
Googleスプレッドシートを駆使してバックエンドDBを構築する

こんにちは、ヤギです。
ナビタイムジャパンで公共交通データの研究開発部門に所属しています。
皆さん、Googleスプレッドシートって使ってますか?
表を作ったり、関数を使って計算を簡単にできたりと便利ですよね。私が所属する部署では、作成したデータの検証項目書として利用しています。今回はタイトルの通り、検証項目書の情報をシステム利用するためにGoogleスプレッドシートを駆使してバックエンドDBを構築しました。
GoogleスプレッドシートでバックエンドDBを構築するにあたって使用した新機能とIMPORTRANGE関数の仕様について学びがあったので得られたテクニックを共有します。
やりたいこと
テンプレート化された複数のデータソースの情報を集約(json化)して社内webツールサービスで利用できる状態にしたい。
データフローは、
データソースのスプレッドシートファイル内の各シート情報をひとつのシートに集約する
管理スプレッドシートファイルからGoogleAppScripts(以降GAS)でデータソースの集約されたシート情報をパース、Json形式にデータ整形、S3にアップロードする
といった流れになります。
本記事では1のデータソースのスプレッドシートファイルをスコープに執筆させていただきます。(思った以上にボリューミーになってしまいました)

シート構成
たとえば、下記の画像のようなシート構成をしている場合、
サマリーシートに検証A/B/Cのシート情報を集約できると、その後他シートから本ファイルを参照される際に情報がまとまっていてパースしやすくなります。
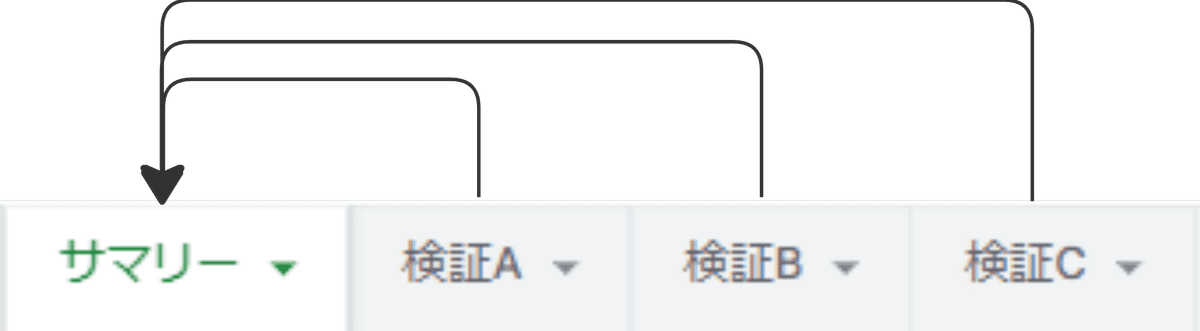
サマリーシートには、各シートから集約したい情報を参照する表を用意しました。

検証Aシートは下記のようなシート構成で、サンプルの記載が書いてある状態です。

検証B/Cシートも同様のフォーマットで、結果だけ変えています。
MAP/LAMBDA関数で各シートの情報を集約する
まずは、各検証シートから項目数、oの合計数、xの合計数をサマリーシートに表示するセル式を作りたいと思います。
2022年に新たに追加されたMAP/LAMBDA関数を使うことで、セル範囲をイテレータとして扱い、同じ計算式で反復した結果をセルに展開することが可能になりました。
MAP/LAMBDA関数はプログラムコードを書く人だと馴染みがあるかもしれませんが、初めて触れる人には少し癖がある関数かと思います。
「指定した範囲のセルを順番に処理させるための関数」というざっくりの理解でOKで、今回のような「他シートの参照を一連の処理で捌く」シーンで活用できると思います。
また、セル毎にセル式を書かずにひとつのセル式で反復処理させることができるので、たとえば表の最下行に行挿入時に新たにセル式を入れる必要もなくなり、スプレッドシートファイル内のセル式の数を減らすことにも役立ちます。
MAP/LAMBDA関数を使うことで、行・列の二次元配列情報を1つのセル式で算出することもできます。

=MAP($A$4:A14,
LAMBDA(ticket_id,
if(ISBLANK(ticket_id),"",
MAP($D$1:$L$1,$D$2:$L$2,$D$3:$L$3,
LAMBDA(sheet_name,target_col,count_val,
COUNTIFS(INDIRECT(sheet_name&"!C1",false),A4,INDIRECT(sheet_name&"!C"&target_col,false),
IF(count_val="項目数",
ticket_id,
INDEX(SPLIT(count_val,":"),2))))))))
期待通り、各検証シートから該当のチケットID行の項目数、oの数、xの数をcountした結果がセル展開されました!
ポイント
カウント対象のシート名/列番号/値を各列のヘッダに定義することで、MAP/LAMBDA関数で単独で処理できるようにした
項目数のカウントはCOUNTIF関数のみでできるが、MAP/LAMBDA関数で共通処理に流し込みたいため、冗長にはなるがCOUNTIFS関数でチケットID列でカウントする処理で共通化した
名前付き関数で定義する
前述で書いた長くて複雑なセル式は他の人が読み解くのは困難ですよね。
スプレッドシートファイルに新たに追加された名前付き関数を利用することで、セル式の簡素化することができます。
先の例で上がったセル式の内、カウント処理部分を「COUNT_ITEM」関数という名前付き関数で定義したものが下記です。


=MAP($A$4:A14,
LAMBDA(ticket_id,
if(ISBLANK(ticket_id),"",
MAP($D$1:$L$1,$D$2:$L$2,$D$3:$L$3,
LAMBDA(sheet_name,target_col,count_val,
COUNT_ITEM(ticket_id,sheet_name,target_col,count_val))))))名前付き関数を使うことでセル式全体が簡潔になりました。
また、関数や引数の説明ができるので、他の人が見たときにも何を処理してくれるかが説明でき、わかりやすくていいですね!
複数のスプレッドシートファイルで共通利用する入力規則を別ファイルからインポートする
表の特定の列に入力する値の種類が決まっている場合、スプレッドシートファイルの入力規則を使うことで想定外の値が入力されることを防ぐことができます。
たとえば、検証結果の「〇」は、漢数字の「〇」と記号の「○」で揺れることがあるため、それを防ぐのに効果的です。

検証結果の○や×のように「種類が今後増えない特性」であれば、スプレッドシートファイル内に定義する、でもいいですが、
「種類が今後増える特性がある入力規則」の場合には、外部のシートに入力規則を定義したスプレッドシートファイルを用意してIMPORTRANGE関数で取り込むことで、種類が増えたときのすべてのデータソースシートの入力規則を追加する運用コストを下げることができます。

今回はメンバーの入れ替わりによって追加したり削除されたりしうる特性がある「検証者名」を例に説明します。

上記の画像では、外部シートとして用意した入力規則シートの内容を、データソースの検証項目書シートにIMPORTRANGE関数を使って取り込みました。(ワークスペースの設定によってアクセス許可が求められる場合があります)
新しい検証者が増えた際には入力規則シートにのみ追加するだけで、IMPORTRANGE関数を設定しているシートにも自動的に追加された検証者が反映されるようになります。

IMPORTRANGE関数の制約について
これでデータソースのファイルがいくつあっても入力規則シートからIMPORTRANGE関数で取り込めば、同一の入力規則の情報を共有できる状態になった!と思いました、この時は。
その後、GoogleAppScriptsで
スプレッドシートファイルの複製
するコードで、順調にデータソースのファイル生成&IMPORTRANGEのアクセス許可を自動実行してました。
…が、IMPORTRANGEのアクセス許可実行時に下記エラーがでて問題が発生します。

問題が発生しました
スプレッドシートのリンク中にエラーが発生しました。参照元のスプレッドシートが共有とインポートの上限容量に達しています。
ドキュメントを見るに、IMPORTRANGE関数には1つのスプレッドシートファイルに対し600ファイルを上限にインポートが可能という仕様がありました。それを超えて「アクセス許可」をクリックすると本エラーが表示されます。
Once access is granted, any editor on the destination spreadsheet can use IMPORTRANGE to pull from any part of the source spreadsheet. The access remains in effect until the user who granted access is removed from the source. Note that the access granted to the destination sheet counts against the 600-user share limit for the source sheet.
IMPORTRANGEの上限数を分散させるためのスプレッドシートを間に挟むことで、600ファイルの上限を回避することができました。
この構成なら中間の分散用ファイルを追加で用意するだけで、ひとつのファイルを600を超えるスプレッドシートファイル間で共有参照することができます。
安全のため、ひとつの分散用シートからインポートするデータソースは300ファイルまでとしました。

600ファイルを超えてインポートする要件はなかなか一般的にないとは思いますが、今回の要件ではどうにか解決する必要があり、この構成にたどり着きました。
おわりに
本記事では、GoogleスプレッドシートでDB構築するためのデータソース部分にフォーカスを当て、システム利用するための正規化手法をメインに執筆しました。
これらのデータソースの情報をGASを用いて集約してJSON化→S3アップロードすることでシステムで利用可能な状態を作ることができましたが、今回はいったんここまでとさせていただきます。
IMPORTRANGE関数のハマった仕様について自分と同じ状況で困っている方の参考になれば幸いです。
今後も続々とGoogleスプレッドシートの新機能がリリースされる予定なので、よりGoogleスプレッドシートを業務で快適に利用できるのが楽しみですね!
個人的にLET関数が気になってます。
https://workspaceupdates-ja.googleblog.com/2023/02/google_10.html
それではまた!