求人広告ネットワークサービス「求人Hub」のバッチ処理のしくみ
はじめまして、求人Hubでバックエンドエンジニアをしている高井です。
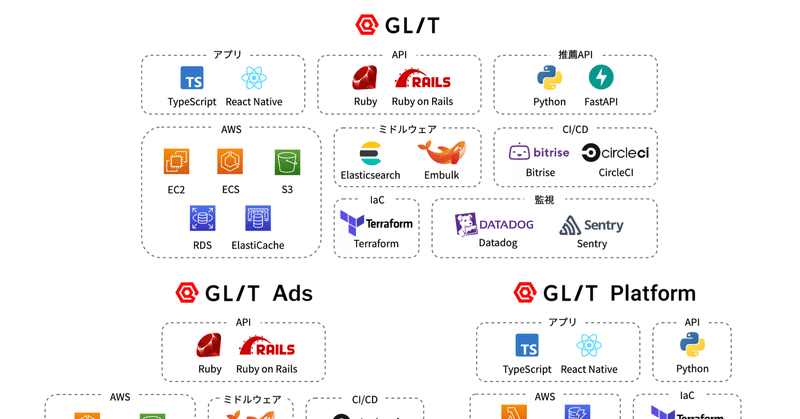
本記事ではCaratが運営する求人広告ネットワークサービス「求人Hub」のバッチ処理について解説します。
求人Hubとは「適切な求人を必要とする求職者に自然に届ける」をビジョンとし、複数の求人出稿企業の求人データを適切に変換し、それらを複数の求人掲載企業に届け、発生した応募データを出稿企業に移送するためのプロダクトです。
主な利用技術はRuby on Rails, AWS, Terraformになります。