the temperature of a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string"
}
},
"required": [
"location"
]
}
}
}
このスキーマにより、LLMは関数の情報を理解し、質問に応じて関数を呼び出すことができます。説明文が明確であるほど、LLMの判断も正確になります。

画像を見るとLLMに直接に対話ではなく、ユーザーはエージェントとコミュニケーションします。関数を呼ぶかどうかはLLMの判断です。(タスクを実行することに特化したLLMという文脈で、これ以降はLLMではなくエージェントという言葉を使います。)
もちろん数の数が多くなるとAPIのリクエストにインプットデータを上がって、インプットのトークンのコストも上がります。
エージェントの基礎知識
関数呼び出しは便利ですが、実際のアプリケーションでは「東京の温度は?」という単純な質問だけではありません。タスクが複雑になると、システムプロンプトの内容も長くなりがちです。抽象的な説明ではエージェントの理解も抽象的になってしまい、エージェントはハルシネーションを起こしやすくなります。そのため、ステップごとに処理することで精度を上げることが重要です。OpenAIはこの複数ステップのタスクを「Routine(ルーチン)」と呼んでいます。
生活内で複数ステップのタスクはたくさんあります。例えば、「良い目標を設定する」ためのステップは以下のようになります:
ステップ1:チーム・組織の目標を確認する
ステープ2:次に目指すべきレベルを確認する
ステップ3:目標を立てる
ステップ4:メンターからレビューをもらう
ステップ5:レビュー内容を目標に反映させる。
ステップ6:(任意)目標をチーム・組織に共有する
複数ステップに分けることで、各ステップの役割が小さくなり、責務が明確になります。
しかし、各ステップがもっと複雑になったら、どうですか。その時、実施しているステップがどこかを判断する仕組みは難しくなる。一般的に、エージェントは複数の分野を同時に理解するよりも、特定の分野に特化して理解する方が精度が良くなる傾向にあります。
Swarmとは?
Swarmはfunction callingをベースの技術として、エージェント同士を連携させるための仕組みです。
エージェントが他のエージェントをfunction callingと同じように呼び出すことが可能になります。これにより、各ステップは専門のエージェントが担当する仕組みが構築可能です。専門エージェントでは対応できない場合、他の専門エージェントにタスクを任せることができるのです。
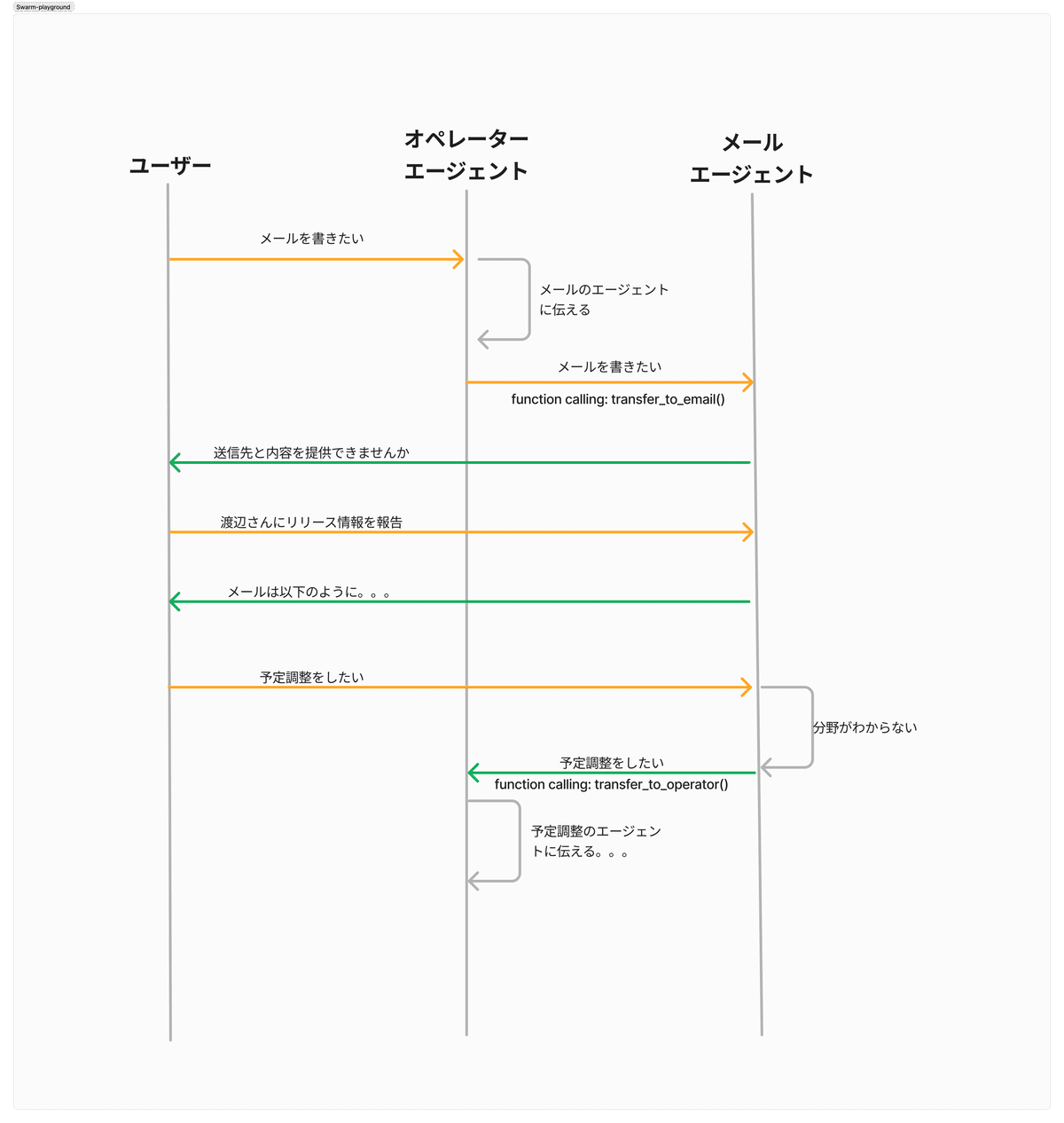
例えば会社にサポートボットを作りたいとします。下記のようなタスクをこなす必要があります。
メールの準備
予定調整
このタスクを実現するために3つのエージェントを作成します。
❶ オペレーターエージェント:ユーザーからの入力から次に取るべき行動を判断し、専門のエージェントに引き継ぐ
❷ メールエージェント:メール作成を担当
❸ スケジュールエージェント:予定調整を担当
コードを見るとわかりやすいと思います。
operator_agent = Agent(
name="Operator Agent",
instructions="Determine which agent is best suited to handle the user's request, and transfer the conversation to that agent.",
)
email_agent = Agent(
name="Email Agent",
instructions="You are the email agent. You are responsible for write email requests.",
)
def transfer_to_email():
return email_agent
operator_agent.functions = [transfer_to_email]
#####
client = Swarm()
response = client.run(
agent=operator_agent,
messages=messages,
)
Swarmを本番環境で使うのは非推奨⚠️
以下の理由からSwarmの本番環境での使用にはリスクがあります。
非同期処理・セキュリティ機能はない
チャット履歴を保存するための仕組みがない
フローベースのタスクには向いているが、、self-improvement・reflectionなどの自己改善やフィードバックケースには向かない。理由:
親エージェントは子エージェントに任せる仕組みである以上、リクエストは滝みたいで、子→親への逆フィードバックが難しい。
ルールベースのような仕組みなので、柔軟性が低く、重いタスクも対応しにくい。
以上の理由から、Swarmは学習目的でマルチエージェントを体感することには適しているものの、本番環境での使用にはおすすめしません。学習目的のみで活用するのが最適です。