
破線を描く、効率的に。

こんにちは、初代クワマンです。
ナビタイムジャパンの研究開発部門にて、地図フレームワークエンジニアを担当しています。
みなさん、地図上の破線がどのように描画されているか、ご存知でしょうか?
この描画が案外曲者で、簡単には実現できません。
今回は、何気なく目にする破線の描画をどのように行なっているか、どのように効率化しているか、ご紹介いたします。
破線の例
現在、ナビタイムジャパンのアプリケーション上で表示されている破線は、
大きく分けて2つあります。
JR線

渋滞線

この2つの表示は、実は別々の機能で実現しており、描画に至るまでの処理が違います。今回は渋滞線にて用いられている破線についてお話しします。
従来の描画
当社の破線表示は、ON/OFFの周期を操作できるようPixel単位での周期を入力し、破線のみならず点線、一点鎖線等も実現できるように実装されています。

これを実現するためには、Pixel単位のON/OFF判定を画面座標系で行う必要があり、下記のような処理を行なっています。
座標系変換
データで示される緯度経度と、画面上に表示するための座標は違うものです。そのため、座標を計算して変換する必要があります。
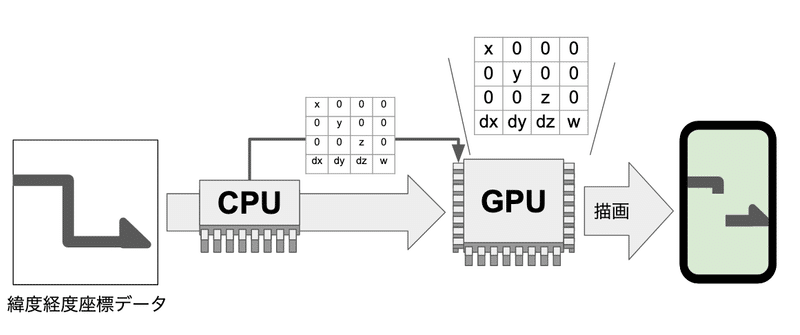
この緯度経度座標系から画面座標系への行列変換を、CPUが行なっています

破線の1コマごとにデータ、ポリゴンを作成
まず、線の表示をポリラインで行うと太さを指定できないなどのGPU実装差分があるため、線の表示はポリゴンで行っています。

また、その間隔はピクセル単位で指定されています。
そのため、座標計算に合わせてピクセル単位での進行度を確認し、破線のコマとして作成するか否かを判定し、形作るポリゴンを作成しています。

課題
上記で述べた描画方式は、画面内外におよそ10本ほどの線であれば有効なのですが、時に大量に100本以上の線があった場合に画面更新速度が非常に遅くなってしまいます。原因は、上記で述べた2要素です。
表示までの変換等処理にCPUを使用している
破線の1コマごとにデータを作っている

これらは大量表示に向かない処理となっているため、表示の効率化、高速化を図りました。
解決
GPUで座標系変換
androidは OpenGL ES 2.0導入より、iOSは Metal導入より、描画までの処理をShader言語を介してGPUに計算させることができるようになりました。
これを用いて、従来の機構ではできなかった独自の行列演算をGPUに行わせることができます。
結果、CPUはデータをGPUに格納させるだけという形に変更し、ボトルネックの解消ができました。
1コマごとにデータを作らず、単純な線の上で描く
先ほど述べた、描画までの処理をShader言語を介してGPUに計算させることができることに繋がります。
描画までの流れをプログラムできるようになりましたので、ピクセル単位での破線のON/OFFもまた、プログラムできるようになりました。
実際に実装した処理の概要をご説明します。
頂点情報内に、線の上での移動量を示す値を格納します。

この値を、VertexShader内で、画面座標系のピクセル値相当の値に変換します。 (分かりやすくするため、1移動単位:1ピクセルとしています)

そして、FragmentShaderでこの値を受け取ることで、各Pixel上でどれだけ移動したか、補間された値が得られます。

これで各Pixel上での線の進行度が分かります。この進行度が破線のON/OFFの値に位置するかを判定することで、ONであれば表示し、OFFであれば描画処理を破棄する、という形で、線の情報のみで破線の描画が実現できる、ということです。

試作、開発はiOSで行いましたので、
下記にサンプルとなる Metalのshaderコードを展開いたします。
// -- vbo --
struct Vertex{
vector_float4 position;
vector_float2 movement;
};
// -- vertex --
struct DashVaryings {
float4 position [[position]];
float lineMovement;
};
// -- vertex shader --
vertex DashVaryings vertex_dash(const device Vertex *vbo [[buffer(0)]],
uint vid [[vertex_id]])
{
DashVaryings outVert;
outVert.position = vbo[vid].position;
//移動量の1次元化
outVert.lineMovement = abs( length(float2(vbo[vid].movement[0], vbo[vid].movement[1])));
return outVert;
}
// -- fragment shader --
fragment float4 fragment_dash(DashVaryings varyings [[stage_in]],
constant float4 &color [[buffer(1)]],
constant float4 &intervals [[buffer(2)]])
{
//判定用残量の算出
float sumIntervals = intervals[0] + intervals[1] + intervals[2] + intervals[3];
float remain = varyings.lineMovement - ( sumIntervals * int(varyings.lineMovement / sumIntervals) );
//偶数interval内にあればON 奇数interval内にあればOFF
remain -= intervals[0];
if( remain <= 0.0 ){
return color;
}
remain -= intervals[1];
if( remain <= 0.0 ){
discard_fragment();
}
remain -= intervals[2];
if( remain <= 0.0 ){
return color;
}
discard_fragment();
}
成果
表示用リソース量の減少
破線のコマごとに作成していた頂点データが不要となったため、
頂点数、ポリゴン数、ともに約1/2 まで減少しました。
※破線のコマ幅が細かいほど効果があります。

描画速度の変化
画面内に10本ほどの渋滞線を描画した結果、
・旧描画:4.2[ms]
・新描画:1.5[ms]
およそ60%(2.7[ms])ほど描画時間が減少 しました。
おわりに
以上、破線の描画処理についてご紹介させていただきました。
現在、地図フレームワークは、今までCPU処理で実現していたものをGPUとShaderで処理させていくことで、より効率的で高速な描画の実現が期待されています。
今後も、ひっそりと、しかし、確実に高速な描画を実装してまいりますので、どうぞよろしくお願いいたします。