
PaperspaceでAUTOMATIC1111/stable-diffusion-webui v1.5.1 を動かす
【おことわり:試行錯誤中のため、うまく動いていない箇所があります。ご容赦ください】
v1.5.1 が出たので、Paperspaceで動かしてみます。
インストール方法としてはこれまでと同じで、従来の環境も残しておきたかったので、Paperspace上で新たなプロジェクトを作成しました。ディスク使用が増えて、追加料金が発生するのは承知の上です。
手順は前回と同様、@javacommonsさんの記事(【Paperspace】Stable Diffusion Web UI を月額定額で使う )に沿って進めます。前回の内容は以下にまとめています。
新しいプロジェクト、ノートブックを作成し、設定用のファイル(webui2.ipynb)をアップロードし、順番に実施します。

(2)モデルのダウンロードはSDXL用のモデルを設定します。
(2)変更前
#(2) モデルのダウンロード(ここにダウンロードしたいモデルを追加)
%cd /notebooks/stable-diffusion-webui/models/Stable-diffusion
!wget -nc https://civitai.com/api/download/models/16859 -O BlueberryMix-1.0.safetensors
!wget -nc https://civitai.com/api/download/models/11745 -O Chilloutmix-Ni-pruned-fp32-fix.safetensors
!wget -nc https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/5876389637f3f82d2b33a609f85f9b36aa4748fe/chilled_remix_v1vae.safetensors -O chilled_remix_v1vae.safetensors
!wget -nc https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/main/chilled_remix_v2.safetensors -O chilled_remix_v2.safetensors
%cd /notebooks/stable-diffusion-webui/embeddings
!wget -nc https://civitai.com/api/download/models/60938 -O negative_hand-neg.pt
!wget -nc https://huggingface.co/datasets/Nerfgun3/bad_prompt/resolve/main/bad_prompt_version2.pt -O bad_prompt.pt
(2)変更後
#(2) モデルのダウンロード(ここにダウンロードしたいモデルを追加)
%cd /notebooks/stable-diffusion-webui/models/Stable-diffusion
!wget -nc https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0_0.9vae.safetensors -O sd_xl_base_1.0_0.9vae.safetensors
!wget -nc https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0_0.9vae.safetensors -O sd_xl_refiner_1.0_0.9vae.safetensors
#!wget -nc https://civitai.com/api/download/models/16859 -O BlueberryMix-1.0.safetensors
#!wget -nc https://civitai.com/api/download/models/11745 -O Chilloutmix-Ni-pruned-fp32-fix.safetensors
#!wget -nc https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/5876389637f3f82d2b33a609f85f9b36aa4748fe/chilled_remix_v1vae.safetensors -O chilled_remix_v1vae.safetensors
#!wget -nc https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/main/chilled_remix_v2.safetensors -O chilled_remix_v2.safetensors
%cd /notebooks/stable-diffusion-webui/embeddings
#!wget -nc https://civitai.com/api/download/models/60938 -O negative_hand-neg.pt
#!wget -nc https://huggingface.co/datasets/Nerfgun3/bad_prompt/resolve/main/bad_prompt_version2.pt -O bad_prompt.pt
実行後、ファイルがダウンロードされました。1つ6GBが2つで12GB、結構大きいです。
:/notebooks/stable-diffusion-webui/models/Stable-diffusion# ls -l
total 12709044
-rw-r--r-- 1 root root 0 Aug 4 14:11 'Put Stable Diffusion checkpoints here.txt'
-rw-r--r-- 1 root root 6938078334 Jul 28 17:46 sd_xl_base_1.0_0.9vae.safetensors
-rw-r--r-- 1 root root 6075981930 Jul 28 18:31 sd_xl_refiner_1.0_0.9vae.safetensors(3)Web UI起動
元のソースのまま、まず実行してみます。
#(3) WebUI起動
!apt update
!apt -y install python3.10
!apt -y install libpython3.10-dev
!apt -y install build-essential
!curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
!python3.10 -m pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1+cu118 torchtext==0.15.1 torchdata==0.6.0 --extra-index-url https://download.pytorch.org/whl/cu118 -U
!python3.10 -m pip install xformers==0.0.18 triton==2.0.0 -U
!python3.10 -m pip install matplotlib -U
!python3.10 -m pip install ipython -U
from IPython import get_ipython
get_ipython().run_line_magic('matplotlib', 'inline')
%cd /notebooks/stable-diffusion-webui
!python3.10 launch.py --xformers --enable-insecure-extension-access --share --gradio-queue
数分くらい待ったでしょうか。起動まで進みました。メッセージの終わりの方です。
Launching Web UI with arguments: --xformers --enable-insecure-extension-access --share --gradio-queue
=================================================================================
You are running xformers 0.0.18.
The program is tested to work with xformers 0.0.20.
To reinstall the desired version, run with commandline flag --reinstall-xformers.
Use --skip-version-check commandline argument to disable this check.
=================================================================================
Loading weights [e6bb9ea85b] from /notebooks/stable-diffusion-webui/models/Stable-diffusion/sd_xl_base_1.0_0.9vae.safetensors
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://08277698834f9ed426.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
Startup time: 116.3s (launcher: 88.7s, import torch: 3.9s, import gradio: 1.3s, setup paths: 2.0s, other imports: 2.9s, setup codeformer: 0.3s, load scripts: 1.2s, initialize extra networks: 0.2s, create ui: 3.0s, gradio launch: 12.7s).
Creating model from config: /notebooks/stable-diffusion-webui/repositories/generative-models/configs/inference/sd_xl_base.yaml
Downloading (…)olve/main/vocab.json: 100%|███| 961k/961k [00:00<00:00, 19.7MB/s]
Downloading (…)olve/main/merges.txt: 100%|███| 525k/525k [00:00<00:00, 32.3MB/s]
Downloading (…)cial_tokens_map.json: 100%|█████| 389/389 [00:00<00:00, 2.54MB/s]
Downloading (…)okenizer_config.json: 100%|█████| 905/905 [00:00<00:00, 9.59MB/s]
Downloading (…)lve/main/config.json: 100%|█| 4.52k/4.52k [00:00<00:00, 19.5MB/s]
Applying attention optimization: xformers... done.
Model loaded in 45.2s (load weights from disk: 19.8s, create model: 1.7s, apply weights to model: 13.5s, apply half(): 6.6s, move model to device: 2.5s, calculate empty prompt: 1.0s).生成してみましたが、どうも結果がおかしいです。
デモ画面では refinerの指定がありましたが、ここでは見当たりません。

調べていたら、refinerの指定についてYoutubeで紹介されていました。
英語で詳しくはよくわかっていませんが、Extensionから設定できそうです。

Extensions タブ⇒Availableタブ⇒Load fromボタンク⇒Search [refiner] で検索すると、Extension: Refiner が表示されるので、

install ボタンをクリック

Apply and quit ボタンをクリック

自動で再スタートはされなかったので、再度 WebUIを起動しました。
Refinerのプルダウンができていました。

実行してみます。Refiner部分は、Modelを設定し、あとはデフォルトのままです。

実行結果画面です。


同じ設定で、Refiner がOffの結果も見てみます。

目で見たところでは違いが分りませんでした。
img2imgで試してみると、エラーが出ました。
Launching Web UI with arguments: --xformers --enable-insecure-extension-access --share --gradio-queue
=================================================================================
You are running xformers 0.0.18.
The program is tested to work with xformers 0.0.20.
To reinstall the desired version, run with commandline flag --reinstall-xformers.
Use --skip-version-check commandline argument to disable this check.
=================================================================================
Loading weights [e6bb9ea85b] from /notebooks/stable-diffusion-webui/models/Stable-diffusion/sd_xl_base_1.0_0.9vae.safetensors
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://073526a1d3e027814c.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
Startup time: 35.8s (launcher: 5.6s, import torch: 5.6s, import gradio: 2.2s, setup paths: 3.7s, other imports: 3.7s, setup codeformer: 0.3s, list SD models: 0.3s, load scripts: 2.1s, initialize extra networks: 0.4s, create ui: 2.9s, gradio launch: 8.8s).
Creating model from config: /notebooks/stable-diffusion-webui/repositories/generative-models/configs/inference/sd_xl_base.yaml
Applying attention optimization: xformers... done.
Model loaded in 41.2s (load weights from disk: 27.4s, create model: 1.2s, apply weights to model: 9.0s, apply half(): 1.5s, move model to device: 1.4s, calculate empty prompt: 0.6s).
Loading refiner...
0%| | 0/18 [00:07<?, ?it/s]
*** Error completing request
*** Arguments: ('task(rblrcawgpzy547b)', 0, "(8k, best quality, masterpiece,ultra highres: 1.2) , (1 beautiful woman) is swimming crawl in a rapid current, heavy splashes, water splatters from the woman's hair,", 'watermark, signature, username, text, worst quality, low quality, normal quality, (missing hands, missing legs, missing finger), (extra hands, extra legs, extra finger), (bad hands, bad legs, bad finger), greyscale, monochrome, simple background, muti', [], <PIL.Image.Image image mode=RGBA size=768x1152 at 0x7F27C8626020>, None, None, None, None, None, None, 35, 18, 4, 0, 1, False, False, 1, 1, 7, 1.5, 0.5, 1094654407.0, -1.0, 0, 0, 0, False, 0, 1152, 768, 1, 0, 0, 32, 0, '', '', '', [], False, [], '', <gradio.routes.Request object at 0x7f27c85f4310>, 0, True, 'sd_xl_refiner_1.0_0.9vae.safetensors [8d0ce6c016]', 20, '<ul>\n<li><code>CFG Scale</code> should be 2 or lower.</li>\n</ul>\n', True, True, '', '', True, 50, True, 1, 0, False, 4, 0.5, 'Linear', 'None', '<p style="margin-bottom:0.75em">Recommended settings: Sampling Steps: 80-100, Sampler: Euler a, Denoising strength: 0.8</p>', 128, 8, ['left', 'right', 'up', 'down'], 1, 0.05, 128, 4, 0, ['left', 'right', 'up', 'down'], False, False, 'positive', 'comma', 0, False, False, '', '<p style="margin-bottom:0.75em">Will upscale the image by the selected scale factor; use width and height sliders to set tile size</p>', 64, 0, 2, 1, '', [], 0, '', [], 0, '', [], True, False, False, False, 0) {}
Traceback (most recent call last):
File "/notebooks/stable-diffusion-webui/modules/call_queue.py", line 58, in f
res = list(func(*args, **kwargs))
File "/notebooks/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/notebooks/stable-diffusion-webui/modules/img2img.py", line 232, in img2img
processed = process_images(p)
File "/notebooks/stable-diffusion-webui/modules/processing.py", line 677, in process_images
res = process_images_inner(p)
File "/notebooks/stable-diffusion-webui/modules/processing.py", line 794, in process_images_inner
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
File "/notebooks/stable-diffusion-webui/modules/processing.py", line 1381, in sample
samples = self.sampler.sample_img2img(self, self.init_latent, x, conditioning, unconditional_conditioning, image_conditioning=self.image_conditioning)
File "/notebooks/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 434, in sample_img2img
samples = self.launch_sampling(t_enc + 1, lambda: self.func(self.model_wrap_cfg, xi, extra_args=extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File "/notebooks/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 303, in launch_sampling
return func()
File "/notebooks/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 434, in <lambda>
samples = self.launch_sampling(t_enc + 1, lambda: self.func(self.model_wrap_cfg, xi, extra_args=extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/notebooks/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py", line 626, in sample_dpmpp_2m_sde
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/notebooks/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 215, in forward
devices.test_for_nans(x_out, "unet")
File "/notebooks/stable-diffusion-webui/modules/devices.py", line 155, in test_for_nans
raise NansException(message)
modules.devices.NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.最後のメッセージに従い、設定変更してみます。

変更後実施したところ、エラーは出ないが、進まないままで止まっています。引き続き調査します。
2023/08/07 追記
色々試してみましたが、再現性が確認できません。例えば以下では違いがでました。img2imgでrefinerを設定したものです。


これは確かに違います。
txt2img のステップが20で、
Percent of refiner steps from total sampling steps 20% とすると、
img2img のステップが 16となっていましたが、これで正しいのか、よく割りません。
起動メッセージを見ると、以下のメッセージがありました。
=================================================================================
You are running xformers 0.0.18.
The program is tested to work with xformers 0.0.20.
To reinstall the desired version, run with commandline flag --reinstall-xformers.
Use --skip-version-check commandline argument to disable this check.
=================================================================================そこでこうしてみます。
#(3) WebUI起動
!apt update
!apt -y install python3.10
!apt -y install libpython3.10-dev
!apt -y install build-essential
!curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
!python3.10 -m pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1+cu118 torchtext==0.15.1 torchdata==0.6.0 --extra-index-url https://download.pytorch.org/whl/cu118 -U
!python3.10 -m pip install xformers==0.0.18 triton==2.0.0 -U
!python3.10 -m pip install matplotlib -U
!python3.10 -m pip install ipython -U
from IPython import get_ipython
get_ipython().run_line_magic('matplotlib', 'inline')
%cd /notebooks/stable-diffusion-webui
!python3.10 launch.py --xformers --enable-insecure-extension-access --share --gradio-queue --reinstall-xformersこれで起動すると、上のメッセージは出なくなりました。
そこで画像を生成(refinerなし)すると、以下のメッセージが出ました。
=========================================================================================
A tensor with all NaNs was produced in VAE.
Web UI will now convert VAE into 32-bit float and retry.
To disable this behavior, disable the 'Automaticlly revert VAE to 32-bit floats' setting.
To always start with 32-bit VAE, use --no-half-vae commandline flag.
=========================================================================================そこでこのパラメータも加えてみます。
その結果、メッセージが出なくなりましたが、動作が安定しないのは変わらずでした。
ここまで得た知見は以下です。
txt2imgではrefinerは使わない
出力結果を img2imgに送ってから、refiner で生成する。sampling stepを小さく(10くらいとか)する。
こうすると生成されることがありますが、生成途中で終わってしまうこともよくあります。
PaperspaceのFreeのMachineとしては、メモリは多いほうなので、今のところはどうしようもない感じです。もうちょっと軽く動かせるようになるまで様子を見ます。




正直なところ refineされているのか、よくわかりません。この辺で止めておきましょう。
2023/8/10 追記
RefinerのExtensionがUpdateされていたので、適用し、再び txt2imgで生成してみます。

Refinerなしの結果

Refinerありの結果

よく見ると違う程度で、Refineされているのか、よくわかりません。
続けて生成しようとすると、止まっていました。

1回は生成できそうなので、進んではいます。
もうちょっと情報収集してみます。
2023/08/11 追記
refinerを使わず、baseのみだと、繰り返し生成しても落ちずに生成できました。


と思いましたが、5回くらい繰り返し生成していたら、動かなくなりました。16GiB GPUだと厳しいのかもしれません。
2023-08-13 システム障害メモ
本日アクセスすると、マシン起動した後、進みません。
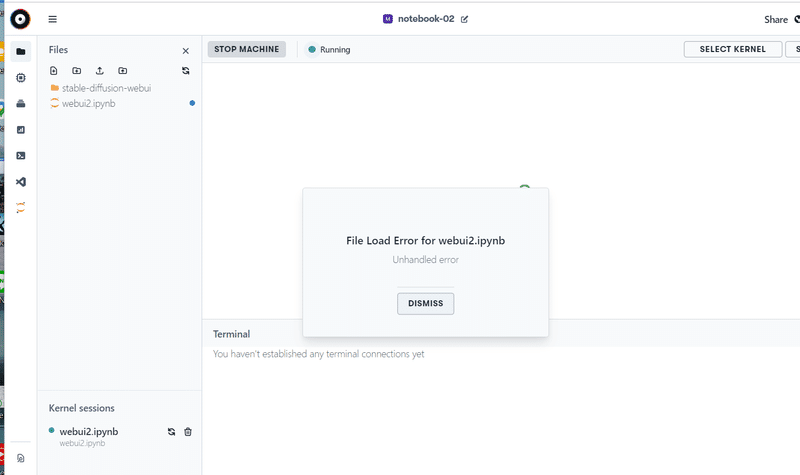
エラーの告知が出ていました。

これはしばらく待つしかなさそうです。
その後、1時間くらい後に見たら復旧していました。

2023-08-20 システム障害メモ
また障害が発生していました。先週に続いてなので、多いですね。

アクセスすると、 OUT OF CAPACITY となっています。

しばらく待ってみます。
2023-08-21 22時の状況は以下です。概ね復旧したようです。

ただ、Freeのマシンはまだ使えなさそうです。待ちます。

この記事が気に入ったらサポートをしてみませんか?