
【次世代高速RDB】劔"Tsurugi"におけるバッチ処理(後編)

前編はコチラ。
前回は、Tsurugiの最大の特長の一つであるバッチ処理について、原価計算の実際のバッチ処理のベンチマークを参照しました。
結果としては、バッチ処理はほぼ劣化がなく、オンライン処理については105-120%に収まっています。
今回は「なぜそのようなことが可能か」ということを、できるだけ簡単に説明します。
なぜ、バッチ処理とオンライン処理が整合性をとって、同時実行することが可能なのか
従来のRDBであれば、通常はバッチ処理の対象に明示・黙示でlockをとり、上書きができないように制御してから、バッチ処理を行います。そのあとでlockの開放を行い、待ちになっているオンライン処理を行います。
結果として順序実行になり、オンライン処理側から見ると「DBが黙っているように見える」ということになります。現実の運用としては、オンライン処理を止めるか制限をかけ、バッチ処理を隙間に流すが、またはオンライン処理が走らない夜間に重たいバッチ処理を行う、ということになります。
今回はなぜ、Tsurugiが従来のRDBと異なり「バッチ処理とオンライン処理が整合性をとって、同時実行することが可能なのか?」という仕組みを説明します。
端的に言ってしまえば、この差は利用している技術の違いです。
従来のRDBはlock制御とsingle versionによる並行性制御ですが、これに対してTsurugiはtimestampベースでのMVCCになります。
MVCC
従来のRDBは、CPU・コアは少な目、かつメモリが貴重、というアーキテクチャを前提にした技術です。データは当然フットプリントが小さいほど有利なので、レコードの管理はsingle versionになります。
対してTsurugiは、メニーコア・メモリーベースの現代的な環境を前提に、MVCCを採用しています。
MVCCはMulti Version Concurrency Controlの略で、複数のversioningを利用し、トランザクションの一貫性=serializabilityを保ちながら、トランザクションの並行性制御の許容度を高め、スループットを上げる技術です。一つのレコードに対して複数のversionを並行利用することができるため、単一のデータに対して、同時に複数の書き込み・読み込みを行うことできます。
複数のversionを同時に扱うので、CPU/コア数は多いほど有利ですし、またデータサイズを上がるためメモリも大容量である方がパフォーマンスは上がります。
Timestampベース
従来のRDBは、ベースがsingle versionであるため、レコードの管理には排他制御を行う必要があります。通常、排他制御には簡易かつ動作も軽量に収めることができるlockベースでの手法を利用しています。
対して、Tsurugiは複数のversionを同時に扱うため、特段、排他制御の仕組みを利用するはありません。むしろ、逆にlockの待ち合わせの時間コストの方が高くつきます。一般にMVCCであれば、排他制御のlockよりは、各トランザクションのtimestampを利用して、同時実行時の論理的整合性を計算するという手法の方が有利です。Tsurugiも同様の手法を利用しています。
実際に前述のバッチ処理の例で見てみましょう
単純化するために、木構造を単純なものにして、更新処理を二つに絞ってみます。
▽製品Aが原料Bを利用するユースケース
・利用数は品目構成マスタに登録(利用数を1→2にオンラインで変更)
・Bの原価は原価マスタに登録(原価を100→200にオンラインで変更)
・Aの製造原価をマスタから結合処理をして集計する(バッチ)
◆一般的なsingle versionの場合

製造原価を計算中は、各レコードのversion 0を利用し、製品Aのマスタから、Bの使用量を取得し、またBでの原価を取得した上で、製造原価を計算します。
この間、各マスタはロックされ更新処理は待たされます。version1に書き込めるのはバッチ1の終了後です。仮に、更新後の各マスタを使って、再び製造原価を計算する場合(version2)は、バッチ1終了→オンライン処理終了→バッチの再投入、という順序投入になります。
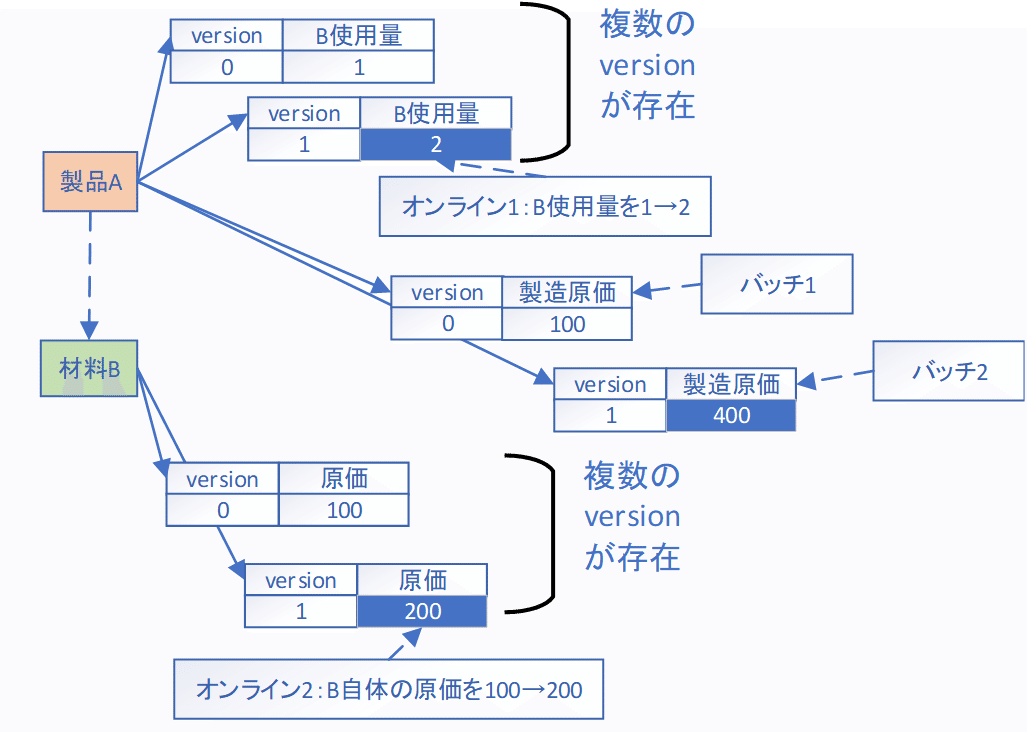
Tsurugiの場合は、マスタの状態を同時に複数持てるため、製造原価を計算中も、各マスタを更新処理できます。
バッチ1が各レコードのversion 0を利用し製造原価を計算している最中に、各マスタへの書き込みを行い、version1を生成します。また、再び製造原価を計算する場合(version2)は、バッチ1終了を待つ必要はありません。
各マスタが更新され次第、新しいversionを利用して計算を開始することができます。各versionの読み込み・書き込みの辻褄合わせはTsurugi側で行います。(たとえば、必ずversion0の後ろにversion1が追記されるような保証等)
上記のような仕組み・手法を利用することで、バッチ処理とオンライン処理の同時処理を可能にしています。
※※※お知らせ※※※
次世代高速RDB 劔"Tsurugi" のオープンソース版のリリース日が、
2023年10月5日に決定しました!
また、日経BP社より発売される 劔"Tsurugi" 解説本の発売日も10月5日に決定しました!
600Pにわたり、劔"Tsurugi"の利用法、バッチ処理の実際から始まり、
劔"Tsurugi"のインターフェースのすべて、内部構造や実装アルゴリズムの詳細まで解説しています。
また、東京、札幌、福岡で、OSS版リリース記念イベントの開催も決定しました!
詳しくは、劔"Tsurugi"コミュニティサイト をご覧ください。