
ラティスから始める音声認識

ラティスを見てみよう
ここでいうラティス(lattice)とは、簡単にいうと音声認識の出力候補のグラフです(トップ画がラティスを視覚化した図)。まずは、自前の音声認識エンジンを使った事例をみてみます。
こちらの音声を認識させると、
結果:
lattice 1 0.160 0.140 ラティス+名詞
lattice 1 0.310 0.070 から+助詞
lattice 1 0.380 0.180 始める+動詞
lattice 1 0.560 0.350 音声認識+名詞
===========================================
ちなみに、
lattice 1 0.160(開始時間/3) 0.140(発話継続時間/3) ラティス+名詞
なので、0.48sから0.9sの間に"ラティス"と発話しているということ。認識結果をみると「ラティス から 始める 音声認識」と正しく認識されていることがわかります。この結果は、ラティスの候補の中から最も可能性が高い候補が選ばれています。
This is Lattice. この通り、ノード(点)とエッジ(辺)からできています。各ノードとエッジは、可能性の高さを決める"コスト"を持っています。コストが低いほど可能性が高くなります。(この図にはコストは記載されていない)

ラティスを見てみると、ルートの候補から最も可能性が高い(最もコストが低い)「0 → 1 → 2 → 3 → 4 → 23」 のルートが選択されたようです。
図の中の ”28681:ラティス+名詞” の先頭の数字は単語のIDを表しています。
<words.txt>
...
かよっ+動詞 2951
から+副詞 2952
から+助詞 2953
から+動詞 2954
から+名詞 2955
...
ラップトップ+名詞 28679
ラップユ+名詞 28680
ラティス+名詞 28681
ラテックス+名詞 28682
ラディックス+名詞 28683
...このように、IDと単語が紐づいています。これが正しく紐づいていないと、出力されたIDと単語がバラバラになってしまって正しい結果が表示されません。
<words.txt>
...
から+副詞 2952
と+助詞 2953
から+動詞 2954
...
ラップユ+名詞 28680
ラティオス+名詞 28681
ラテックス+名詞 28682
...例えば、このように変更すると「ラティオスと始める音声認識」になってしまいます。ちゃんとモデルに合った辞書を使いましょう。

ラティスの作り方
ラティスはデコードという処理によって生成されます。
デコード(decode)とは、音声認識のモデルから生成されたラティス上から確率の高さなどでパス選択をすることで、音声から単語列を出力することです。
音声認識のモデルは、以下の3つから成り立っています。
1. 音響モデル: ある音素がどのような音となって現れるか をモデル化。音声から抽出された特徴量がどの音素に近いのか確率を出力する。
音声 → 音素 (r, a, t, h, i, s, u)
2. 発音辞書: 音素列と単語の対応関係を記した辞書。音素の組み合わせを単語に変換する。
音素列(r a t i s u) → 単語(ラティス)
3. 言語モデル: 大量の文章から単語の前後関係の並びの確率をモデル化。単語の頻出する組み合わせの確率を高く、単語のほとんど出ない組み合わせは確率を低くする。
(*この記事ではモデルについては詳しく触れません)
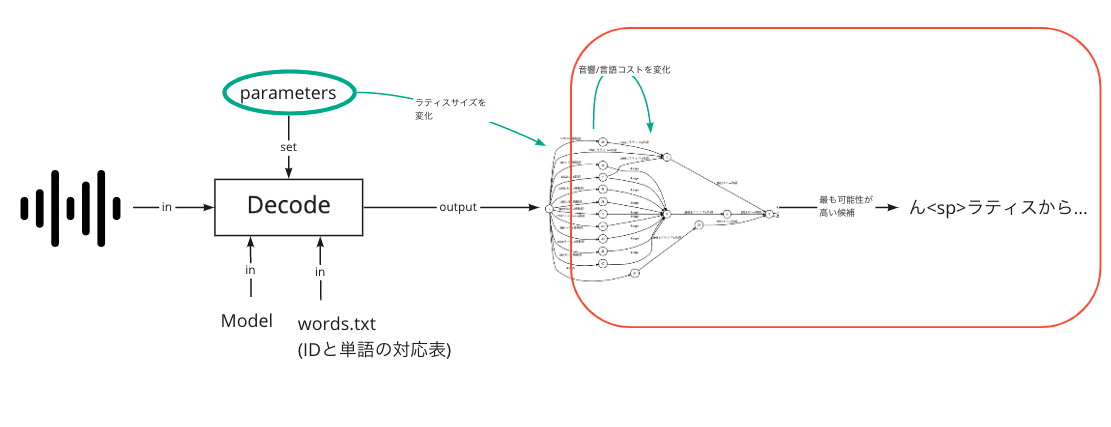
デコードから認識結果が出力されるイメージ図がこちらです。

Model: 音響モデル, 発音辞書, 言語モデルを統合した音声認識のモデル
words.txt(単語辞書): 先ほど説明したIDと単語を紐づけるもの。モデルに合わせたものを使用
parameters: ラティス内の候補数や音響コスト・言語コストを調整できる。
このパラメータを変更することで、ラティスの候補を増減させることができます。また、ラティスの音響/言語コストを変更させることで、ラティスから選ばれる最も可能性が高い候補も変化し、出力結果も変化します。(コストを変化させなければ、ラティスサイズを増減させても同じ結果になる。)
これは、同じ音声とモデルで、ラティスの候補が多くなるようにパラメータを変化させ音響コストを増加した例です。

音響コストを増加させた結果 → 言語モデルに忠実になる
lattice 1 0.000 0.080 ん+助詞
lattice 1 0.080 0.060 <sp>
lattice 1 0.160 0.140 ラティス+名詞
lattice 1 0.310 0.070 から+助詞
lattice 1 0.380 0.180 始める+動詞
lattice 1 0.560 0.020 ぐ+名詞
lattice 1 0.580 0.330 音声認識+名詞
lattice 1 0.920 0.100 <sp>
lattice 1 1.020 0.030 ほ+動詞ん+助詞、ぐ+名詞 などが多く学習されているから、音響コストを増加させたときにこのような結果になるんでしょうね...
コラム:なぜラティスを作る?
なぜわざわざ、そのままモデルを使って最も可能性が高い単語列を求めず、ラティスを作るのか?それは、語彙数が増え、発話が続くと、候補(単語列)が莫大になるため、全ての候補を計算するのができなくなるためです。ラティスを使うことで、音声の先頭から可能性が高い候補に限定することができ、語彙数が多く/発話が続いてもデコードすることができます。
ラティスを変えてみよう
具体的にkaldiでパラメータを変更すると、ラティス候補がどのように変化するのかを、「箸を持ちながら橋の端を渡る」と発音した音声で見てみましょう。
まずは、このようなコマンドでラティスを生成してみます。
#!/bin/bash
$KALDI_ROOT/src/online2bin/online2-wav-nnet3-latgen-faster \
--frame-subsampling-factor=3 \
--beam=5.0 \
--lattice-beam=2.0 \
--acoustic-scale=1.0 \
--config=$online_config \
--word-symbol-table=$ASSETS_DIR/words.txt \
$ASSETS_DIR/final.mdl $ASSETS_DIR/HCLG.fst \
$spk2utt_rspecifier "$wav_rspecifier" "$lat_wspecifier"ラティスの候補に関わる重要なパラメータが、beam, lattice-beamなのでこの2つのパラメータに注目します。どちらも、ラティスを作る際の探索に関わるパラメータです。beamはラティスの横の探索、lattice-beamはラティスの縦の探索に関係しています。beamが大きいほど、より長い文字列で候補を探索します。lattice-beamが大きいほど、一つの単語から派生するより多くの候補を探索します。
探索とは、音声の先頭から、スコアの高い候補に絞って、接続可能な展開をおこなう処理のことです。探索を広げすぎると、デコードの時間が長くなってしまい、探索を狭めすぎると、本来正解になる候補が出現しなくなってしまいます。
最初は、beam, lattice-beamの値を低く設定して探索を狭めています。最初は、beam, lattice-beamの値を低く設定して探索を狭めています。
結果がこちらです。

認識結果。これは、ラティスの候補を変えてもコストを変化させないと変わらない。
hashi 1 0.130 0.130 発信+名詞
hashi 1 0.260 0.030 を+助詞
hashi 1 0.290 0.100 持ち+動詞
hashi 1 0.390 0.180 ながら+助詞
hashi 1 0.570 0.060 <sp>
hashi 1 0.640 0.160 橋野+名詞
hashi 1 0.800 0.150 ハシオ+名詞
hashi 1 0.960 0.150 当たる+動詞 認識結果は箸にも棒にも掛かってないですが、ここで見るべきはラティスです。なので、認識結果は無視しましょう。
探索を狭めすぎたため、全然思った通りの候補がラティスに出ていません。
まずは、lattice-beam:2 -> 3 にした結果をみてみます。

一点から派生する候補は増えましたが、文脈にあってない候補ばかり増えています...
次は、beam:5 -> 10 にした結果をみてみます

これは、最初のラティスと全く同じになってしまっています。そもそも、一点から派生する候補が少ないので、長い文字列で候補を探索しても同じになってしまったのでしょう。
最後に、lattice-beam:2 -> 3, beam:5 -> 10 と2つのパラメータを変化させた結果をみてみます
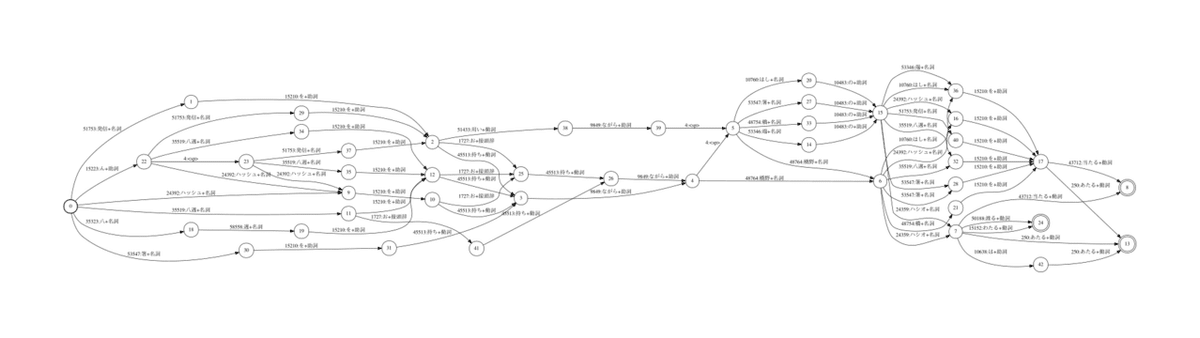
ついに、「箸を持ちながら橋の端を渡る」に近い「箸 を 持ち ながら 橋 の 端 を あたる」のパスが出現しました。一点から派生する候補を増加させ、長い文字列で候補を探索したからなのでしょう。

出力結果を変えてみよう
いくらラティスの候補を増やしても、最適なパスを選べなければ意味がありません。生成したラティスの音響コストを変化させ、出力結果がどのように変化するのかみてみます。
デフォルト: 何もせずラティスのベストパスを出力
lattice-1best で、可能性が最も高いベストパスを出力する
生成したラティスのファイルを圧縮したものが lat.1.gz
デフォルト: --acoustic-scale=1
$KALDI_ROOT/src/latbin/lattice-1best \
"ark:zcat $DATA_ROOT/raw_result/lat.1.gz |" ark:- |
$KALDI_ROOT/src/latbin/lattice-align-words $ASSETS_DIR/word_boundary.int \
$ASSETS_DIR/final.mdl \
ark:- ark:- |
$KALDI_ROOT/src/latbin/nbest-to-ctm ark:- - |
$KALDI_ROOT/egs/wsj/s5/utils/int2sym.pl -f 5 $ASSETS_DIR/words.txt > $DATA_ROOT/raw_result/rawresult.txtそもままの結果
hashi 1 0.130 0.130 発信+名詞
hashi 1 0.260 0.030 を+助詞
hashi 1 0.290 0.100 持ち+動詞
hashi 1 0.390 0.180 ながら+助詞
hashi 1 0.570 0.060 <sp>
hashi 1 0.640 0.160 橋野+名詞
hashi 1 0.800 0.150 ハシオ+名詞
hashi 1 0.960 0.150 当たる+動詞 音響コスト増加 → 言語モデル依存が強まる
lattice-scale で音響コストを変化させる。
--acoustic-scale=10 (デフォルトは1)
$KALDI_ROOT/src/latbin/lattice-scale --acoustic-scale=10 "ark:gunzip -c $DATA_ROOT/raw_result/lat.1.gz |" ark:- | \
$KALDI_ROOT/src/latbin/lattice-1best \
ark:- ark:- |
$KALDI_ROOT/src/latbin/lattice-align-words $ASSETS_DIR/word_boundary.int \
$ASSETS_DIR/final.mdl \
ark:- ark:- |
$KALDI_ROOT/src/latbin/nbest-to-ctm ark:- - |
$KALDI_ROOT/egs/wsj/s5/utils/int2sym.pl -f 5 $ASSETS_DIR/words.txt > $DATA_ROOT/raw_result/rawresult.txt音響コストを10に増加させた結果。
より多く学習させたであろう単語が選ばれるように。
hashi 1 0.000 0.100 ん+助詞
hashi 1 0.100 0.020 <sp>
hashi 1 0.130 0.130 八週+名詞
hashi 1 0.260 0.030 を+助詞
hashi 1 0.290 0.010 お+接頭辞
hashi 1 0.300 0.090 持ち+動詞
hashi 1 0.390 0.180 ながら+助詞
hashi 1 0.570 0.060 <sp>
hashi 1 0.640 0.160 橋野+名詞
hashi 1 0.800 0.140 ハシオ+名詞
hashi 1 0.950 0.030 は+助詞
hashi 1 0.980 0.130 あたる+動詞 音響コスト減少 → 音響モデル依存が強くなる。
--acoustic-scale=0.1
$KALDI_ROOT/src/latbin/lattice-scale --acoustic-scale=0.1 "ark:gunzip -c $DATA_ROOT/raw_result/lat.1.gz |" ark:- | \
$KALDI_ROOT/src/latbin/lattice-1best \
ark:- ark:- |
$KALDI_ROOT/src/latbin/lattice-align-words $ASSETS_DIR/word_boundary.int \
$ASSETS_DIR/final.mdl \
ark:- ark:- |
$KALDI_ROOT/src/latbin/nbest-to-ctm ark:- - |
$KALDI_ROOT/egs/wsj/s5/utils/int2sym.pl -f 5 $ASSETS_DIR/words.txt > $DATA_ROOT/raw_result/rawresult.txt音響コストを0.1に減少させた結果
デフォルトと比べて、<sp>がなくなっている。が、なぜだろう...
hashi 1 0.130 0.130 発信+名詞
hashi 1 0.260 0.030 を+助詞
hashi 1 0.290 0.100 持ち+動詞
hashi 1 0.390 0.180 ながら+助詞
hashi 1 0.640 0.160 橋野+名詞
hashi 1 0.800 0.150 ハシオ+名詞
hashi 1 0.960 0.150 当たる+動詞 結局、コストを変化させても、思った通りのパスは選ばれませんでした...
選ばれるためには、より文脈に即した言語コストを設定するようにする必要があります。音響コスト増加させ、言語モデル依存を強めた時はなかなかひどい結果でしたから...
なので、より文脈にあったようなパスを選ぶようにするために、RNNを次の語の予測のために使うRNN言語モデルでラティスをリスコアリングさせるのですが、それはまた別のお話。
参考
この記事が気に入ったらサポートをしてみませんか?