
簡単導入!MacでStable Diffusionを使って高速で画像生成をする方法まとめ

はじめに
はじめまして。画像生成AIの使い方を広めているNAYUです。
ここ半年間で、急速にChatGPTや画像生成AIといったジェネレーティブAIが発展し、個人でも扱えるようになりました。とはいえ、特に画像生成AIはプログラムの知識がない人にとっては導入のハードルが高く、「AIを試してみたいけど導入がややこしそう」といった声を聞きます。
この記事では、PCやプログラムに詳しくない方や、高性能なGPUを持っていない方、そしてMacを使っている方であっても、Stable Diffusionを使って画像生成を楽しめるように、環境構築から画像生成までの手順をご紹介します。
本記事では以下のことについて取り上げます。
・環境構築の手順
・学習モデルの変更
・画像生成のパラメーター
・○○に特化した追加学習モデルの追加
・ControlNetを使用したポーズの指定
注意
5月22日現在、後述するGoogle Colaboratoryに課金しないと動作しないようになりました。今後、無料で使える代替手段を見つけたら共有したいと思います。
課金する場合、以下のリンクから登録できます。課金してみましたが、クレジットカードとプランを選択するだけなので、3分で簡単に課金できました。
環境構築
Stable Diffusionの導入から画像生成までの手順を4つのステップに分けてご紹介します。
1. Google アカウントの作成
AIによる画像生成は基本的に高性能なGPUが必要とされますが、高性能なGPUがない場合や、Macユーザーである場合でも、プログラムを動かせるように、Googleの無料クラウドサービス「Google Colaboratory」を使用します。このサービスの利用にはGoogle アカウントが必要なため、アカウントがない場合は以下のリンクから作成してください。YouTubeやGmailを使っている方は既にアカウントを所有されているかと思います。
2. 画像生成プログラムを導入する
本記事では、camenduru氏のstable-diffusion-webui-colabを使わせていただきます。まずは以下のリンクを開いてください。
■ Stable DiffusionをGoogle Colabに導入
下にスクロールしていくと「🦒Colab」という項目があります。ここでは、様々なモデル別のプログラムが一覧で公開されています。例えば、実写の画像生成に適したStable Diffusionのモデルだけでなく、イラストの画像生成に適したAnythingや8528 diffusion、waifu diffusionといったモデルがあります。

ここで、モデルを選ぶ上での注意点について少し触れておきます。AnythingやOrangeMixは、高品質なイラストを生成すると話題になっていますが、画像生成AIのプラットフォームであるNovelAIから流出したモデルデータを元に作成されている疑惑があります。使用にはリスクが伴う可能性があるため、ここでは非推奨とします。
そのため、本記事では「stable_diffusion_v2_1_webui_colab」を使って導入方法をご紹介します。しかし、どのモデルも導入方法はほとんど同じですので、実写やイラストなど、用途に合わせてモデルを選んでください。以下のサイトが参考になるかと思います。
使いたいモデルが決まったら、そのモデルの左にあるオレンジ色の「stable」をクリックしましょう。
ちなみに「lite」「stable」「nightly」と種類がありますが、人物のポーズを指定できるControlNetを使用したい場合、「stable」または「nightly」を選択してください。また、前者は安定したWEBUIと拡張機能をインストールするのに対し、後者は最新のWebUIと拡張機能をインストールするようです。「前まで使えていたのに突然使えなくなった」ということがあっては困るので今回は「stable」を導入します。
「stable」をクリックすると、Google Colabのサイトに移ります。そこで「Copy to Drive」をクリックして、ご自身のGoogle ドライブにプログラムをコピーしておきます。
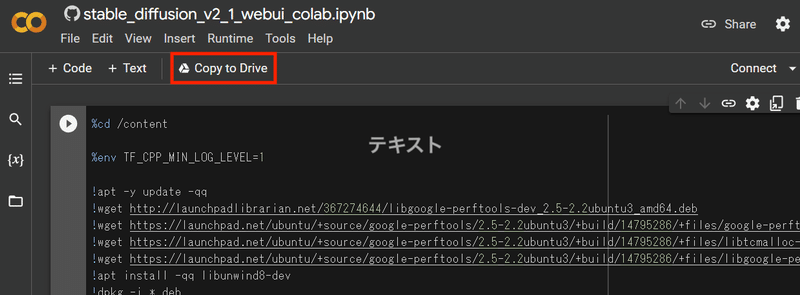
コピーが完了するとファイル名が「Copy of ~~~~」となるので、確認しましょう。正しくコピーができていれば、実行ボタンをクリックします。処理時間はモデルにもよりますが5分~10分かかるので、のんびり待ちましょう。

処理が完了すると「Public WebUI Colab URL:~~~~~~.gradio.live」といったリンクが表示されるのでクリックします。すると、新しいタブでStable DiffusionのUI画面が表示されます。

以上で、Stable Diffusionの導入から起動までが完了しました。次のセクションでは、いよいよ画像を生成していきます。
3. 画像を生成する
画像を生成するに当たって、基本的な設定項目について軽く解説します。
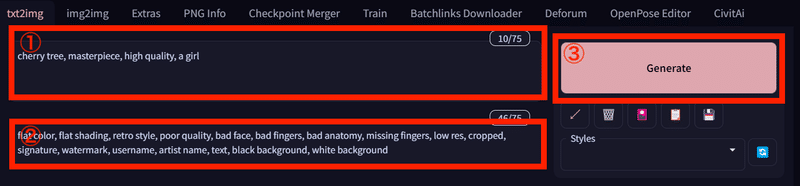
①Prompt
Stable Diffusionなどの画像生成AIは、どんな画像を生成するのかプロンプトで指示をしなければなりません。画像に含めたいことを入力します。
例)1girl, solo, upper body, smail
②Negative prompt
画像に含めたくない要素を入力します。
例)flat color, flat shading, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, watermark, username, text
③Generate
Generateを押すと画像生成処理が開始されます。生成中はInterrupになります。Interruptをクリックすると、処理が中断されます。
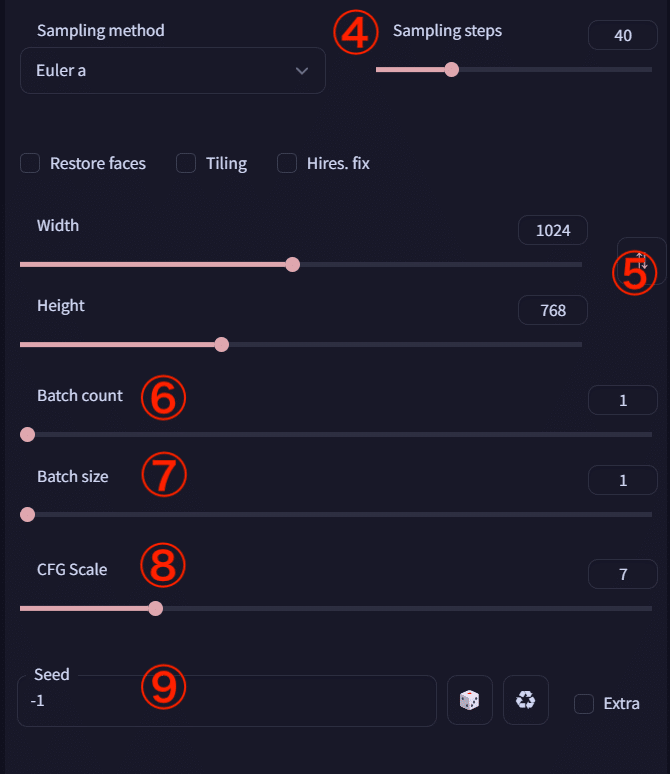
④Sampling steps
画像を改善する処理を何回繰り返すかの設定です。値を大きくすると緻密な画像を生成できるようです。20~80でやっている方が多い印象です。画像の中のオブジェクトを増やしたいときは値を増やすといいかもしれません。値を大きくすると、画像生成の所要時間が増加します。
⑤Width Height
生成する画像の横幅と高さを指定できます。
⑥Batch count
画像生成処理を繰り返す回数です。
⑦Batch size
同時に生成する画像の枚数を指定できます。
例) Batch count=5、Batch size=2にすると、画像を10枚生成します。
⑧CFG Scale
指示したpromptにどの程度従わせるかの強さを調整できます。基本的には7ぐらいでいいと思いますが、画像の抽象度を上げたいときに値を下げ、より具体的にしたいときに値を上げます。5~9ぐらいが良く使われるようです。
⑨Seed
画像生成の計算に使用する乱数です。「-1」にするとランダムなシードで生成されます。同じ構図で複数枚出力したいときに値を固定します。
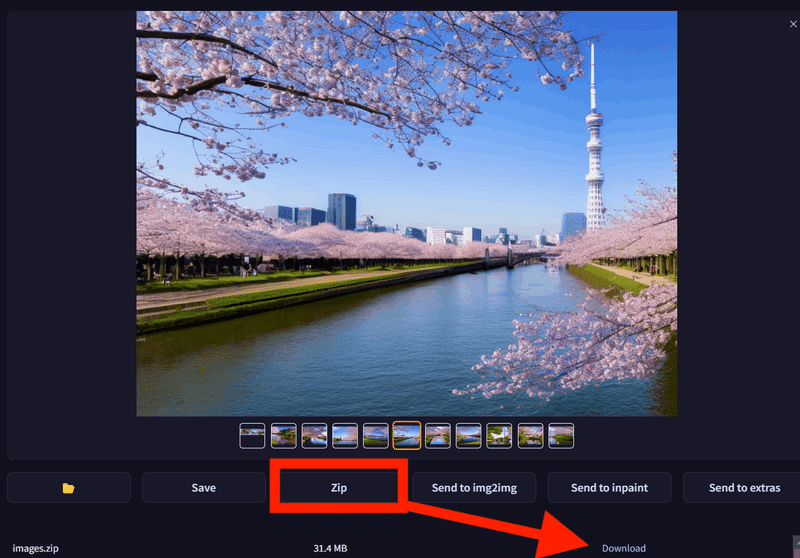
今回は「東京スカイツリーと川と桜」をプロンプトに入力しました。生成結果がこちらです。

適当にプロンプトを入力しただけですが、いい感じの構図で出力してくれました。画像を何枚か生成して良い画像を選びましょう。
画像は数時間後に自動的に消去されるので、Zipをクリックしてダウンロードしておきましょう。
次のセクションでは、より思い通りの画像を生成するために役立つことをご紹介します。
4. 思い通りの画像を生成する
・○○に特化した追加学習モデルの追加
今のままだと、画像生成AIは特定のキャラクターだったり、特定の絵柄を画像に出力することは非常に難しいです。しかし、既存のモデルに新たな被写体を学習させた追加学習モデル(LoRA)を使って、この問題を解決することができます。以下のようなときにLoRAを導入するといいでしょう。
・特定のキャラクターを出力したいとき
・特定の絵柄を再現したいとき
・特定の風景(夜空など)に特化した画像を出力したいとき
手順としては、最初にCivitaiというサイトから表現したいものに近いLoRAを選んでダウンロードします。このとき、選んだLoRAの説明欄に追加学習した特徴を呼び出すのに必要なトリガーワードがないかを確認しましょう。後でプロンプトに入力する必要があります。また、学習モデルのベースモデルとLoRAのベースモデルが一致しているのかも調べましょう。一致していない場合、LoRAを適用できません。Colaboratoryのタブで"RuntimeError: mat1 and mat2 shapes cannot be multiplied"のようなエラーがでます。

次に、環境構築で使用したGoogle Colaboratoryのタブを開いて、フォルダのアイコンをクリックします。そしてダウンロードしたモデルを「/stable-diffusion-webui/models/Lora」にドラッグアンドドロップして配置します。LoRAのファイルが重たかったり、通信環境が悪かったりすると少し時間がかかる場合があります。
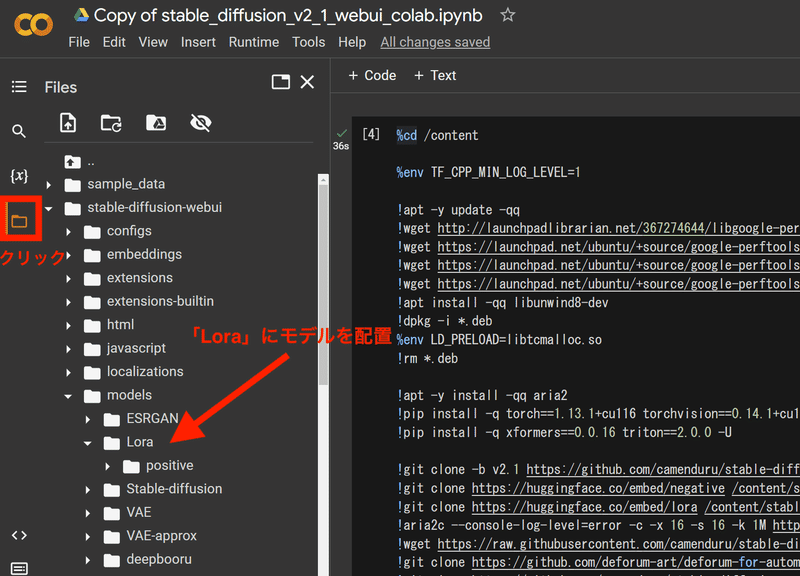
最後に、Stable DiffusionのUI画面に戻って「Generate」の下にある🎴をクリックして「LoRA」の適用画面を出し「Refresh」をクリックします。すると、自分がダウンロードしたモデルが現れるので選択します。選択すると、自動的にプロンプトに<lora:LoRAの名前:1>が入力されます。デフォルトでは1ですが、画像が破綻することが多いので大抵は0.4~0.8に設定します。設定後、🎴をもう一度クリックするとLoRAの適用画面を隠すことができます。

追加学習した特徴を呼び出すのに必要なトリガーワードがある場合は、<lora:LoRAの名前:数値>とタグをプロンプトに加えた状態で「Generate」をクリックするとLoRAを反映できます。
追加学習した特徴を呼び出すのに必要なトリガーワードがない場合は、<lora:LoRAの名前:数値>をプロンプトに加えるだけでいいです。
以上、追加学習モデル(LoRA)の追加方法でした。
・ControlNetを使用したポーズの指定
ControlNetという機能を使うと、画像上に生成した人物に何らかのポーズを取らせることができます。また、人物の位置を指定することもできます。非常に便利ですので、ぜひ使いこなせるように頑張りましょう。
それでは、UI画面上部の「OpenPose Editor」というタブをクリックしてください。ここでは、棒人間を使って位置とポーズを指定することができます。
まずは、widthとheightを指定しましょう。画像生成する際のサイズにしておきます。次に、棒人間をクリックして移動させたり、関節をクリックしてポーズを取らせたりします。それが終わったら「Send to ControlNet」をクリックしましょう。

上部のUIタブから「txt2img」を選択して生成画面に戻ります。そして、widthとheightを棒人間の時に設定したwidthとheightの値と揃えます。
さらに下のほうに「ControlNet」という項目があるので、クリックすると設定画面が現れます。以下の画像のように設定してください。Modelについては「openpose-sd21-safe」がない場合、「control_openpose」があればそれを使うようです。

あとはパラメーターとプロンプトを指定して「Generate」をクリックすると、狙った通りに生成された人物がポーズを取ってくれます。
以下が生成された画像です。設定した棒人間の通りの位置でポーズを取っています。

以上、ControlNetを使用したポーズの指定方法でした。
おわりに
本記事では、Macユーザーや高性能なGPUを持っていない方でも、画像生成AIを楽しめる方法をご紹介しました。この記事が、画像生成AIの導入のハードルを少しでも下げるものになれば幸いです。
もし本記事が参考になりましたら、ぜひご支援いただけますと今後の記事制作の励みとなります。
記事を読んでくださり、ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?