
Llama 3をセルフホスティング

Meta社が開発した Llama3を、安価で使いやすい AMD CPU とマザーボード パッケージ、および 10 年前の Nvidia Titan X カードで実行できたよ!という記事があったのでメモ。機材が余ったら実験したい!いや、探せばあるけど今ちょっと(笑
Llamaをホスティングすると?
実際にお試ししたレイヴンズクロフト博士によると
「自社ホストの Llama 3 インスタンスを使い始めたばかりですが、これまでのところ、多くの分野で GPT-4 と同等の能力があることがわかりました。」
とあり、チームなどで無料でバンバン使いたい場合とかローカルにたてるのは悪くない選択肢になるかもです。
PROS/CONSは以下
利点:
価格 (無料)
プライバシー ローカル実行なので、情報漏洩の心配なし
炭素排出量(エコである)使わなくなったRTX3060などを再利用できます
欠点:
マルチモーダル非対応
トレーニングの透明性
Llama 3 のセットアップ
Ubuntuの場合
まず docker をインストールする必要があります。最新かつ最高のパッケージをインストールするDocker 自体のガイドを使用することをお勧めします。次に、このガイドに従って nvidia ランタイムをインストールします。次に、以下のチェック手順を使用して、すべてがセットアップされていることを確認します。
自分の場合↑のインストールが以前やったときには上手く以下なかったので諦めました
Docker と Nvidia のセットアップの確認
docker run --rm --runtime =nvidia --gpus all ubuntu nvidia-smi
Ollamaのインストール
docker-compose.yml.
version: "3.0"
services:
ui:
image: ghcr.io/open-webui/open-webui:main
restart: always
ports:
- 3011:8080
volumes:
- ./open-webui:/app/backend/data
environment:
# - "ENABLE_SIGNUP=false"
- "OLLAMA_BASE_URL=http://ollama:11434"
ollama:
image: ollama/ollama
restart: always
ports:
- 11434:11434
volumes:
- ./ollama:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]Ollamaを実行
docker-compose exec ollama ollama run llama3:8b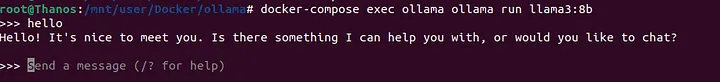
Turn on the Web UI
次に、Web UI を起動します。 を実行しますdocker-compose up -d ui。次に、ブラウザを開いて http://localhost:3011/ にアクセスし、Web UI を表示します。アカウントを登録してログインする必要があります。その後、次のようにモデルを操作できるようになります。

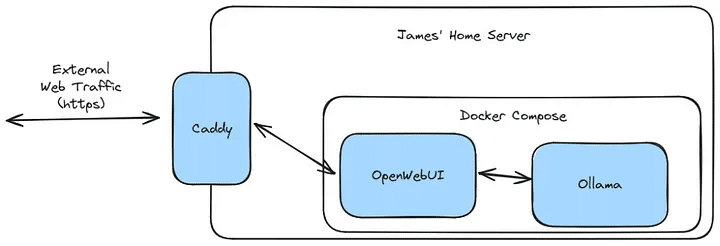
(オプション)外部アクセスを構成する
外部からモデルとチャットできるようにしたい場合は、サーバーへのリバース プロキシを設定することをお勧めします。セルフ ホスティングが初めてで、その方法がわからない場合は、Tailscaleを使用して VPN を構築する方が安全です。VPN を使用すると、システムが一般公開されたりハッカーに公開されたりするリスクを冒すことなく、自宅のネットワークに安全に接続できます。
この記事が気に入ったらサポートをしてみませんか?